|
Опрос
|
реклама
Быстрый переход
Sora поделится прибылью — OpenAI предложит роялти за использование персонажей Disney и других
04.10.2025 [08:44],
Алексей Разин
Проблема защиты авторских прав при использовании генерируемого нейросетями контента давно будоражит заинтересованных правообладателей, в сфере заимствования текстовой информации она уже породила серию крупных судебных дел с многомиллиардными исками. OpenAI хочет предоставить правообладателям возможность регулировать использование своей интеллектуальной собственности в Sora. 
Источник изображения: OpenAI Напомним, что речь идёт о средстве создания видео при помощи искусственного интеллекта, которое недавно вышло в обновлённом варианте. Глава OpenAI Сэм Альтман в своём блоге в пятницу заявил, что компания предоставит правообладателям более чёткий контроль над созданием персонажей, которые изначально были придуманы ими. Телекомпании и киностудии смогут блокировать использование тех образов создателями видео в Sora, которых сочтут ограничить в копировании и воспроизведении. По данным Reuters, студия Disney уже выразила намерения блокировать использование своего материала в Sora. Альтман добавил, что при этом OpenAI собирается ввести механизм монетизации для тех правообладателей, которые разрешат использование своих персонажей в Sora. По сути, они смогут получать своего рода роялти. Люди создают видео гораздо активнее, чем ожидала OpenAI, нередко для ограниченной аудитории, потребность в монетизации такого контента становится всё более очевидной. Впрочем, Альтман не скрывает, что попытки реализовать монетизацию в этой сфере пройдут путём проб и ошибок, и нужного результата не удастся добиться сразу. Компания готова испытать несколько вариантов, прежде чем остановится на лучшем из них. OpenAI представила Sora 2 — ИИ-генератор видео с реалистичной физикой и логикой, а также возможностью встроить в ролик самого себя
30.09.2025 [21:35],
Андрей Созинов
OpenAI анонсировала Sora 2 — флагманскую ИИ-модель для генерации видео и аудио, которую в компании позиционируют как огромный качественный скачок по сравнению с оригинальной Sora и сравнивают с GPT-3.5, ставшей революционной для генерации текста. Разработчики отмечают, что новая модель приближает ИИ-симуляцию мира к уровню, когда искусственный интеллект начинает «понимать» физику и динамику объектов почти так же, как человек. 
Источник изображения: OpenAI Если ранние модели для генерации видео часто создавали правдоподобную «картинку», но не справлялись с элементарной логикой движений — например, могли «телепортировать» баскетбольный мяч в корзину при промахе, то Sora 2 моделирует именно поведение объектов. Промах — значит, мяч отскочит от щита. Фигурист, делающий тройной аксель, может ошибиться и упасть. Система научилась имитировать не только успех, но и провал — ключевое требование для создания реальных симуляторов мира и продвинутых роботов. Разработчики обещают, что теперь не будет странных деформаций объектов и нарушений логики сцены в угоду соблюдению промпта. Контролируемость — ещё один акцент, отмечаемый OpenAI. Модель Sora 2 уверенно справляется со сложными многошаговыми сценами, удерживая непротиворечивое состояние объектов, локаций и света. В качестве примера приводятся ролики, где фигуристка выполняет сложную программу из нескольких элементов с котом на голове, или где герой аниме вовлечён в зрелищную битву. Всё это — с сохранением целостности мира, связности кадров и даже эмоций на лицах персонажей. Sora 2 умеет работать с несколькими стилями: реалистичным, кинематографичным и аниме. Как универсальная система генерации видео и аудио, Sora 2 способна создавать сложные фоновые звуковые ландшафты, речь и звуковые эффекты с высокой степенью реалистичности. Для этого достаточно короткой видеозаписи: модель точно воспроизведёт внешность, мимику и даже голос, органично