|
Опрос
|
реклама
Быстрый переход
Стартап выходцев из «Яндекса» Nebius ворвался на 16-е место мощнейших суперкомпьютеров мира — «Яндекс» и «Сбер» остались далеко позади
16.11.2023 [12:33],
Владимир Мироненко
Компания Nebius N.V. со штаб-квартирой в Нидерландах, основанная бывшими сотрудниками «Яндекса», дебютировала в мировом рейтинге суперкомпьютеров TOP500. Её система ISEG заняла сразу 16-ю строку в списке, оставив позади системы «Яндекса» и «Сбера». 
Источник изображения: Pixabay Проект Nebius базируется в Израиле, а руководит им Роман Чернин, ранее возглавлявший в «Яндексе» подразделение геосервисов. «Как мы туда попали [в TOP500]? Наша команда разработчиков с большим энтузиазмом отнеслась к тестированию той части нашей новой облачной платформы, которая на тот момент была свободна от рабочей нагрузки клиентов, — сообщила в своём аккаунте LinkedIn отделившаяся от «Яндекса» Nebius. — Для этой цели они использовали бенчмарк из TOP500. Теперь вы можете использовать часть суперкомпьютера Nebius AI для своих проектов в области искусственного интеллекта». В том, что запустившийся в начале года стартап Nebius уже создал свой суперкомпьютер, причём один из самых производительных в мире, нет ничего удивительного. Например, у «Сбера» в своё время на создание суперкомпьютера ушло всего три-четыре месяца. Как отметили в «Яндексе», при строительстве суперкомпьютера ISEG интеллектуальная собственность и технологии «Яндекса» не использовались, потому как они там не требуются. Тестирование суперкомпьютера для TOP500 проводилось на «голом железе», но для реального применения потребуется уже специальное ПО, и Nebius может использовать как собственные разработки, так и решения с открытым кодом. «Система Nebius потенциально имела шансы появиться в России, это потерянная возможность», — прокомментировал вхождение в TOP500 стартапа Nebius главный научный сотрудник, директор Исследовательского центра мультипроцессорных систем Института программных систем им. А. К. Айламазяна Российской академии наук, член-корреспондент РАН, сокоординатор Национальной суперкомпьютерной технологической платформы Сергей Абрамов. Два года назад Абрамов оценивал стоимость создания суперкомпьютера «Яндекса «Червоненкис» в $7–10 млн. С учётом использования параллельного импорта в условиях санкций на создание подобного суперкомпьютера сейчас потребуется $10,5–20 млн. Учёный отметил, что для создания «серьёзных систем» необходима тесная кооперация с мировыми производителями процессоров, ускорителей, интерконнекта, о чём в условиях санкций говорить не приходится. В новом рейтинге TOP500 всего семь суперкомпьютеров из России. Все они утратили прежние позиции. Наиболее мощный российский суперкомпьютер «Червоненкис», созданный «Яндексом» в 2021 году, опустился с 27-го на 36-е место. В свою очередь «Галушкин» опустился с 46-го на 58-е, а «Ляпунов» — с 52-го на 64-е. Это тоже системы «Яндекса». На 67-е место с 55-го упал суперкомпьютер «Кристофари Нео», а на 119-е место переместился с 96-го «Кристофари» — обе системы принадлежат «Сберу». На 370-е место с 329-го переместился суперкомпьютер «Ломоносов-2» производства компании «Т-Платформы», установленный в Научно-исследовательском вычислительном центре МГУ, и на 433-м месте оказался суперкомпьютер MTS GROM, установленный в CloudMTS, ранее занимавший 391-ю позицию. Источник Forbes назвал утрату российскими компаниями прежних позиций в TOP500 «естественным результатом санкций». С уходом американских корпораций с российского рынка у оставшихся в стране компаний нет «объективных технологических возможностей выступать с какими-то новыми результатами» в рейтинге TOP500, считает собеседник Forbes. В «Яндексе» объяснили изменение места в рейтинге тем, что организаторы использовали старые данные. «Компания использует все свои суперкомпьютеры для различных сервисов, в том числе для обучения модели YandexGPT, — сообщила «Яндекс» ресурсу Forbes . — Изменение места в рейтинге связано с тем, что мы не проводили новые замеры для TOP500, так как для проведения тестов необходимо остановить все рабочие процессы обучения моделей на суперкомпьютерах. Поэтому организаторы использовали наши старые данные от ноября 2021 года». Aurora на базе Intel стал вторым мощнейшим суперкомпьютером в мире — лидером остался вдвое более мощный Frontier на AMD
14.11.2023 [16:19],
Павел Котов
Проект Top500 обновил рейтинг самых быстрых суперкомпьютеров в мире. Первое место сохранила система Frontier на базе процессоров и ускорителей AMD с производительностью 1,194 Эфлопс. А вот второе место претерпело изменения. Здесь, уступив лидеру более чем вдвое, оказался основанный на чипах Intel суперкомпьютер Aurora Аргоннской национальной лаборатории (США) — он показал 585,34 Пфлопс. 