интегрируя их в любую сцену. Эта возможность универсальна и работает для любого человека, животного или объекта, отмечает пресс-релиз OpenAI. Одновременно с выпуском Sora 2 компания OpenAI запускает социальное iOS-приложение Sora. В нём пользователи смогут генерировать ролики и делиться ими с друзьями, а также делать ремиксы на работы друг друга, находить новые видео в настраиваемой ленте Sora и добавлять себя или своих друзей с помощью функции «камео». С помощью «камео» можно попасть в любую сцену Sora с поразительной точностью — нужно только через само приложение записать короткое видео с собой и свой голос для подтверждения личности и захвата образа. «На прошлой неделе мы запустили приложение внутри OpenAI. Наши коллеги уже сообщили нам, что благодаря этой функции они завели новых друзей в компании. Мы считаем, что социальное приложение, построенное вокруг функции “камео”, — лучший способ ощутить всю магию Sora 2», — отметила OpenAI в пресс-релизе. OpenAI подчеркнула, что этическое и ответственное использование станет важной частью новой платформы. Пользователь сам будет решать, кто и как может использовать его «камео»; любое видео с участием пользователя можно удалить в любой момент. Контент с откровенно вредным содержанием или созданный без согласия людей блокируется на уровне алгоритмов и модераторов. Приложение Sora уже доступно для скачивания пользователям iPhone в США и Канаде, регистрация проходит через систему приглашений. Через несколько недель Sora 2 станет доступна в веб-версии. Базовая версия бесплатна и имеет «щедрые лимиты», а подписчики ChatGPT Pro вскоре получат доступ к экспериментальной модели Sora 2 Pro с повышенным качеством. Монетизация пока туманна: единственный план — брать деньги за дополнительные генерации при высоком спросе. Расширение географии сервиса и открытие доступа через API входят в планы на ближайшее время. Генератор видео Grok Imagine стал доступен бесплатно для всех
08.08.2025 [10:43],
Павел Котов
Специализирующийся на разработке технологий искусственного интеллекта стартап Илона Маска (Elon Musk) xAI оперативно подготовил ответ на выход новой флагманской модели OpenAI GPT-5 — компания сделала генератор видео Grok Imagine доступным бесплатно для всех желающих. Об этом говорится в сообщении администрации соцсети X. 
Источник изображения: x.com/X Grok Imagine является одним из немногих общедоступных и бесплатных генераторов видео на основе ИИ. Он создаёт короткие ролики на основе загружаемых пользователями изображений. Сервис работает на базе модели Aurora и генерирует ролики длиной до 15 секунд. Первоначально функция была доступна только для подписчиков SuperGrok в отдельном приложении Grok и для подписчиков Premium+ в соцсети X, но теперь ограничения для приложения Grok решили убрать. Сервис предлагает создание видео в трёх режимах: в Normal генерируются «профессиональные» ролики, Fun предназначается для забавного контента, а Spicy открывает доступ к созданию материалов деликатного характера, но с ограничениями и строгой модерацией. Есть мнение, что пока Grok Imagine по реалистичности видео и аудио уступает лидерам отрасли, таким как Google Veo 3 и OpenAI Sora. Воспользоваться генератором видео Grok Imagine можно в приложениях Grok для Android и iOS — достаточно обновить их до последней версии. xAI запустила Grok Imagine — платный ИИ-генератор изображений и видео с «пикантным режимом»
04.08.2025 [19:36],
Сергей Сурабекянц
Компания xAI Илона Маска (Elon Musk) официально представила Grok Imagine — генератор изображений и видео, доступный для подписчиков тарифных планов SuperGrok и Premium+. Как и обещал Маск, позиционирующий Grok как ИИ, свободный от цензуры, Grok Imagine позволяет создавать контент, который обычно в интернете маркируется аббревиатурой NSFW (not safe/suitable for work — «небезопасно/неподходяще для демонстрации на работе»). 