Источник изображения: intel.com Intel осуществила мощную атаку на рейтинг суперкомпьютеров, добавив в список 20 новых систем на чипах Sapphire Rapids. В то же время места в Top500 активно занимают системы на AMD EPYC — на этих процессорах работают уже 140 суперкомпьютеров в списке, а за год их число выросло на 39 %. Intel и Аргоннская лаборатория продолжают работу по расширению Aurora: на момент выхода последней версии рейтинга суперкомпьютер составляли 10 624 процессора и 31 874 графических ускорителя Intel, обеспечивших производительность в 585,34 Пфлопс при суммарной мощности 24,69 МВт. Для сравнения, лидер рейтинга в лице Frontier на чипах AMD имеет производительность в 1,194 Эфлопс, более чем двукратно опережая систему на втором месте и потребляя при этом относительно скромные 22,70 МВт энергии. Из-за этого Aurora не попал в рейтинг самых энергоэффективных суперкомпьютеров Green500, а Frontier удерживает здесь восьмое место. Ожидается, что в конечном итоге Aurora выйдет на производительность в 2 Эфлопс — её обеспечат 21 248 процессоров Xeon Max и 63 744 графических ускорителя Max Ponte Vecchio в 166 стойках и 10 624 вычислительных модулях. Это будет самый крупный массив графических процессоров в мире. Суперкомпьютер работает на узлах HPE Cray EX с сетевыми соединениями HPE Slingshot-11. Тем временем AMD занимается строительством суперкомпьютера El Capitan в Ливерморской национальной лаборатории имени Лоуренса (США), который, как ожидается, превысит показатель в 2 Эфлопс, и, возможно, Aurora уже не поднимется до первого места. 
Источник изображения: olcf.ornl.gov Впервые о суперкомпьютере Aurora было объявлено в 2015 году. Его строительство планировали завершить в 2018 году — тогда ожидалось, что он будет работать на процессорах Knights Hill, выход которых впоследствии был отменён. В 2019 году был анонсирован обновлённый проект Aurora с производительностью около 1 Эфлопс, который намеревались завершить к 2021 году. Но в конце 2021 года проектную производительность повысили до 2 Эфлопс, а сроки продлили до 2024 года. Третьим в рейтинге оказался новый суперкомпьютер Eagle (561,20 Пфлопс) от Microsoft, развёрнутый в облаке Azure — облачный суперкомпьютер обогнал прежнего серебряного лауреата в лице японского суперкомпьютера Fugaku (442,01 Пфлопс), который опустился на четвёртое место. А замкнула пятёрку финская система LUMI с 379,70 Пфлопс. Китай намерен нарастить свои вычислительные мощности на 52 % за два года, несмотря на санкции
09.10.2023 [09:49],
Алексей Разин
Введённые год назад ограничения на поставку в Китай ускорителей вычислений американского происхождения были направлены на сдерживание технологического развития страны. Власти КНР не стесняются даже в сложных условиях ставить перед национальной вычислительной инфраструктурой амбициозные цели. В технологическом секторе Китай рассчитывает увеличить вычислительные мощности к 2025 году более чем на 50 %. 
Источник изображения: NVIDIA Об этом стало известно с подачи Bloomberg — агентство ссылается на совместное заявление ряда китайских ведомств и Министерства промышленности и информатизации КНР. В промышленной сфере совокупную вычислительную мощностью эксплуатируемых в стране серверных систем планируется увеличить с нынешних 197 до 300 экзафлопс или примерно на 52 % уже к 2025 году. К концу текущего года мощность должна составить уже 220 Эфлопс. За два ближайших года в Китае также появится 20 дополнительных центров обработки данных новейшего поколения. Попутно будут развиваться оптические сети передачи информации и системы хранения данных, по замыслу китайских чиновников, среднее время задержки при передаче информации в критически важных системах не должно превышать 5 мс. За счёт этого предполагается придать дополнительный импульс развитию производства, образования, транспорта, здравоохранения, энергетики и финансовой сферы. Отдельное внимание будет уделяться развитию отечественного программного обеспечения, повышающего надёжность функционирования всей этой инфраструктуры. Власти КНР подчеркнули, что стабильность поставок компонентов будет существенно влиять на успех в реализации данной программы. В контексте ожидания новых санкций со стороны США это звучит тем более актуально. Год назад США ввели экспортные ограничения на поставку в Китай как определённых видов оборудования для производства чипов, так и компонентов для центров обработки данных, обладающих определённым уровнем быстродействия. По всей видимости, этой осенью перечень ограничений будет расширен, что создаст дополнительные сложности для китайской стороны в реализации своих инициатив. TSMC активно наращивает выпуск гигантских чипов для суперкомпьютера Tesla Dojo
27.09.2023 [11:16],
Алексей Разин
В конце августа прошлого года компания Tesla рассказала об архитектуре своей суперкомпьютерной системы Dojo, которая будет применяться для работы с фирменными системами искусственного интеллекта, ориентированными на машинное зрение и автоматическое управление транспортом. Как отмечают тайваньские источники, компоненты для этого суперкомпьютера Tesla заказывает у TSMC весьма активно. 
Источник изображений: Tesla Основной компонент, на котором строится суперкомпьютер Tesla Dojo — это чип D1 собственной разработки, который представляет собой «систему-на-пластине», то есть занимает целую 300-мм кремниевую пластину, на которой размещается 25 ускорителей и другие функциональные элементы. Его компания TSMC производит по 7-нм технологии и упаковывает особым образом, что уже стало нормой для ускорителей вычислений. В этом году Tesla собирается закупить у TSMC около 5000 таких чипов, в следующем году она намерена удвоить количество до 10 000 чипов, а также продолжить наращивание закупок уже в 2025 году.  Для TSMC увеличение объёмов заказов на выпуск 7-нм продукции является положительной тенденцией, поскольку на фоне снижения спроса на компоненты для смартфонов данное направление деятельности страдало от снижения уровня загрузки производственных линий. По крайней мере, в следующем году за счёт заказов Tesla и прочих клиентов степень загрузки линий на 7-нм направлении вырастет до оптимальных величин. К концу 2024 года Tesla намеревается довести уровень производительности своего суперкомпьютера Dojo до 100 эксафлопс, поэтому процесс масштабирования системы продолжается. Tesla запустила суперкомпьютер на 10 тыс. ускорителей NVIDIA H100 — на нём будут учить автопилот
30.08.2023 [21:06],
Николай Хижняк
Компания Tesla сообщила о запуске на этой неделе нового суперкомпьютера для решения ресурсоемких задач, связанных с ИИ. В его основе используются 10 тыс. специализированных графических ускорителей NVIDIA H100. 
Источник изображений: HPC Wire Отмечается, что система обеспечивает пиковую производительность в 340 Пфлопс в операциях FP64 для технических вычислений и 39,58 Эфлопс в операциях INT8 для задач ИИ. Таким образом, по производительности FP64 кластер превосходит суперкомпьютер Leonardo, который располагается на четвёртой позиции в нынешнем мировом рейтинге суперкомпьютеров Тор500 с показателем 304 Пфлопс. Новый суперкомпьютер Tesla с ускорителями NVIDIA H100 является одной из самых мощных платформ в мире. На формирование кластера потрачено около $300 млн. Он подходит не только для обработки алгоритмов ИИ, но и для НРС-задач. Благодаря данной системе компания рассчитывает значительно расширить ресурсы для создания полноценного автопилота.  На фоне сформировавшегося дефицита ускорителей NVIDIA H100 компания хочет диверсифицировать вычислительные мощности. Для этого Tesla ведёт разработку своего собственного проприетарного суперкомпьютера Dojo. В проект планируется инвестировать $1 млрд. Уже к октябрю следующего года Tesla рассчитывает преодолеть барьер в 100 Эфлопс производительности, что более чем в 60 раз мощнее самого производительного суперкомпьютера в мире на сегодняшний день. Помимо простого аппаратного обеспечения, новая вычислительная инфраструктура предоставит Tesla преимущество в обработке огромных наборов данных, что имеет решающее значение для реальных сценариев обучения ИИ. Анонсирован первый в мире ИИ-суперкомпьютер на 4 Эфлопс — 54 млн ИИ-ядер Cerebras и 72 тыс. ядер AMD Zen 3
21.07.2023 [16:54],
Павел Котов
Один из ведущих разработчиков чипов для работы с системами искусственного интеллекта Cerebras Systems совместно с облачным провайдером G42 представил проект по созданию девяти мощных суперкомпьютеров, заточенных под задачи ИИ. Первой из них станет система CG-1 (Condor Galaxy 1), которая первой в мире достигнет производительности в 4 Эфлопс в задачах искусственного интеллекта. Случится это уже к концу текущего года. 
Источник изображений: cerebras.net Суперкомпьютер Condor Galaxy 1 отличают следующие технические характеристики:
Компания Cerebras Systems известна благодаря своей платформе CS-2 на базе гигантских чипов Wafer-Scale Engine 2 (WSE-2) с 2,6 трлн транзисторов — такой чип производится из целой кремниевой пластины и содержит 850 тыс. тензорных ИИ-ядер. На первом этапе Condor Galaxy 1 получит 32 системы Cerebras CS-2, которые обеспечат ему производительность в 2 Эфлопс, а к концу текущего года их число удвоится, как и производительность суперкомпьютера, которая вырастет до 4 Эфлопс (второй этап). 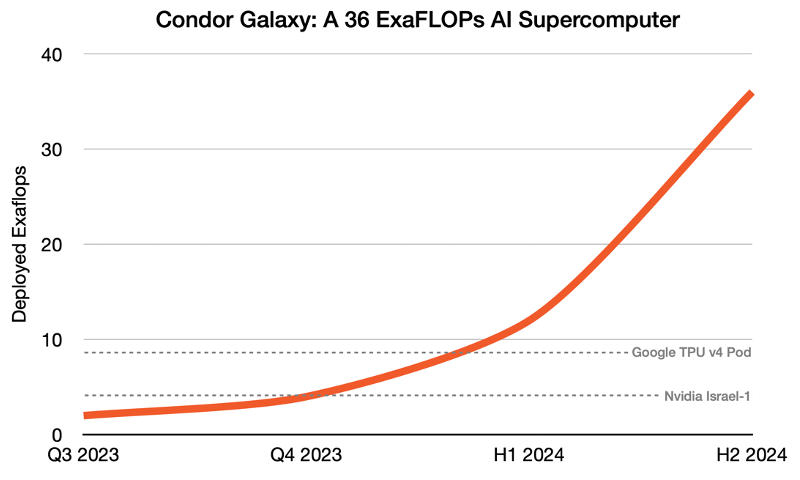 На этом в Cerebras Systems решили не останавливаться: далее запланировано создание суперкомпьютеров CG-2 и CG-3, которые на третьем этапе в первой половине 2024 года будут объединены в первую распределенную сеть суперкомпьютеров на базе 192 систем CS-2 общей производительностью 12 Эфлопс. Наконец, на четвёртом этапе к этой сети подключат ещё шесть суперкомпьютеров, обеспечив таким образом совместную работу 576 систем CS-2 и 36 Эфлопс. В компании подчеркнули, что кластеры Wafer-Scale изначально предназначены для работы в качестве единого ускорителя. Единый блок памяти CG-1 объёмом 82 Тбайт позволяет размещать даже самые большие ИИ-модели непосредственно в памяти без необходимости в дополнительных программных решениях. Иными словами, в инфраструктуре Cerebras модели с 1 млрд и 100 млрд параметров работают на базе единого кода с поддержкой длинных последовательностей в 50 000 токенов. 