Источник изображения: @elonmusk Grok Imagine преобразовывает текстовые или графические запросы в 15-секундные видеоролики с оригинальным звуком и предлагает «пикантный режим», позволяющий пользователям создавать контент сексуального характера, включая частичную наготу. Пример такого видео опубликовал в своём аккаунте X Илон Маск. Журналисты TechCrunch сообщили, что многие из опробованных ими (во имя журналистики, конечно!) пикантных запросов привели к появлению «модерированных» размытых изображений, однако изображения полуобнажённых тел им получить удалось. NSFW-контент неудивителен для xAI, учитывая выход в прошлом месяце пикантного аниме-компаньона Ani с искусственным интеллектом. Но так же, как необузданная натура Grok была забавной, пока он не начал изрыгать оскорбительный, антисемитский и женоненавистнический контент, появление Grok Imagine может повлечь за собой свои непредвиденные последствия. При этом в Grok Imagine предусмотрены серьёзные ограничения, особенно учитывая, что модель позволяет создавать контент с изображениями знаменитостей. Так, попытки журналистов TechCrunch сгенерировать изображение беременного Дональда Трампа (Donald Trump) успехом не увенчались — Grok Imagine создавал либо изображения Трампа с младенцем на руках, либо рядом с беременной женщиной. Grok Imagine стремится конкурировать с такими игроками, как Google DeepMind, OpenAI, Runway и китайские нейросети, но пока находится на начальном этапе развития. По отзывам тестировщиков, генерируемые им изображения и видео людей нередко выглядят мультяшно, особенно из-за неестественной текстуры кожи. Тем не менее, генератор впечатляет: изображения создаются за считаные секунды и продолжают формироваться автоматически по мере прокрутки страницы. Затем их можно анимировать в стилизованные видеоролики. Пользовательский интерфейс удобен и интуитивно понятен. Недавно Маск заявил о намерении создать Baby Grok — чат-бот, пригодный для работы с детским контентом. Учитывая, насколько скандально развивается «взрослая версия» Grok, подобное направление экспансии довольно рискованно. Тем не менее, с точки зрения охвата аудитории эта ставка вполне может себя оправдать. Популярность Baby Grok может стать дополнительным источником дохода для xAI и новой статьёй расходов для родителей. Adobe выпустила мобильное приложение со всеми генеративными ИИ-инструментами Firefly
17.06.2025 [18:08],
Владимир Фетисов
Платформа генеративных ИИ-сервисов Adobe Firefly теперь доступна на устройствах, работающих под управлением Android и iOS. Новое мобильное приложение Firefly позволяет пользователям генерировать изображения и видео по текстовому описанию, а также экспериментировать с популярными ИИ-инструментами для редактирования фотографий. 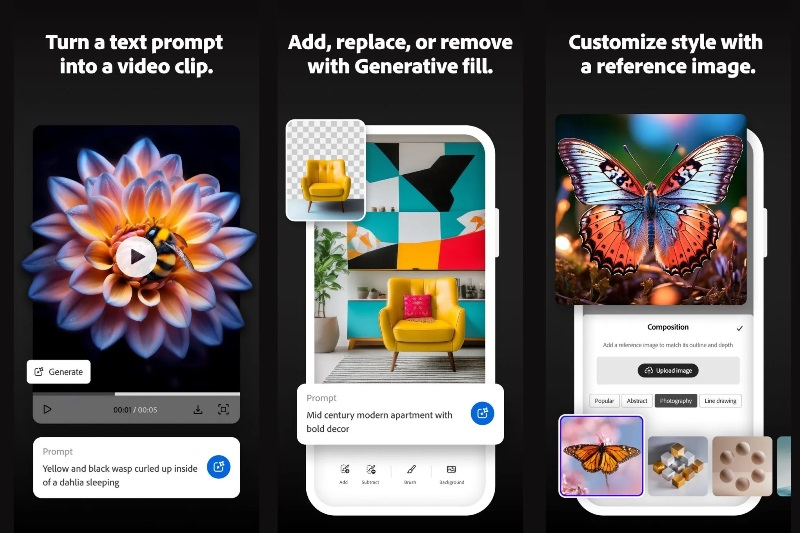
Источник изображения: Adobe Приложение Firefly для Android и iOS включает в себя фирменные алгоритмы Adobe для преобразования текста в изображения и видео, а также генеративные функции, такие как Generative Fill и Generative Expand, которые ранее были доступны в Photoshop. В дополнение к этому пользователи приложения могут взаимодействовать с ИИ-моделями сторонних разработчиков, такими как Google Imagen 3 и Imagen 4 для создания картинок, Veo 2 и Veo 3 для создания видео, а также генератором изображений OpenAI. Созданный в приложении Firefly контент автоматически синхронизируется с учётной записью пользователя на платформе Creative Cloud, что упрощает его дальнейшее размещение в интернете или обработку в других приложениях Adobe. Как и в случае с веб-приложением Firefly, для взаимодействия с некоторыми ИИ-инструментами необходимы кредиты Firefly, которые можно получить в рамках ежемесячных обновлений или путём оформления одного из платных тарифов Creative Cloud. Вместе с этим Adobe расширила возможности генерации видео в публичной бета-версии платформы интерактивных досок Firefly Boards. Теперь пользователи могут повторно микшировать загруженные клипы и генерировать новые кадры с помощью ИИ-модели Firefly, а также сторонних инструментов, таких как Veo 3 от Google. В ближайшее время разработчики также внедрят на платформу больше партнёрских ИИ-моделей от сторонних разработчиков для увеличения количества доступных функций. ИИ обрёл человеческое лицо: Character.AI представила модель AvatarFX для превращения ботов в анимированных персонажей
23.04.2025 [16:50],
Павел Котов
Платформа Character.AI, которая специализируется на общении и ролевых играх пользователей с созданными искусственным интеллектом персонажами, представила модель для генерации видео AvatarFX. Источник изображения: x.com/character_ai Пока AvatarFX доступна в формате закрытого бета-тестирования; она позволяет анимировать персонажей на платформе в различных стилях и с различными голосами — эти персонажи могут быть любыми: от человекоподобных до животных из 2D-мультфильмов. В отличие от конкурирующих решений вроде OpenAI Sora, AvatarFX — не просто генератор видеороликов по текстовым запросам. Пользователи могут создавать видео на основе существующих статических изображений, например, анимировать фотографии реальных людей. Подобные решения создают широкое пространство для злоупотреблений, указывает ресурс TechCrunch: недобросовестные пользователи могут начать загружать фотографии знаменитостей или тех, с кем знакомы в реальной жизни, чтобы виртуальный персонаж сказал или сделал нечто компрометирующее. Технологии создания убедительных дипфейков существуют уже не первый год, но их включение в популярные потребительские продукты масштаба Character.AI лишь усугубляет угрозу. В прошлом году трагедией закончилось общение созданного на платформе Character.AI ИИ-персонажа «Игры престолов» с 14-летним американским подростком. В ответ на это администрация сервиса добавила в приложение родительский контроль и дополнительные средства безопасности. Комментариев по поводу возможных злоупотреблений AvatarFX в компании не дали. Grok научится создавать видео: xAI поглотила разработчика ИИ-генератора видео Hotshot
17.03.2025 [22:57],
Владимир Фетисов
Принадлежащая американскому бизнесмену Илону Маску (Elon Musk) компания xAI стала владельцем стартапа Hotshot, который работает над созданием инструментов на базе искусственного интеллекта, предназначенных для генерации видео. О завершении сделки в своём аккаунте в соцсети X заявил Аакаш Састри (Aakash Sastry), соучредитель и генеральный директор Hotshot. 
Источник изображений: xAI «За последние два года мы небольшой командой создали три модели для генерации видео — Hotshot-XL, Hotshot Act One и Hotshot. Процесс обучения этих моделей помог нам понять, как в ближайшие годы будут меняться глобальные сферы образования, развлечения, общения и производительности. Мы рады продолжить масштабирование усилий в крупнейшем в мире кластере Colossus, как часть xAI», — сказано в сообщении Састри. Компания Hotshot была основана несколько лет назад в Сан-Франциско. Изначально стартап занимался разработкой ИИ-инструментов для генерации и редактирования изображений, но со временем переориентировался на модели искусственного интеллекта, позволяющие генерировать видео на основе текстовых подсказок. Ранее Hotshot удалось привлечь внимание инвесторов, но размер вложенных в стартап средств никогда не озвучивался публично. Переход Hotshot под контроль xAI может помочь стартапу в создании ИИ-моделей для генерации видео, которые станут конкурентами аналогов, таких как Sora от OpenAI или Veo 2 от Google. Ранее Маск намекал, что xAI работает над созданием инструментов генерации видео, которые в будущем планируется интегрировать с чат-ботом Grok. В начале этого года бизнесмен заявлял, что ожидает появление модели «Grok Video через несколько месяцев». Alibaba снова ударила по OpenAI — вышел бесплатный ИИ-генератор реалистичных видео Wan 2.1
26.02.2025 [13:25],
Павел Котов
Китайский гигант в области электронной коммерции Alibaba сделал общедоступной разработанную им модель искусственного интеллекта для создания видео и статических изображений Wan 2.1. Этим шагом компания создала условия для её массового развёртывания и способствовала усилению конкуренции в области ИИ. 