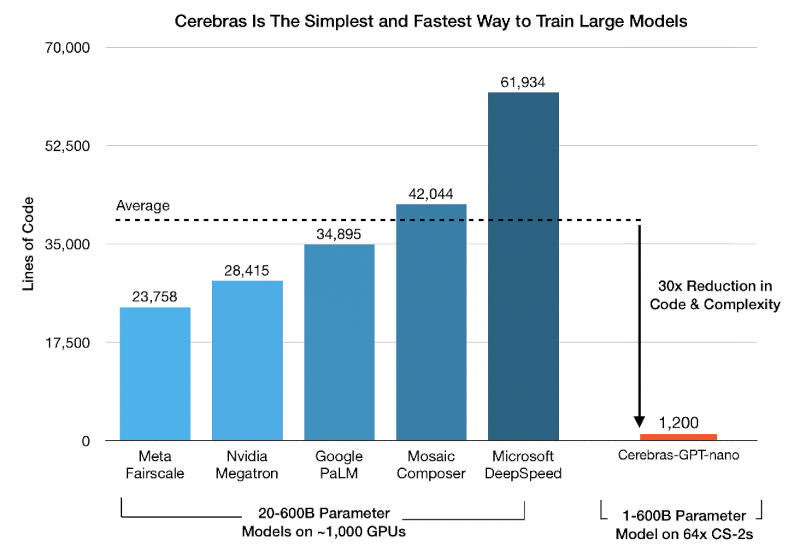 В результате стандартная реализация GPT на CG-1 потребует всего 1200 строк кода — в 30 раз меньше существующих аналогов. А масштабирование системы производится при помощи выделения кратного объёма ресурсов в простой линейной зависимости. То есть модель с 40 млрд параметров обучается в 40 раз дольше модели с 1 млрд параметров при тех же ресурсах — или за то же время, если увеличить объёмы ресурсов в 40 раз. Tesla запустила производство суперкомпьютеров Dojo и за 15 месяцев хочет достичь производительности в 100 Эфлопс
20.07.2023 [14:54],
Павел Котов
Tesla сообщила о запуске производства суперкомпьютера собственной разработки Dojo, предназначенного для обучения систем автопилота. Компания собирается потратить на проект $1 млрд. Компания рассчитывает уже к октябрю следующего года преодолеть барьер в 100 Эфлопс производительности — это более чем в 60 раз мощнее самого мощного суперкомпьютера на сегодняшний день. 
Источник изображения: Tesla В финансовом отчёте Tesla по результатам II квартала 2023 года говорится: «Для решения проблемы автономных транспортных средств необходимы четыре основных технологических столпа: чрезвычайно большой набор данных из реального мира, обучение нейросети, аппаратное и программное обеспечение для транспортных средств. Мы разрабатываем каждый из этих столпов силами компании. В этом месяце мы сделаем шаг к более быстрому и дешёвому обучению нейросети с запуском производства нашего обучающего компьютера Dojo». В распоряжении компании уже есть суперкомпьютер на базе ускорителей NVIDIA, один из самых больших в мире, но в суперкомпьютере Dojo используются чипы, разработанные инженерами Tesla. Проект был анонсирован в 2019 году — тогда же глава компании сообщил, как будет назваться система. В 2021 году Илон Маск (Elon Musk) рассказал, что работа над суперкомпьютером идёт полным ходом, а год спустя раскрыл технические характеристики Dojo: основу платформы составляют «системы-на-пластине» (System-On-Wafer) — чип представляет собой целую 300-мм кремниевую пластину. Сама Tesla называет их Training Tile. Каждая пластина включает 25 ускорителей D1, и потребляет 15 кВт энергии. 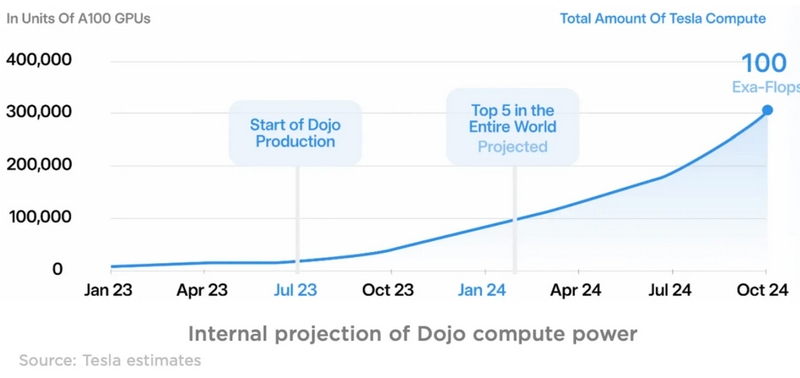 Одна стойка с шестью такими пластинами будет обеспечивать производительность в 100 Пфлопс, и получается, что всего десяток стоек обеспечит производительность в 1 Эфлопс, то есть 1 квинтильон операций на числах с плавающей запятой в секунду. Tesla планирует к октябрю 2024 года достичь производительности в 100 Эфлопс для всех своих систем вместе взятых. Для сравнения, самый мощный суперкомпьютер на текущий момент — Frontier — обладает пиковой вычислительной мощностью в 1,679 Эфлопс. «Наше стремление быть на острие разработки ИИ помогло открыть новую главу с началом производства обучающих компьютеров Dojo. Надеемся, что наши огромные потребности в обучении нейросетей будут удовлетворены оборудованием Dojo собственной разработки. Чем выше способность нейросети к обучению, тем больше возможностей для внедрения новых решений нашим подразделением Autopilot», — добавили в Tesla. Tesla в июле начнёт строить суперкомпьютер Dojo на собственных чипах — он станет одним из мощнейших в мире
26.06.2023 [18:19],
Сергей Сурабекянц
Компания Tesla недавно объявила о прогрессе в разработке специальной суперкомпьютерной платформы Tesla Dojo, построенной на чипах собственной разработки автопроизводителя. Производство суперкомпьютера начнётся в июле 2023 года, ожидается, что в 2024 году Dojo войдёт в пятёрку самых передовых вычислительных систем мира. 