Источник изображения: Alibaba Публикация ИИ-моделей с открытым исходным кодом — распространённый шаг в отрасли ИИ; одним из наиболее заметных игроков здесь стал стартап DeepSeek. Alibaba выпустила четыре варианта Wan 2.1: T2V-1.3B, T2V-14B, I2V-14B-720P и I2V-14B-480P — эти модели генерируют видео и статические картинки по текстовому запросу или по образцу, которым может служить изображение. Обозначения «1.3B» и «14B» указывают, что эти варианты содержат соответственно 1,3 млрд и 14 млрд параметров. Младшей модели T2V-1.3B для работы требуется всего 8,19 Гбайт видеопамяти, что делает её совместимой со многими потребительскими видеокартами. Разработчики заявляют, что эта модель может сгенерировать пятисекундный ролик в 480р на GeForce RTX 4090 примерно за 4 минуты (без оптимизаций). Модели доступны для пользователей по всему миру на платформах HuggingFace и ModelScope (входит в Alibaba Cloud) для академических, исследовательских и коммерческих целей. Последнюю версию модели ИИ для генерации видео Alibaba представила в январе — первоначально она называлась Wanx, впоследствии её переименовали в Wan. Проект получил высокую оценку в тестах Vbench, предназначенных для генераторов видео — в частности, она стала лидером по критерию взаимодействия объектов. Накануне Alibaba также выпустила предварительный вариант рассуждающей модели QwQ-Max, которая впоследствии также будет опубликована как проект с открытым кодом. В ближайшие три года компания намеревается вложить не менее 380 млрд юаней ($52 млрд) в поддержку облачных вычислений и инфраструктуры ИИ. «Сбер» представил собственный ИИ-генератор видео по текстовому описанию Kandinsky 4.0 Video
12.12.2024 [23:02],
Владимир Фетисов
На проходящей на этой неделе конференции AI Journey «Сбер» представил бета-версию нейросети Kandinsky 4.0 Video, которая позволяет генерировать реалистичные видео на основе текстового описания или стартового кадра. Алгоритм может быть полезен не только обычным пользователям, но также дизайнерам, маркетологам и мультипликаторам, так как с его помощью можно создавать различные видео: от анимированных роликов с поздравлениями для близких до трейлеров и клипов. 
Источник изображения: fusionbrain.ai В компании отметили, что с момента релиза первой версии Kandinsky Video в прошлом году разработчики значительно улучшили многие характеристики алгоритма, включая качество создаваемых роликов и скорость генерации. Обновлённая нейросеть способна создавать ролики продолжительностью до 12 секунд с разрешением 1280 × 720 пикселей на основе текстового описания или изображения. Также поддерживается создание роликов с различным соотношением сторон. Улучшилось визуальное качество: повысились контрастность и чёткость кадров, композиция стала более выверенной, а движения объектов в кадре — реалистичными. В дополнение к этому разработчики анонсировали ускоренную версию нейросети — Kandinsky 4.0 Video Flash, которая способна генерировать ролики продолжительностью до 12 секунд с разрешением 720 × 480 пикселей всего за 15 секунд. На начальном этапе доступ к новой версии Kandinsky Video получат представители креативных индустрий, включая художников, дизайнеров и кинематографистов через портал fusionbrain.ai. Для обычных пользователей алгоритм станет доступен в первом квартале следующего года. OpenAI запустила ИИ-генератор видео по текстовым запросам Sora — он косячит так же, как и другие
10.12.2024 [01:30],
Андрей Созинов
Компания OpenAI в понедельник запустила Sora — свою революционную модель искусственного интеллекта для генерации видео по текстовым описаниям. С сегодняшнего дня новая модель стала доступна на сайте Sora.com для платных пользователей ChatGPT в США и «большинстве других стран». России в списке нет, как и стран ЕС. 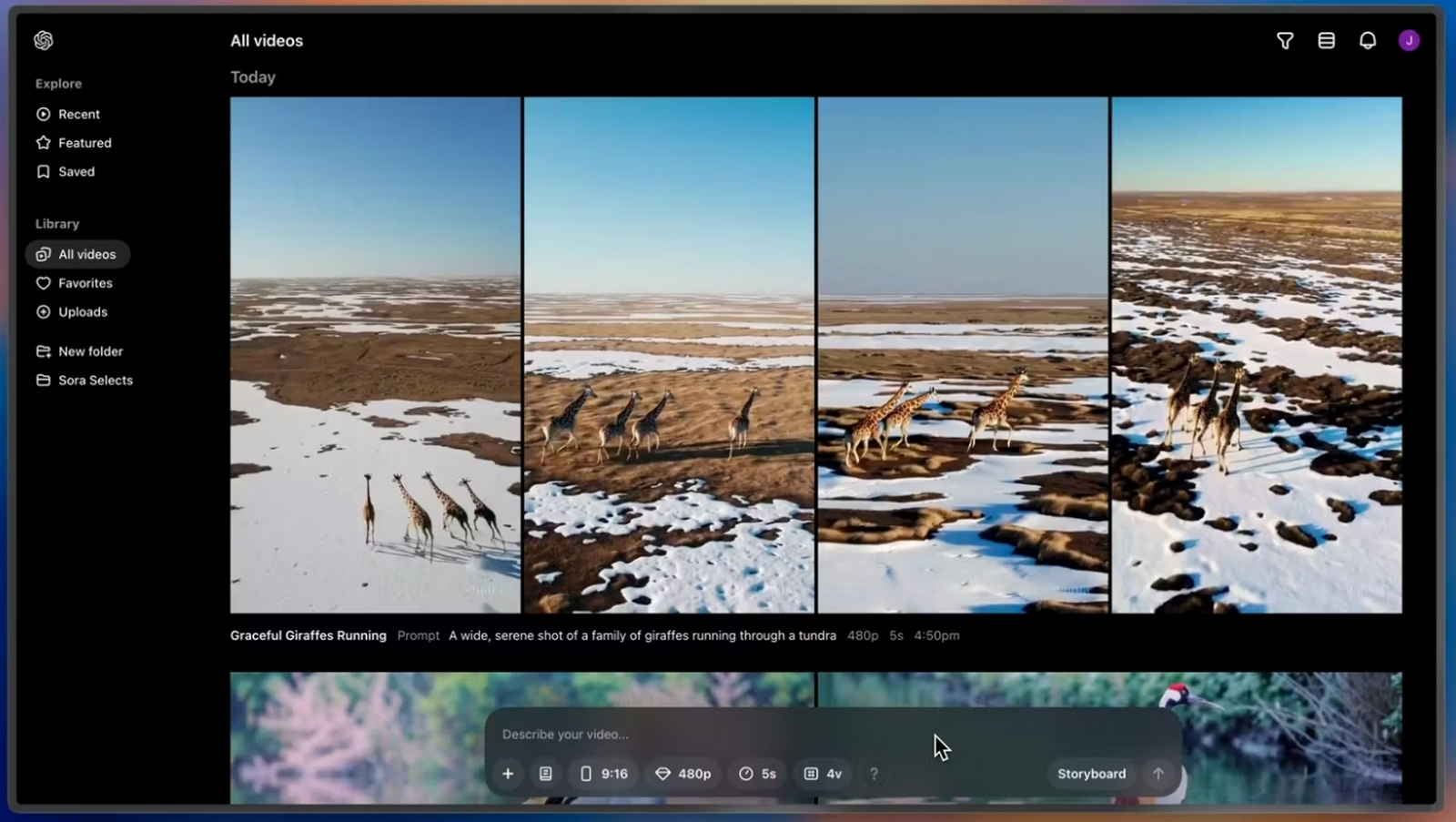 Представленная сегодня версия под названием Sora Turbo может генерировать ролики длиной от 5 до 20 секунд в различных соотношениях сторон и разрешениях от 480p до 1080p. Каждая генерация обойдётся пользователю в определённое количество так называемых «кредитов». Например, видео в 480p стоит от 20 до 150 кредитов, ролик в 720p — от 30 до 540 кредитов, а видео в 1080p — от 100 до 2000 кредитов. Что именно влияет на цену, пока не уточняется. OpenAI сообщила, что подписчики базового тарифного плана ChatGPT Plus ($20 в месяц) получат 1000 кредитов в месяц. Это позволит сгенерировать до 50 «приоритетных видео» (то есть видео, которые генерируются быстро) в формате 720p и длительностью 5 секунд. В свою очередь, пользователи нового тарифа ChatGPT Pro за $200 в месяц получат 10 000 кредитов, которые смогут потратить на 500 приоритетных видео в формате 1080p и длительностью 20 секунд. Кроме того, более обеспеченные пользователи получат неограниченное количество низкоприоритетных генераций видео. Также пользователи с подпиской Pro смогут выполнять до пяти генераций одновременно и скачивать ролики без водяных знаков. OpenAI отмечает, что видео, созданные с помощью Sora, по умолчанию будут иметь видимые водяные знаки и метаданные C2PA, указывающие на их создание с помощью ИИ. Sora может создавать несколько вариантов видеоклипов на основе текстовой подсказки или изображения, а также редактировать существующие видео с помощью инструмента Re-mix. Интерфейс Storyboard позволяет пользователям создавать видео на основе последовательности подсказок, инструмент Blend объединяет два видео, сохраняя элементы обоих, а опции Loop и Re-cut дают возможность авторам дополнительно настраивать и редактировать свои видео и сцены. По словам видеоблогера Маркуса Браунли (Marcus Brownlee), известного как MKBHD, который получил доступ к предварительной версии Sora, система работает далеко не идеально. На создание среднего видеоролика в формате 1080p у него уходило «пара минут». Эта модель страдает от тех же недостатков, что и другие генераторы видео: ей не хватает постоянства объектов. В видеороликах Sora объекты перемещаются нелогично, исчезают и появляются вновь без видимой причины. Ноги — ещё один серьёзный источник проблем, отмечает Браунли. Если человек или животное с ногами долго ходит в ролике, Sora путает передние и задние ноги, а сами ноги могут «меняться местами». Также сообщается, что в Sora встроен ряд защитных механизмов, запрещающих генерировать видео с изображением людей младше 18 лет, содержащие насилие, «откровенные темы» или нарушающие авторские права третьих лиц. По словам Браунли, Sora также не создаёт видео на основе изображений с общественными деятелями, узнаваемыми персонажами или логотипами. Компания предупреждает, что «неправомерное использование загружаемых медиафайлов» может привести к запрету или приостановке работы аккаунта. По мнению блогера, новинка может быть полезна для генерации таких вещей, как заставки в определенном стиле, анимации, абстракции и стоп-кадры. Но он не стал бы рекомендовать её для создания фотореалистичных