Источник изображения: Tesla Создание собственного суперкомпьютера — это ещё один важный шаг Tesla в области ИИ. Хотя ускорители NVIDIA A100 и H100 доминируют в области ИИ на данном этапе, собственные чипы Tesla для обучения ИИ и логических выводов могут существенно снизить зависимость компании от традиционных производителей таких полупроводниковых компонентов. Старт разработке суперкомпьютера Dojo, предназначенного для машинного обучения ИИ, был дан на AI Day 2021. Dojo основан исключительно на разработанных Tesla чипах и инфраструктуре, а для обучения нейронной сети использует видеоданные внушительного парка автомобилей Tesla. Развитие машинного зрения Tesla имеет ключевое значение для технологии автономного вождения. Вычислительные мощности будущего суперкомпьютера также будут использованы для дальнейшего развития проекта человекообразного робота Tesla Optimus. В архитектуре Tesla Dojo применяются «системы-на-пластине» (System-On-Wafer), то есть чип представляет собой целую кремниевую пластину (Training Tile в терминологии Tesla). Каждая пластина вмещает 25 ускорителей D1 и 40 модулей ввода-вывода. На пластине также размещены подсистемы питания и охлаждения. Представители Tesla утверждают, что одна «система-на-пластине» заменяет шесть блоков графических процессоров и при этом обходится дешевле.  Хотя система Dojo может не принять окончательную форму до 2024 года, Илон Маск (Elon Musk) доволен работой своей команды ИИ, заявляя, что достижения Tesla в области искусственного интеллекта, как в программном, так и в аппаратном обеспечении, выходят далеко за рамки того, что некоторые эксперты даже осознавали. Программное обеспечение является ключом к автономному вождению, и Tesla уже использует большой суперкомпьютер с графическими процессорами NVIDIA для обработки данных системы автономного вождения FSD, один из самых мощных в мире суперкомпьютерных кластеров.  Главный инженер Tesla Тим Заман (Tim Zaman) сообщил общественности, что вычислительный кластер Tesla в настоящее время загружен на 99,7 %, причём 84 % машинного времени тратится на высокоприоритетные задачи. Компания остро нуждается в дополнительных вычислительных ресурсах, и суперкомпьютер Dojo сможет кардинально улучшить ситуацию. Миллионы квантовых операций в секунду: Microsoft построит квантовый суперкомпьютер в ближайшие 10 лет
22.06.2023 [10:59],
Павел Котов
Microsoft конкретизировала свои планы по созданию собственного квантового компьютера с использованием топологических кубитов — над этим решением компания работает уже несколько лет. Согласно дорожной карте, предстоит преодолеть ещё множество промежуточных этапов, но, как заявила вице-президент Microsoft по квантовым разработкам Криста Своре (Krysta Svore), создание суперкомпьютера, способного выполнять миллион квантовых операций в секунду, займёт менее десяти лет. 
Источник изображения: efes / pixabay.com В прошлом году Microsoft объявила о крупном прорыве, когда её разработчики нашли способ создавать кубиты на основе фермионов Майораны — они чрезвычайно стабильны, но и получать их тоже чрезвычайно сложно. Корпорация делала ставку на это направление с самого начала, и спустя год после первого ощутимого успеха инженеры Microsoft опубликовали статью в рецензируемом журнале, в которой заявили, что преодолели первый этап на пути к созданию квантового суперкомпьютера. Исследователи привели намного больше данных, чем год назад, когда впервые рассказали о своей работе. Сегодня в распоряжении Microsoft есть квантовые машины среднего масштаба — они пока недостаточно надёжны, чтобы сделать нечто практичное, поэтому на следующем этапе будет необходимо обеспечить точность вычислений. Исследователи планируют получить систему, способную выполнять миллион надёжных квантовых операций в секунду при одном отказе на триллион операций. Кубиты размером менее 10 мкм каждый получат аппаратную защиту. После этого будет проработан механизм их запутывания и управления. В работе компании поможет её новая платформа Azure Quantum Elements, которая ускорит научную работу за счёт объединения высокопроизводительных традиционных вычислений, алгоритмов искусственного интеллекта и квантовых вычислений. Новым вспомогательным инструментом для учёных и студентов также станет ИИ-модель Copilot для Azure Quantum, предназначенная для квантовых расчётов и симуляций. NVIDIA представила серийный суперкомпьютер для задач ИИ — 1 экзафлопс производительности и 144 Тбайт памяти
29.05.2023 [15:31],
Матвей Филькин
На открытии выставки Computex в Тайване главный исполнительный директор NVIDIA Corp. Дженсен Хуанг (Jensen Huang) сделал ряд программных анонсов, в том числе он раскрыл подробности о следующем суперкомпьютере компании DGX GH200. Ожидается, что он будет доступен уже в конце текущего года. 