роликов. OpenAI подчёркивает, что это «ранняя версия Sora», в которой «будут ошибки». «Она не идеальна, но уже на том этапе, когда мы думаем, что она будет действительно полезна для дополнения человеческого творчества, — заявил Уилл Пиблз (Will Peebles), член технического персонала OpenAI и руководитель исследования Sora. — Мы не можем дождаться, когда увидим, что мир создаст с помощью Sora». Если у вас нет подписки на ChatGPT, вы всё равно сможете просматривать ленту видеороликов, созданных искусственным интеллектом другими пользователями с помощью Sora. В то время как модель станет доступна в США и многих других странах уже сегодня, генеральный директор OpenAI Сэм Альтман (Sam Altman) отметил, что запуск в «большинстве стран Европы и Великобритании» может «занять некоторое время». Китайская Tencent представила генератор видео HunyuanVideo, который пользователи назвали лучшим из существующих
05.12.2024 [10:57],
Павел Котов
Китайский технологический гигант Tencent анонсировал HunyuanVideo — передовую модель искусственного интеллекта для генерации видео, опубликованную с открытым исходным кодом. Впервые код вывода и веса модели ИИ с такими возможностями доступны всем желающим. 
Источник изображения: Tencent HunyuanVideo, как утверждает Tencent, способна генерировать видеоролики на уровне ведущих мировых систем с закрытым исходным кодом — эти видео отличают высокое качество картинки, разнообразие движений объектов в кадре, способность синхронизировать визуальный и звуковой ряд, а также стабильность генерации. Это крупнейшая модель для генерации видео — у неё 13 млрд параметров. Пакет HunyuanVideo включает в себя фреймворк с инструментами для управления данными; инструментами для совместного обучения моделей, работающих с изображениями и видео; а также инфраструктуру с поддержкой крупномасштабного обучения моделей и их запуска. Tencent протестировала модель при поддержке профессионального сообщества, которое установило, что HunyuanVideo превосходит по качеству закрытые проекты Runway Gen-3 и Luma 1.6. Чтобы добиться такого результата, разработчик обратился к гибридной архитектуре передачи «двойного потока в одинарный» (Dual-stream to Single-stream). На начальном этапе видео- и текстовые токены обрабатываются независимо несколькими блоками модели-трансформера, благодаря чему данные разных форматов преобразуются без помех. На этапе единого потока видео- и текстовые токены передаются в последующие блоки трансформера, обеспечивая эффективное слияние мультимодальных данных. Это позволяет зафиксировать сложные отношения между визуальной и семантической информацией, а общая производительность модели повышается. Выпустив HunyuanVideo, компания Tencent сделала значительный шаг к демократизации технологий создания видео при помощи ИИ. Благодаря открытому исходному коду модель способна произвести революцию в экосистеме генерации видео. ИИ-функция Google Vids для генерации видео стала доступна пользователям Workspace
08.11.2024 [19:47],
Владимир Фетисов
В апреле этого года Google представила инструмент Vids, который построен на базе искусственного интеллекта, предназначен для генерации или редактирования видео, а также позиционируется как средство для совместной работы. Он позволит пользователям создавать ролики профессионального уровня без необходимости учиться работе с ПО для редактирования и обработки видео. Теперь же этот инструмент становится доступен пользователям платформы Google Workspace. 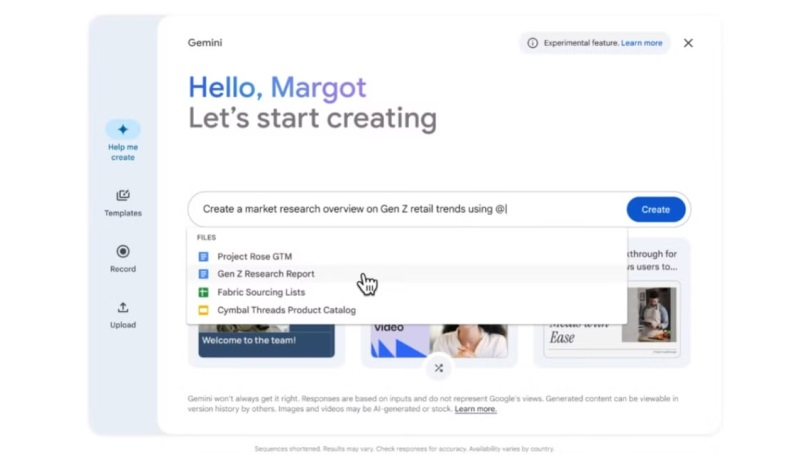
Источник изображения: Google В новом сообщении разработчиков в блоге Workspace подчёркивается, что Vids будет полезен для команд, занимающихся обучением клиентов, развитием разных проектов, маркетингом, хотя по сути данный инструмент может пригодиться кому-угодно для реализации творческих идей. Основой Vids стала нейросеть Gemini, которая позволяет быстро генерировать видео, которые могут потребоваться бизнес-клиентам компании. К примеру, одна из функций позволяет сгенерировать раскадровку на основе текстового запроса и документа из Google Диска. В раскадровке излагаются подтемы, которые будут рассмотрены в будущем видео, а пользователь может менять их очередность, удалять какие-то пункты и добавлять новые. После выбора стиля алгоритм объединит черновик видео с созданным сценарием, включая выбранные медиафайлы, текст, сценарии для каждой сцены и даже фоновую музыку. Пользователи также получат доступ к готовым шаблонам, которые можно быстро адаптировать под свои задачи. При необходимости к видео можно добавить закадровый голос, генерируемый ИИ-алгоритмом. Отметим, что входящие в состав Vids функции на основе ИИ, такие как «Помоги мне создать», «Удалить фон изображения», «Создать закадровый голос», будут доступны бесплатно до конца 2025 года. В сообщении разработчиков сказано, что ограничения на использование ИИ-функций в Vids могут быть введены, начиная с 2026 года. Google начала тестировать Vids с привлечением ограниченного числа пользователей летом этого года. Теперь же этот инструмент становится доступным бизнес-клиентам платформы Workspace. Отмечается, что для оптимальной работы в Vids лучше использовать последние версии браузеров Chrome, Firefox и Edge для Windows. Другие браузеры также поддерживаются, но некоторые функции могут работать в них некорректно. Представлен ИИ-генератор чрезвычайно реалистичных видео Luma Dream Machine — попробовать можно бесплатно
13.06.2024 [16:24],
Павел Котов
Компания Luma Labs представила модель искусственного интеллекта Dream Machine, предназначенную для создания видео и доступную массовому пользователю. Систему отличает высокий реализм — создаваемые ей видео совсем не похожи на творчество ИИ. 
Источник изображений: x.com/LumaLabsAI Разработчик анонсировал свой проект в соцсети X, опубликовав несколько примеров созданных ИИ видео. «Представляем Dream Machine — видеомодель нового поколения для создания высококачественных реалистичных роликов по текстовым запросам и изображениям с помощью ИИ», — говорится в описании. Проект стал пользоваться высоким спросом, поэтому в ближайшее время опробовать систему в деле будет непросто — запросы большинства пользователей ставятся в очередь, и некоторые бросают забаву, так и не дождавшись результатов. Возможно, когда шумиха вокруг нового проекта поутихнет, работать с системой будет проще. Попробовать создать видео по текстовому описанию или по статическому изображению может любой желающий, достаточно лишь зарегистрировать учётную запись. После этого в Dream Machine можно создать 30 видео в месяц — есть и платные варианты до 2000 видео в месяц за $499, но большинству, вероятно, хватит бесплатной версии сервиса. ИИ-модель действительно отличают реалистичные видео, причём реалистично смотрятся не только объекты на роликах, но и движения камеры — как будто съёмку ведёт профессиональный оператор. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