Источник изображения: NVIDIA Множество представленных продуктов NVIDIA включает в себя новую систему быстрой разработки роботов Isaac AMR, сервис NVIDIA ACE, который позволит сделать неигровых персонажей (NPC) в играх умнее, а также рекламные услуги и сетевые технологии. Однако, самым крупным анонсом стал суперкомпьютер для работы с ИИ — DGX GH200, который поможет технологическим компаниям создавать преемников ChatGPT. NVIDIA утверждает, что разработала суперкомпьютер, который может встать в один ряд с самой мощной на данный момент вычислительной системой на планете. DGX GH200 использует новую платформу NVLink Switch System, позволяющую 256 суперчипам GH200 Grace Hopper работать как единый GPU (каждый из таких суперчипов объединяет 72-ядерный CPU Grace на базе Arm, GPU класса H100, 96 Гбайт HBM3 и 512 Гбайт LPDDR5X-памяти). Это, по словам NVIDIA, позволит DGX GH200 развить производительность в 1 экзафлоп и иметь 144 терабайта общей памяти. Компания утверждает, что это почти в 500 раз больше, чем в суперкомпьютерном решении прошлого поколения, DGX A100. Для сравнения, в последнем рейтинге суперкомпьютеров Top500 единственной известной экзафлопсной системой назван Frontier, который достиг производительности почти 1,2 экзафлопса в бенчмарке Linmark. Это более чем в два раза превышает пиковую производительность системы Fugaku из Японии, занявшей второе место. Крупные компании, занятые разработкой ИИ, уже проявили заинтересованность в DGX GH200. Google, Meta✴ и Microsoft должны стать одними из первых пользователей, которые получат доступ к суперкомпьютерам, чтобы проверить, как он справляется с нагрузками генеративного ИИ. NVIDIA утверждает, что суперкомпьютеры DGX GH200 станут серийным продуктом и будут доступны для заказчиков уже в конце 2023 года. Суперчипы GH200 Grace Hopper уже отправлены в серийное производство. Стоимость DGX GH200 для заказчиков названа не была, но можно предположить, что речь будет идти о восьмизначных суммах. Сам же суперкомпьютер при этом будет занимать 24 серверные стойки.  Шквал анонсов подчёркивает перерождение NVIDIA из простого производителя графических чипов в компанию, находящуюся в центре бума ИИ. На прошлой неделе Дженсен Хуанг дал ошеломляющий прогноз продаж на текущий квартал — почти на $4 млрд выше оценок аналитиков — благодаря спросу на чипы для центров обработки данных, выполняющие задачи ИИ. Это привело к рекордному росту акций и поставило NVIDIA на грань оценки в 1 триллион долларов — впервые в индустрии чипов.
Суперкомпьютер на одних лишь Arm-процессорах NVIDIA Grace попадёт в тройку самых энергоэффективных в мире
22.05.2023 [12:17],
Алексей Разин
Компания NVIDIA сделала себе имя в сегменте высокопроизводительных вычислений преимущественно за счёт ускорителей на базе графических процессоров. Это не мешает ей расширять ассортимент предложений для сегмента суперкомпьютеров за счёт центральных процессоров собственной разработки. Именно на их основе будет построен суперкомпьютер Isambard 3, который может войти в тройку самых энергоэффективных в мире. 
Источник изображения: NVIDIA Правда, как следует оговориться, выборка сделана среди суперкомпьютерных систем, не использующих ускорители вычислений на основе графических процессоров. По словам представителей NVIDIA, собираемый для Бристольского университета при участии Hewlett Packard Enterprise и других партнёров суперкомпьютер будет обходиться всего 270 кВт потребляемой мощности при пиковой производительности вычислений с точностью FP64 на уровне 2,7 Пфлопс. Это сделает его в шесть раз более эффективным по соотношению быстродействия и потребляемой мощности по сравнению с предшественником — Isambard 2. Подобное сочетание характеристик позволит Isambard 3 войти в тройку наиболее энергоэффективных суперкомпьютеров мира, не использующих специализированные ускорители. Система Isambard 3 будет введена в строй весной следующего года, и позволит учёным Бристольского университета в Великобритании проектировать сложные энергетические установки, анализировать данные метеорологических исследований и заниматься поиском лекарственных средств, которые помогут в борьбе с болезнью Паркинсона, остеопорозом и коронавирусом COVID-19. В основе суперкомпьютера будут лежать 384 центральных процессора NVIDIA Grace с Arm-совместимой архитектурой. Напомним, что данные чипы способны предложить до 144 ядер (на двух кристаллах). Google представила облачный ИИ-суперкомпьютер A3 — до 26 000 ускорителей NVIDIA H100 для всех желающих
11.05.2023 [21:37],
Сергей Сурабекянц
На конференции Google I/O компания Google анонсировала облачный ИИ-суперкомпьютер Compute Engine A3, который сможет предложить клиентам компании до 26 000 ускорителей вычислений NVIDIA H100. Это ещё одно доказательство того, насколько большое значение Google придаёт конкурентной битве с Microsoft за первенство в области ИИ. Что интересно, самый быстрый в мире на сегодняшний день общедоступный суперкомпьютер Frontier оснащён 37 000 ускорителями AMD Instinct 250X. 
Источник изображения: NVIDIA «Для наших клиентов мы можем предоставить суперкомпьютеры A3 до 26 000 GPU в одном кластере и работаем над созданием нескольких кластеров в крупнейших регионах», — заявила представитель Google, добавив, что «не все наши местоположения будут масштабироваться до такого большого размера». Таким образом любой облачный клиент Google может получить в своё распоряжение заточенный под ИИ суперкомпьютер с числом ускорителей вычислений до 26 000. Клиенты Google Cloud смогут тренировать и запускать приложения ИИ через виртуальные машины A3 и использовать службы разработки и управления ИИ Google, доступные через Vertex AI, Google Kubernetes Engine и Google Compute Engine. Виртуальные машины A3 основаны на чипах Intel Xeon четвёртого поколения (Sapphire Rapids), которые работают в связке с ускорителями H100. Пока не ясно, будут ли виртуальные CPU поддерживать ускорители логических выводов, встроенные в чипы Sapphire Rapids. Google утверждает, что A3 обеспечивает производительность для задач ИИ до 26 экзафлопс, что значительно сокращает время и затраты на обучение ИИ. Необходимо учитывать, что компания указывает производительность вычислений в специализированном формате для обучения ИИ TF32 Tensor Core с одинарной точностью, что демонстрирует производительность примерно в 30 раз выше, чем математика с плавающей запятой с двойной точностью FP64, которая используется в большинстве классических приложений. Количество графических процессоров стало важной визитной карточкой облачных провайдеров для продвижения своих услуг в сфере ИИ. Суперкомпьютер Microsoft в Azure для ИИ, созданный в сотрудничестве с OpenAI, имеет 285 000 ядер CPU и 10 000 ускорителей на GPU. Microsoft также анонсировала свой суперкомпьютер для ИИ следующего поколения с ещё большим количеством графических процессоров. Облачный сервис Oracle предоставляет облачный доступ к кластерам, насчитывающим до 512 GPU и работает над новой технологией для повышения скорости обмена данными между ними. 
Источник изображения: unsplash.com Хотя Google продолжает рекламировать собственные чипы для искусственного интеллекта TPU v4, используемые для запуска внутренних приложений ИИ, таких как Google Bard, ускорители на GPU от NVIDIA стали де-факто стандартом для построения инфраструктуры ИИ. Инструментарий параллельного программирования NVIDIA CUDA обеспечивает самые быстрые результаты благодаря специализированным ядрам ИИ и графическим ядрам H100. Облачные провайдеры осознали, что универсального подхода недостаточно — требуется инфраструктура, специально созданная для обучения ИИ. Поэтому в настоящее время происходит массовое развёртывание систем на базе ускорителей H100, а NVIDIA в марте запустила собственный облачный сервис DGX, стоимость аренды которого значительно выше по сравнению с арендой систем на ускорителях A100 предыдущего поколения. Утверждается, что H100 на 30 % экономичнее и в 3 раза быстрее, чем NVIDIA A100, например, в обучении большой языковой модели MosaicGPT с семью миллиардами параметров. A3 является первым облачным ИИ-суперкомпьютером, в котором GPU подключены через инфраструктурный процессор (IPU) Mount Evans, разработанный совместно Google и Intel. «В A3 используются IPU со скоростью 200 Гбит/с, передача данных от одного GPU к другому осуществляется в обход CPU через отдельные интерфейсы. Это позволяет увеличить пропускную способность сети до 10 раз по сравнению с нашими виртуальными машинами A2, с низкими задержками и высокой стабильностью пропускной способности», — утверждают представители Google. 
Источник изображения: Pixabay Суперкомпьютер A3 построен на основе сетевой структуры Jupiter, которая соединяет географически разнесённые кластеры CPU через оптоволоконные каналы связи. Одна виртуальная машина A3 включает восемь ускорителей H100, соединённых между собой с помощью запатентованной технологии NVIDIA. Ускорители будут подключены через коммутаторы NVSwitch и использовать NVLink со скоростью обмена данными до 3,6 Тбит/с. Аналогичную скорость скоро готова будет предложить Microsoft на своём ИИ-суперкомпьютере, построенном на тех же технологиях NVIDIA. При этом суперкомпьютер от Microsoft может похвастаться сетевыми возможностями от производителя чипов Quantum-2 со скоростью до 400 Гбит/с. Количество ускорителей вычислений H100 в своём ИИ-суперкомпьютере следующего поколения Microsoft пока держит в секрете. Но вряд ли оно окажется меньше, чем у главного конкурента. Китай создаст суперкомпьютерный интернет для решения задач от ИИ до космоса
20.04.2023 [13:47],
Геннадий Детинич
На днях эксперты и представители китайских университетов, исследовательских институтов и компаний, занимающихся передовыми вычислениями, приняли участие в конференции в Тяньцзине, посвящённой созданию в Китае «суперкомпьютерного интернета». Сеть будет объединять свыше 15 суперкомпьютерных платформ, обеспечивая одновременный доступ к нескольким из них через «браузер». Ресурс будет доступен для решения отраслевых задач от фармакологии до космоса. 
Источник изображения: Pixabay Согласно открытым источникам, например списку TOP-500 самых производительных суперкомпьютеров мира, Китай уверенно лидирует по числу самых мощных суперсистем, хотя с прошлого года перестал предоставлять информацию о самых быстрых машинах. Тем не менее, в ноябрьском обновлении списка было 162 китайских суперкомпьютера и только 126 американских. Несмотря на явное преимущество, Китай отстаёт в практическом применении суперкомпьютерных платформ. Была информация, что мощности часто простаивают и создаются просто потому, что это обещало субсидии от государства. В то же время избыток вычислительных мощностей в одном месте не означает, что они не востребованы в другом. Но передать такой ресурс куда-то далеко так просто нельзя. Для этого нужны очень и очень широкие каналы связи и программная поддержка. Именно этим и многим другим, включая подготовку кадров, намерена заняться группа, целью которой станет создание в Китае интернета для суперкомпьютеров. Ожидается, что проект начнёт работать к концу 2025 года. Распределённый вычислительный ресурс будет предоставляться для отраслевых пользователей от разработчиков новых лекарств до финансов, искусственного интеллекта, прогнозирования погоды и обслуживания космических программ, но всё это, в конечном итоге, приведёт к повышению качества жизни простых граждан, путь даже им никогда не позволят войти в этот интернет. Добавим, в Китае над рядом похожих пилотных проектов уже работает компания Huawei. Её опыт и оборудование могут лечь в основу будущего национального суперкомпьютерного интернета. Google заявила, что её чипы для машинного обучения быстрее и экономнее NVIDIA A100
05.04.2023 [13:00],
Павел Котов
Google рассказала о суперкомпьютерах собственной разработки, которые она использует для обучения систем искусственного интеллекта вроде чат-бота Bard. По версии компании, эти системы быстрее и эффективнее, чем сопоставимые с ними ускорители NVIDIA A100. 
Google TPU v4. Источник изображения: Google Инженеры Google разработали собственный чип Tensor Processing Unit или TPU — такие чипы используются более чем в 90 % задач компании по обучению ИИ, в результате на свет появляются чат-боты, способные общаться почти как человек, и системы, генерирующие изображения. Сейчас компания работает с TPU уже четвёртого поколения — в опубликованной инженерами Google статье рассказывается о суперкомпьютере на базе более чем 4000 таких чипов и оптических линиях связи между компонентами системы. Обучение большой языковой модели Google PaLM, крупнейшей из тех, о которых компания поведала общественности, производилось при помощи двух суперкомпьютеров на 4000 чипов в течение 50 дней. Суперкомпьютеры располагают механизмами перенастройки соединений между чипами на лету — это помогает избегать сбоев и повышает производительность. Google только сейчас раскрыла подробности о разработанной её инженерами системе, но отметила, что впервые этот суперкомпьютер был запущен в 2020 году в центре обработки данных в округе Мейс (США, шт. Оклахома). Он, в частности, использовался для обучения ИИ Midjourney — эта нейросеть генерирует изображения по текстовому описанию. По версии Google, её чип TPU четвёртого поколения в 1,7 раза быстрее и в 1,9 раза энергоэффективнее вышедшего одновременно с ним на рынок ускорителя NVIDIA A100. С моделью H100 сравнение не производилось — она вышла на рынок позже, и в её основе лежат более современные технологии. Однако в компании намекнули, что, возможно, работают над новым TPU, способным конкурировать и с H100. От суперпозиции к суперсвязке: в Японии квантовый компьютер подключат к мощнейшему суперкомпьютеру Fugaku
03.01.2023 [21:46],
Геннадий Детинич
За прошедший год в мире зародилось множество проектов по созданию гибридных вычислительных систем, состоящих из связанных между собой квантовых компьютеров и классических суперкомпьютеров. Таким образом, квантовые системы начнут осваивать ниши практических вычислений задолго до появления универсального квантового вычислителя. Продвинутые в создании суперкомпьютеров японцы спешат воспользоваться этим преимуществом и создать рабочее решение к 2025 году. 
Источник изображения: Riken Quantum Computing Подключить к будущей квантовой системе в Японии планируют ни много ни мало, а систему с сильнейшим мировым уровнем, которая до 2022 года целых два года удерживала первое место в списке мощнейших суперсистем мира — это компьютер Fugaku совместной разработки и производства компании Fujitsu и Института физико-химических исследований RIKEN. Будущего квантового партнёра этой системы Fujitsu и RIKEN также будут создавать вместе, и первый его прототип построят в городе Вако префектуры Сайтамо (недалеко от Токио) уже к марту текущего года. Ожидается, что суперкомпьютеры смогут частично смягчить такие «детские болезни» квантовых систем, как вероятностный характер вычислений (значительный уровень ошибок) и короткое время жизни квантовых состояний кубитов. Отметим, сегодня кубиты фактически подключаются к обычным компьютерам, которые устанавливают и считывают их состояния в процессе исполнения алгоритмов, поэтому ничего принципиально нового и сложного в гибридных квантово-классических вычислениях нет. Но и уровень сложности будущей задачи нельзя преуменьшать — согласованная работа в режиме расчётов потребует новых программных сред, инструментов и даже алгоритмов. Для подготовки к будущей совместной работе Fugaku и пока безымянной квантовой системы институт RIKEN создаёт команду разработчиков, которая с 2023 года будет заниматься изучением различных методов и инструментов расчёта для облегчения передачи данных между квантовым компьютером и Fugaku. Запуск системы в работу ожидается в 2025 году. Вскоре после этого партнёры намерены довести гибридную систему до уровня «безошибочного» квантового компьютера. Компания Google, например, обещает создать исключительно квантовый вычислитель без ошибок к 2029 году. Японские инженеры намерены обогнать в этом Google за счёт гибридного подхода. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться