
Опрос
|
реклама
Быстрый переход
Asus выпустила две версии GeForce Prime RTX 5080 EVO без испарительной камеры
31.03.2026 [19:08],
Николай Хижняк
Компания Asus выпустила две версии видеокарты GeForce Prime RTX 5080 EVO 16GB. От ранее выпущенной обычной модели Prime они отличаются отсутствием испарительной камеры в составе их систем охлаждения. 
Источник изображений: Asus По сравнению с ранее выпущенной моделью Prime у новых версий RTX 5080 EVO (модели PRIME-RTX5080-16G-EVO и PRIME-RTX5080-O16G-EVO) нет никаких внешних отличий. Карты имеют тот же размер и ту же толщину — 2,5 слота расширения. Однако в описании продукта отсутствует упоминание испарительной камеры. На изображениях структуры радиатора этот элемент у моделей EVO заменён классическим решением с тепловыми трубками. 
Обычная Prime с испарительной камерой (сверху) и модель EVO без испарительной камеры (снизу) Использование испарительной камеры в мощных видеокартах обычно позволяет более эффективно распределять тепло по радиатору и избегать локального перегрева графического процессора. Для модели PRIME-RTX5080-O16G-EVO заявляется частота графического процессора до 2685 МГц в режиме OC, а для модели PRIME-RTX5080-16G-EVO — до 2640 МГц. Обе карты имеют размеры 304 × 126 × 50 мм и оснащены одним 12+4-контактным разъёмом питания. Производитель рекомендует использовать с картами блок питания мощностью от 850 Вт. Как фен помог обойти санкции: топ-менеджеров Supermicro обвинили в контрабанде ИИ-чипов в Китай
20.03.2026 [04:57],
Алексей Разин
До сих пор все инциденты с подозрением американских регуляторов по поводу участия американских граждан в контрабандной поставке ИИ-ускорителей в Китай имели отношение к небольшим компаниям, но на днях обвинение было выдвинуто в адрес лиц, имеющих непосредственное отношение к руководству компании Supermicro. 
Источник изображения: Super Micro Computer Как подчёркивает CNBC, обвинительное определение Офиса федерального прокурора США по Южному округу Нью-Йорка содержит упоминания о частных лицах, связанных с неким американским производителем серверного оборудования, но из фамилий и имён обвиняемых становится понятно, что речь идёт именно о Super Micro Computer. Упоминаемый в документе И Шянь Лио (Yih-Shyan Liaw) является сооснователем компании и действующим членом совета директоров. Руэй Цань Чан (Ruei-Tsan Chang) руководит продажами оборудования этой марки на Тайване, а Тин Вэй Сунь (Ting-Wei Sun) является представителем подрядчика Supermicro. По версии американских органов правопорядка, трое обвиняемых организовали нелегальный экспорт серверного оборудования с ускорителями Nvidia в Китай с использованием подставной компании в Юго-Восточной Азии, которая в документах значилась конечным получателем продукции. Ещё одна компания была задействована для переупаковки поставляемых грузов, чтобы скрыть факт их поставки в Китай. Сообщается, что обвиняемые подготовили тысячи неработающих поддельных серверов для проверок, а затем снова использовали эти же «пустышки» во время проверки Министерства торговли США. По словам прокуроров, перед этой проверкой участники схемы с помощью обычного строительного фена сняли и заново наклеили этикетки и наклейки с серийными номерами, после чего переупаковали поддельные серверы в коробки производителя. Обвиняемые, по версии следствия, оказывали давление на инспектирующие органы, а также пытались ввести в заблуждение представителя Министерства торговли США, которому была поручена дополнительная проверка поставок. Торговый представитель Supermicro на Тайване якобы участвовал в манипуляциях документами и пытался привлечь «нужного» аудитора к проверке. Следствие считает, что И Шянь Лио в конце 2024 года пытался организовать поставки ускорителей Nvidia B200 в Китай через подставную компанию. Следователи располагают фрагментами переписки представителя Supermicro с предполагаемыми соучастниками. В 2025 году он торопил поставщиков, стремясь отправить в Китай больше оборудования до вступления в силу новых официальных запретов. Из троих фигурантов дела двое уже арестованы, тайваньский представитель Sipermicro находится в розыске. Акции компании на фоне таких новостей упали в цене на 12 %. Colorful выпустила видеокарту iGame GeForce RTX 5070 Ti Ultra Z Black OC со съёмным разъёмом питания GC-HPWR
19.03.2026 [00:35],
Николай Хижняк
Компания Colorful представила видеокарту iGame GeForce RTX 5070 Ti Ultra Z Black OC 16GB. Карта выделяется оформлением и RGB-подсветкой в стиле граффити. А ещё она оснащена дополнительным съёмным ножевым разъёмом питания GC-HPWR. 
Источник изображений: Colorful В основе видеокарты используется графический процессор с 8960 ядрами CUDA. Для чипа заявлен дополнительный заводской разгон. Базовая частота GPU составляет 2295 МГц, а Boost-частота — 2452 МГц. Доступный профиль разгона One-Key OC повышает частоту Boost до 2497 МГц. Карта имеет 16 Гбайт памяти GDDR7 (28 Гбит/с на контакт) с 256-битной шиной и общей пропускной способностью 896 Гбайт/с. Энергопотребление iGame GeForce RTX 5070 Ti Ultra Z Black OC 16GB заявлено на уровне 300 Вт. Производитель рекомендует использовать с ней блок питания мощностью от 750 Вт. В оснащение карты входят три разъёма DisplayPort 2.1b и один порт HDMI 2.1b. 
 Размеры карты составляют 300,5 × 120 × 50 мм, а вес — 1,1 кг без комплектной подставки. Карта занимает 2,5 слота расширения. Помимо одного привычного 12+4-контактного разъёма 12V-2x6 карта оснащена съёмным ножевым разъёмом GC-HPWR. Судя по всему, одновременное использование обоих способов подключения питания не поддерживается.  В Китае iGame GeForce RTX 5070 Ti Ultra Z Black OC 16GB оценивается в 8099 юаней (около $1176). Это соответствует цене ранее выпущенной версии SFF (для компактных ПК), не оснащённой разъёмом GC-HPWR. Nvidia наконец выпустила рабочую станцию DGX Station на базе GB300 Grace Blackwell — у неё почти полтерабайта LPDDR5X
17.03.2026 [23:02],
Николай Хижняк
Компания Nvidia официально выпустила рабочую станцию DGX Station, представленную в прошлом году на конференции GTC 2025. Система ориентирована на разработчиков программного обеспечения, исследователей, специалистов по обработке данных и всех, кому требуется больше вычислительной мощности для ИИ, чем может обеспечить более компактная модель Nvidia DGX Spark. 
Источник изображения: Nvidia В составе DGX Station используется ускоритель Nvidia GB300 Grace Blackwell Ultra, который сочетает 72-ядерный процессор Grace и графический процессор Blackwell Ultra, объединённые интерфейсом NVLink C2C со скоростью 900 Гбайт/с. Система оснащена впечатляющим объёмом встроенной памяти — 784 Гбайт. Процессор работает в паре с 496 Гбайт памяти LPDDR5X со скоростью 396 Гбайт/с, а графический процессор — с 252 Гбайт памяти HBM3e со скоростью 7,1 Тбайт/с. Оба пула памяти объединены, что позволяет процессору и графическому процессору совместно использовать память друг друга для максимальной производительности ИИ. Nvidia оснастила DGX Station тремя слотами PCIe 5.0 x16: один поддерживает 16 линий, а два других — по восемь линий. Система официально поддерживает установку дискретных видеокарт, которые можно подключать к слотам PCIe для выполнения дополнительных задач, таких как моделирование и трассировка лучей. Поддерживаются следующие GPU: RTX Pro 6000 Workstation Edition, RTX Pro 6000 Blackwell Max-Q Workstation Edition, RTX Pro 4000 Blackwell SFF Edition и RTX Pro 2000 Blackwell. Рабочая станция DGX Station также оснащена четырьмя слотами M.2, аудиоразъёмами и портами USB. В рабочей станции используется сетевой контроллер Nvidia ConnectX-8 SuperNIC, поддерживающий скорость до 800 Гбит/с через два порта QSFP112. Система предназначена для ускорения проектов в области искусственного интеллекта путём подключения до двух станций DGX для масштабирования производительности и возможностей моделирования. Питание осуществляется через один 24-контактный разъём ATX, один 8-контактный разъём EPS и три разъёма питания 12V-2x6 для GPU, обеспечивающие заявленную мощность системы в 1600 Вт. Nvidia заявляет, что DGX Station уже доступна для заказа и начнёт поставляться в ближайшие месяцы через компании-партнёры, включая Asus, Dell, Gigabyte, MSI, Supermicro и HP. Nvidia выпустила однослотовый серверный ускоритель RTX Pro 4500 Blackwell Server Edition для ИИ и других задач
17.03.2026 [19:08],
Николай Хижняк
Компани Nvidia представила профессиональную видеокарту RTX Pro 4500 Blackwell Server Edition, предназначенную для центров обработки данных, периферийных устройств и облачных вычислений. Карта ориентирована на выполнение задач искусственного интеллекта, обработку данных, видеозадачи и визуальные вычисления. 
Источник изображений: Nvidia Новая серверная версия ускорителя выполнена в форм-факторе карты расширения PCIe толщиной в один слот, как и ранее выпущенная стандартная версия RTX Pro 4500 Blackwell для рабочих станций. Обе карты имеют по 10 496 ядер CUDA и по 32 Гбайт памяти GDDR7. Одними из ключевых отличий между двумя ускорителями являются дизайн и энергопотребление. Серверная версия оснащена однослотовой пассивной системой охлаждения и имеет заявленный показатель энергопотребления 165 Вт. Стандартный вариант RTX Pro 4500 Blackwell толщиной в два слота расширения оснащён кулером с вентилятором тангенциального типа. При этом энергопотребление карты заявлено на уровне 200 Вт. 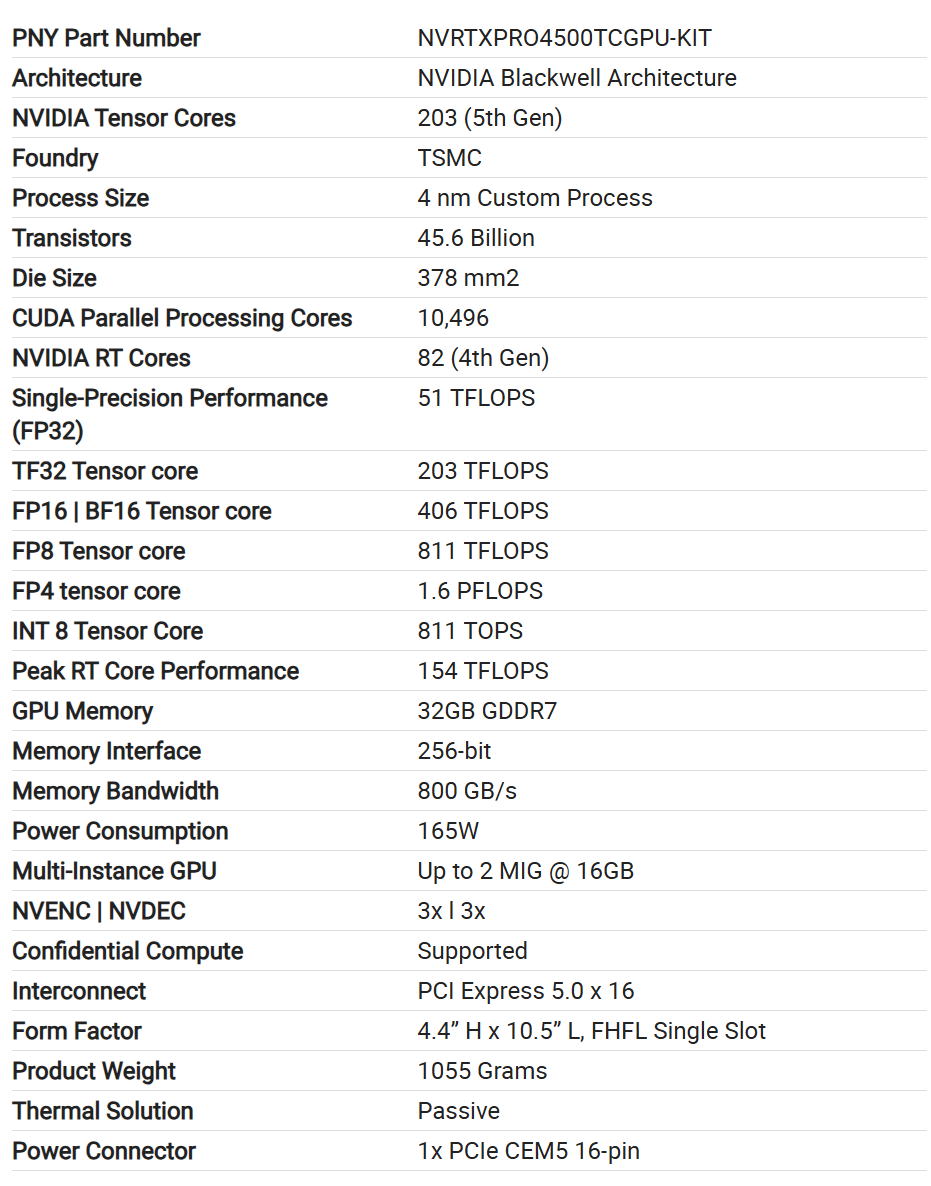 Серверная версия также поставляется с памятью с более низкой пропускной способностью. Чипы памяти модели RTX Pro 4500 Blackwell Server Edition работают с частотой 3125 МГц, что соответствует 25 Гбит/с эффективной пропускной способности на контакт, по сравнению с 3500 МГц или 28 Гбит/с у стандартной RTX Pro 4500. В результате общая пропускная способность памяти у серверной версии составляет 800 Гбайт/с вместо 896 Гбайт/с у обычной. Ещё одно отличие заключается в наборе внешних разъёмов. По сравнению со стандартной RTX Pro 4500 Blackwell серверная версия не оснащена внешними видеопортами. Это ожидаемо для устройства, ориентированного на центры обработки данных, где карта будет использоваться в составе стоечных серверов для удалённых рабочих нагрузок, а не в составе рабочих станций для локальных задач. 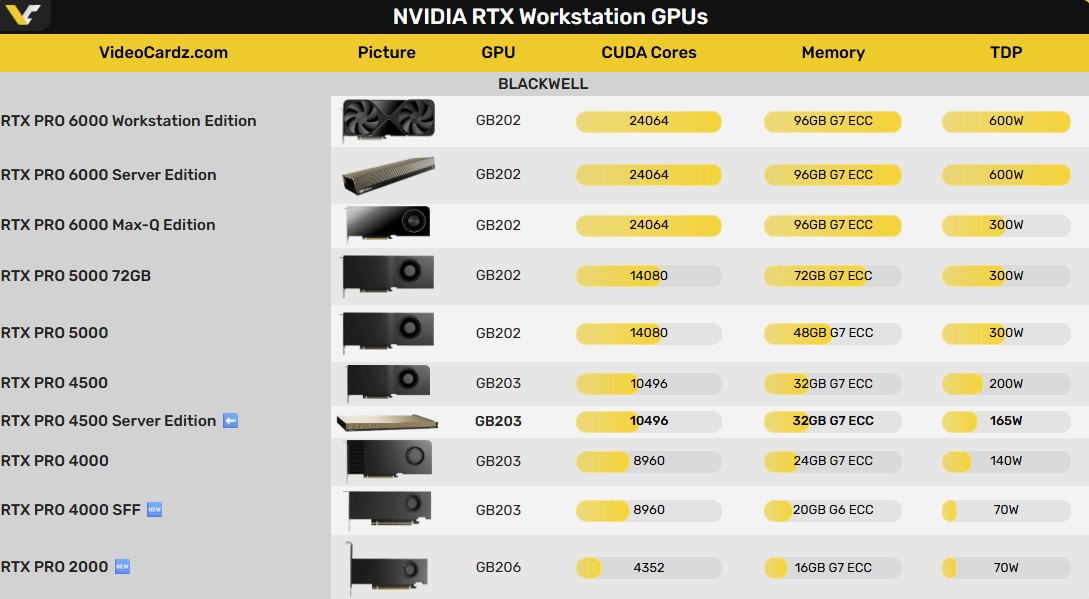
Вся актуальная линейка ускорителей Nvidia RTX Pro для серверов и рабочих станций. Источник изображения: VideoCardz Nvidia позиционирует RTX Pro 4500 Blackwell Server Edition как более компактную и энергоэффективную альтернативу в профессиональной линейке Blackwell. Она сохраняет ту же конфигурацию графического процессора и тот же объём памяти в 32 Гбайт, что и стандартная RTX Pro 4500 Blackwell, но жертвует видеовыходами и некоторой пропускной способностью памяти в пользу пассивной однослотовой конструкции, лучше подходящей для корпоративных платформ. ByteDance нашла обход санкций США — её ИИ будет работать на Nvidia B200 в Малайзии
13.03.2026 [11:25],
Алексей Разин
Для китайских разработчиков ИИ геополитическая ситуация неприятна тем, что передовые американские ускорители им запрещают импортировать не только США, но и власти КНР, а на внутреннем рынке альтернатив им по быстродействию нет. В таких условиях ByteDance намерена эксплуатировать построенный в Малайзии ЦОД, который будет оснащён ускорителями Nvidia B200 с архитектурой Blackwell. 
Источник изображения: Nvidia Как отмечает The Wall Street Journal, в интересах ByteDance южноазиатская компания Aolani Cloud строит в Малайзии центр обработки данных, включающий 36 000 ускорителей Nvidia B200, которые нельзя импортировать на территорию КНР из-за американских санкций. В свою очередь, Aolani будет закупать серверные системы у Aivres, которая их производит. Первая из компаний официально входит в число привилегированных партнёров Nvidia, которые в первую очередь получают ускорители для развития ИИ-инфраструктуры. Основанная в 2023 году, Aolani входит в зарегистрированный на Каймановых островах холдинг. С февраля прошлого года она сдаёт в аренду ByteDance малазийские ЦОД на основе ускорителей Nvidia H100. Теперь китайский гигант надеется получить доступ к вычислительным мощностям на базе более современных B200 с архитектурой Blackwell, и для этого уже авансом перевела Aolani некоторую часть суммы, подразумевающей оплату сделки. Для оснащения нового ЦОД в Малайзии потребуется закупить оборудование на сумму $2,5 млрд, как минимум. Уже сейчас в строй введено аппаратное обеспечение на общую сумму около $100 млн. Aolani подчёркивает, что осуществляет свою деятельность в строгом соответствии с американскими правилами экспортного контроля. Компания собирается открыть вычислительные мощности в Южной Корее, Австралии и Европе. Самой ByteDance данная малазийская площадка потребуется для проведения разработок и исследований, а также обслуживания клиентов за пределами Китая. Уже сейчас владелец TikTok около четверти общей выручки получает на внешних рынках. Пять разработанных ByteDance приложений входят в число 50 наиболее популярных в мире по итогам января текущего года. Команды разработчиков ByteDance находятся не только в Китае, но и в Сингапуре и США, причём в последнем из государств штат специалистов китайской компании активно расширяется. Компания планирует использовать в своих целях серверные системы на базе более чем 7000 ускорителей Nvidia B200, которые расположены в Индонезии, так что Малайзия является не единственным местом концентрации обслуживающих её интересы ЦОД. MSI выпустила GeForce RTX 5070 Light Edition и Void Edition по мотивам World of Warcraft: Midnight
03.03.2026 [15:12],
Николай Хижняк
Компания MSI анонсировала ограниченный выпуск специальных версий GeForce RTX 5070 в оформлении по мотивам дополнения World of Warcraft: Midnight. Производитель выпустил два варианта карты — в исполнении Light Edition и Void Edition. 
Источник изображений: VideoCardz / MSI MSI заявляет, что оба дизайна вдохновлены Кель'Таласом (новым регионом в игре) и темой Света против Пустоты. В издании Light Edition используется светлое оформление, в то время как в издании Void Edition преобладает более темный стиль и многослойные элементы освещения. 
 Что касается аппаратной части, обе карты имеют одинаковые основные характеристики. MSI указывает одинаковую тактовую частоту в режиме «экстремальная производительность» (2625 МГц через MSI Center) и частоту в режиме Boost 2610 МГц для обеих версий. Обе карты имеют по 6144 ядра CUDA и по 12 Гбайт памяти GDDR7 со скоростью 28 Гбит/с на контакт с шиной памяти 192 бит. Набор внешних разъёмов у них тоже одинаковый: три DisplayPort 2.1b и один HDMI 2.1b. Карты основаны на дизайне MSI TRI FROZR 4. В нём же выпускаются модели Gaming Trio. В комплект поставки видеокарт входят подставки и стандартный набор дополнительных аксессуаров. Показатель энергопотребления у карт заявлен на уровне 250 Вт. Они оснащены одним 12+4-контактным разъёмом 12v-2x6. Производитель рекомендует использовать с картами блок питания мощностью от 650 Вт.  MSI добавила, что карты Light Edition и Void Edition появились в продаже по всему миру со 2 марта, но их поставки ограничены. Стоимость новинок производитель не сообщил. Asus поделилась деталями ProArt GeForce RTX 5090 — минималистичный дизайн в стиле Founders Edition и заводской разгон GPU
28.02.2026 [22:42],
Николай Хижняк
Компания Asus поделилась полными техническими характеристиками видеокарты ProArt GeForce RTX 5090 32GB GDDR7 OC Edition (PROART-RTX5090-O32G). Впервые новинку продемонстрировали на выставке CES 2026. 
Источник изображений: VideoCardz / Asus В основе ProArt RTX 5090 используется печатная плата в стиле PCB эталонной модели RTX 5090 Founders Edition от Nvidia. Карта оснащена так называемой сквозной системой охлаждения. Она получила два больших вентилятора диаметром 115 мм, которые прогоняют воздух через радиатор и выталкивают его с обратной стороны через два крупных отверстия. Производитель также применяет в составе системы охлаждения испарительную камеру и жидкий металл в качестве термоинтерфейса для GPU. В отличие от модели Founders Edition версия ProArt дополнительно оснащена видеовыходом USB Type-C.  От Founders Edition модель от Asus также отличается частотами графического процессора. В «стандартном» режиме для чипа заявлена частота 2482 МГц в режиме Boost. В режиме «разгона», доступном через фирменную утилиту GPU Tweak III, указана частота 2512 МГц. Для сравнения, для RTX 5090 Founders Edition заявлена частота 2,41 ГГц в режиме Boost.  Помимо USB Type-C, в набор внешних разъёмов видеокарты от Asus входят один HDMI 2.1b и два DisplayPort 2.1b. Размеры карты составляют 304 × 140 × 50 мм. Её толщина соответствует 2,5 слота расширения, а потому обеспечивается совместимость с компактными SFF-системами. Asus рекомендует использовать с картой блок питания мощностью от 1200 Вт.  Производитель не сообщил, когда карта поступит в продажу. Её стоимость также неизвестна. Рекомендованная цена RTX 5090 от Nvidia по-прежнему составляет $1999, однако текущая реальная розничная стоимость версий данного ускорителя обычно как минимум на $1500 выше. Nvidia похвалилась, что Blackwell удешевили инференс нейросетей до 10 раз — и это заслуга не только «железа»
13.02.2026 [16:42],
Павел Котов
С развёртыванием ускорителей искусственного интеллекта на архитектуре Nvidia Blackwell стоимость инференса, то есть запуска обученных систем ИИ, удалось сократить в 4–10 раз. Такие данные привела сама Nvidia. Но за счёт одной только аппаратной части добиться подобных результатов не получилось бы. 
Источник изображений: nvidia.com Значительного снижения затрат удалось добиться за счёт запуска ускорителей на архитектуре Nvidia Blackwell и моделей с открытым исходным кодом в инфраструктуре облачных операторов Baseten, DeepInfra, Fireworks AI и Together AI для задач, связанных со здравоохранением, играми, агентским ИИ и обслуживанием клиентов. Ещё один фактор — оптимизированные программные стеки. Перевод оборудования на Nvidia Blackwell помог сократить стоимость инференса вдвое по сравнению с ускорителями предыдущего поколения, а дальнейшему снижению затрат способствовал перевод систем в форматы пониженной точности, такие как NVFP4. Компания Sully.ai добилась сокращения затрат на вывод данных ИИ в области здравоохранения на 90 %, то есть в десять раз; время отклика улучшилось на 65 % за счёт перехода от закрытых к открытым моделям ИИ в инфраструктуре Baseten. Автоматизация задач по написанию кода и ведению медицинских записей помогла сэкономить специалистам 30 млн минут рабочего времени. Latitude на своей платформе AI Dungeon сократила затраты на вывод данных ИИ в четыре раза. Для этого она запустила в инфраструктуре DeepInfra модели с конфигурацией «смеси экспертов» (MoE), снизив стоимость 1 млн токенов с $0,20 до $0,10, а перевод системы на низкоточный формат данных NVFP4 помог сократить цену до $0,05.  Sentient Foundation повысила экономическую эффективность платформы агентного чата на 25–50 % за счёт оптимизированного для Blackwell стека обработки данных Fireworks AI — платформа управления сложными рабочими процессами в неделю вирусного запуска обработала 5,6 млн запросов без ущерба для величины задержки. Decagon шестикратно снизила затраты на запрос для голосовой поддержки клиентов с ИИ, запустив многомодельный стек в инфраструктуре Together AI на ускорителях Blackwell. Время ответа сохранялось менее 400 мс даже при обработке нескольких тысяч токенов на запрос, что критически важно при голосовом взаимодействии, когда клиенты в любой момент могут прервать разговор. Значение имеют характеристики рабочей нагрузки. ИИ-ускорители Blackwell успешно работают с «рассуждающими» ИИ-моделями, потому что для получения более качественных ответов те генерируют большее число токенов. Платформы эффективно обрабатывают эти расширенные последовательности за счёт дезагрегированного обслуживания — отдельной обработки предварительного заполнения контекста и собственно генерации токенов. При оценке затрат эти аспекты следует учитывать: при высоких объёмах генерации токенов можно добиться десятикратного повышения эффективности; уменьшенная генерация токенов в моделях высокой плотности ведёт лишь к четырёхкратному росту показателей. В приведённых выше примерах речь идёт об ускорителях Nvidia Blackwell, но есть и альтернативные способы снижения затрат на вывод данных. Например, перевод систем на ускорители AMD Instinct MI300, Google TPU, а также специализированное оборудование Groq и Cerebras. Собственные средства оптимизации развёртывают и облачные провайдеры. Поэтому вопрос не в том, является ли архитектура Blackwell единственным вариантом, а в том, соответствует ли конкретное сочетание оборудования, ПО и моделей ИИ требованиям конкретной рабочей нагрузки. Новых GeForce RTX пока не будет, — а заодно Nvidia сократит выпуск существующих видеокарт на 30–40 %
06.02.2026 [10:07],
Алексей Разин
Бум систем ИИ вызвал не только дефицит памяти, но и высокий спрос на ускорители вычислений Nvidia, поэтому для этой компании выгоднее сосредоточиться именно на последней категории продукции. Как отмечает The Information со ссылкой на собственные источники, впервые в своей новейшей истории Nvidia может пережить текущий год без анонса новых моделей игровых видеокарт. 
Источник изображения: Nvidia Существующие квоты на микросхемы памяти Nvidia намеревается использовать для комплектации востребованных и более прибыльных ускорителей вычислений. Долгое время Nvidia считалась поставщиком игровых решений, но на фоне бума ИИ её приоритеты могли измениться, даже если руководство публично будет настаивать на обратном. Некоторые источники даже сообщают, что и объёмы выпуска игровых видеокарт существующего поколения (GeForce RTX 50) сокращаются из-за дефицита памяти. Нехватка самих видеокарт уже вызвала рост розничных цен по всему миру. Представители Nvidia прокомментировали эту публикацию The Information лишь дежурной фразой о том, что спрос на видеокарты GeForce RTX остаётся высоким, а доступность памяти ограничена. Поставки видеокарт данного семейства продолжаются, а с производителями памяти компания старается работать над улучшением ситуации с доступностью компонентов. По неофициальным данным, первоначально Nvidia в этом году планировала представить обновлённое семейство видеокарт с условным обозначением Kicker, чьи характеристики незначительно бы превосходили GeForce RTX 50, и разработка нового семейства фактически завершена. В декабре руководство компании якобы заявило заинтересованным специалистам, что вывод Kicker на рынок отложен на неопределённый срок. Имеющуюся в условиях дефицита память решено было направить на удовлетворение спроса в серверном сегменте. Скорее всего, анонс более серьёзно обновлённого семейства видеокарт GeForce RTX 60 с архитектурой Rubin, который был запланирован на конец следующего года, тоже будет сдвинут «вправо». В серверном сегменте ускорители с архитектурой Rubin уже выпускаются, они будут доступны клиентам Nvidia со второй половины текущего года. За первые девять месяцев прошлого фискального года игровая выручка компании составляла лишь 8 % от совокупной, хотя до выхода ChatGPT осенью 2022 года эта доля достигала 35 %. Кроме того, на ускорителях вычислений Nvidia зарабатывает гораздо больше (до 65 %), чем на игровых видеокартах в удельном измерении (лишь 40 %). Глава Gigabyte объяснил, почему Nvidia выгоднее производить одни варианты RTX 50 в ущерб другим
16.01.2026 [19:07],
Николай Хижняк
Главный редактор портала Tom's Hardware Пол Алкорн (Paul Alcorn) пообщался на выставке CES 2026 с генеральным директором Gigabyte Эдди Лином (Eddie Lin). В разговоре Лин предположил, что Nvidia будет отдавать приоритет определённым моделям видеокарт GeForce RTX 5000, основываясь на довольно простом расчёте. Если это действительно так, то в этом году рынок может ожидать дефицит некоторых вариантов GeForce RTX 50-й серии. 
Источник изображения: Gigabyte Лин описал возможную стратегию Nvidia по распределению производства графических процессоров в рамках игровой серии Blackwell, которая фокусируется на максимизации прибыли с учётом ограниченных поставок чипов памяти для потребительского сегмента видеокарт. «Они не могут производить только высокопроизводительные или низкопроизводительные [продукты]. Например, у них есть пять сегментов видеокарт. Они фокусируются на первом, третьем и пятом сегментах, снижая в процентном соотношении выпуск второго и четвёртого сегмента, потому второй и четвёртый сегмент приносят меньше выручки в расчёте на один гигабайт используемой памяти. Они будут рассчитывать, какой вклад в выручку [каждый сегмент] вносит в расчёте на гигабайт памяти», — сказал Лин. Он привёл пример условной видеокарты стоимостью $300 (например, та же RTX 5060). Доход с неё, по словам Лина, составит «$35 за каждый гигабайт». Если же взять видеокарту за $400, оснащённую 8 Гбайт памяти, то доход с каждого гигабайта памяти составит $50. Для видеокарты за $500 долларов с 16 Гбайт памяти доход составит всего $32 доллара за один гигабайт памяти, то есть вклад этой карты в общую выручку будет минимальным из трёх. В разговоре с Tom's Hardware Лин заявил, что Gigabyte продолжает получать от Nvidia не только графические процессоры, но и чипы памяти. Ранее появились слухи о том, что Nvidia перестала поставлять комплекты GPU и чипов памяти своим OEM-партнёрам, что может создать серьёзные проблемы для более мелких производителей, поскольку им в таком случае придётся покупать чипы памяти на открытом рынке. Tom's Hardware отмечает, что другие OEM-производители могут быть связаны другими соглашениями и условиями с Nvidia, но на данный момент нет подтверждений от поставщиков видеокарт о том, что Nvidia больше не поставляет память в комплектах. Используя модель Лина, Tom's Hardware создал таблицу, которая позволяет понять, какие видеокарты, скорее всего, будут иметь приоритет в производстве, а какие — будут производиться в 2026 году по остаточному принципу. 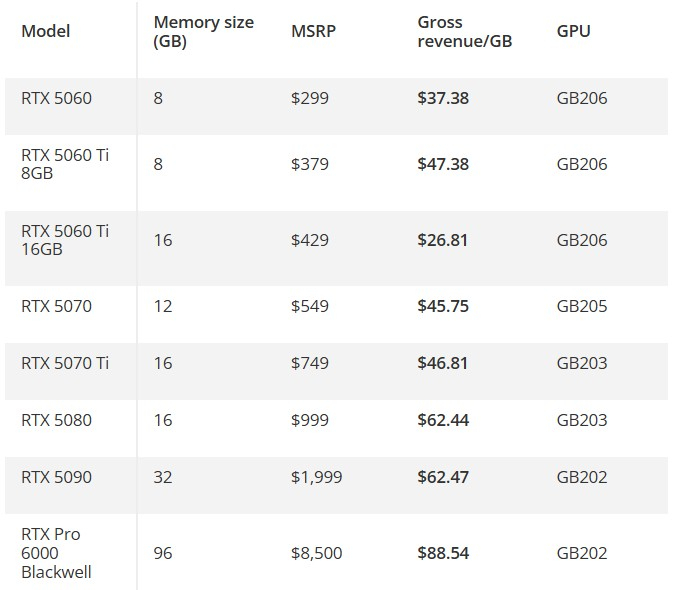
Источник изображения: Tom's Hardware В нижнем ценовом сегменте рынка модель RTX 5060 Ti 8GB приносит $47,38 выручки на гигабайт памяти GDDR7 по сравнению с $37,38 у менее производительной RTX 5060 с тем же объёмом памяти, что означает, что RTX 5060 Ti 8GB, вероятно, будет иметь приоритет при распределении производства, несмотря на крайне слабый интерес потребителей к этой модели. Модель RTX 5060 Ti 16GB является наиболее уязвимой картой из всей группы по этому показателю, поскольку из-за своей рекомендованной розничной цены и большего объёма видеопамяти она приносит всего $26,81 выручки на гигабайт GDDR7 — это самый низкий показатель среди всех карт серии RTX 50. В верхнем ценовом сегменте модели RTX 5070 и RTX 5070 Ti приносят одинаковую выручку за гигабайт используемой памяти, что означает, что более дешёвая в производстве RTX 5070, вероятно, будет предпочтительнее версии Ti (которая использует более крупный и энергоёмкий графический процессор и более сложную конструкцию платы). Или же обе карты по приоритету производства окажутся ниже более прибыльной RTX 5060 Ti 8GB. В верхнем сегменте модели RTX 5080 и RTX 5090 приносят почти одинаковый размер выручки в пересчёте на гигабайт видеопамяти, что означает, что RTX 5080, вероятно, получит приоритет при распределении 2-гигабайтных чипов GDDR7 в будущем из-за меньшего размера графического процессора (вдвое меньше, чем у RTX 5090) и гораздо менее сложной конструкции платы. Старшая карта оснащается 32 Гбайт памяти. Это означает, можно выпустить две более простые по схемотехнике 16-гигабайтные RTX 5080, что одновременно позволило бы увеличить объём предложений для более ходовой модели и, возможно, привело бы к увеличению прибыли. Модели RTX 5090 и RTX Pro 6000 Blackwell используют один и тот же графический процессор GB202 (хотя и с разным количеством SM-блоков), но даже с 96 Гбайт памяти GDDR7 на борту RTX Pro 6000 приносит на целых 41 % больше выручки на каждый гигабайт используемой памяти GDDR7 по сравнению с RTX 5090. Здесь важно отметить, что в составе RTX Pro 6000 использует 3-гигабайтные чипы GDDR7, распаянные с обеих сторон платы видеокарты для достижения общей ёмкости в 96 Гбайт, а не 2-гигабайные микросхемы, которые у RTX 5090 находятся на одной стороне платы, поэтому это не совсем корректное сравнение. И всё же это может объяснить, почему Nvidia, скорее всего, не просто перенесла запуск обновлённых моделей видеокарт RTX 50 Super, а отказалась от их выпуска. Маржа, обеспечиваемая использованием 3-гигабайтных чипов в продуктах RTX Pro гораздо привлекательнее, чем могла бы быть для GeForce RTX, которые, предположительно, продавались бы по ценам, близким к ценам на карты без приставки Super на момент их запуска. Портал Tom’s Hardware ожидает, что в перспективе модели RTX 5060 Ti 8GB, RTX 5070 и RTX 5080 будут относительно более доступными в продаже, в то время как популярные среди энтузиастов модели RTX 5060 Ti 16GB и RTX 5070 Ti окажутся в дефиците. Ситуация с RTX 5090 также очевидна. Количество предложений даже в интернет-магазинах резко сокращаются, а цены на эти модели быстро растут. Китайские власти ещё не разрешили местным разработчикам закупку Nvidia H200, но уже интересуются, потребуется ли им Blackwell
15.01.2026 [08:54],
Алексей Разин
Накануне уже сообщалось, что китайские таможенные органы пока не готовы разрешить массовый ввоз в страну ускорителей Nvidia H200, поставки которых номинально одобрила американская сторона. Изданию Nikkei Asian Review удалось выяснить другие подробности условий, на которых импорт ускорителей Nvidia может быть разрешён в Китай. 
Источник изображения: Nvidia Во-первых, окончательные правила пока не сформулированы, и в ходе работы над ними власти КНР стараются консультироваться с конечными пользователями подобных ускорителей вычислений. В частности, чиновники пытаются понять, насколько критичен для китайских разработчиков доступ к импортным ускорителям, и насколько эффективными могут быть отечественные аналоги. Предполагается, что при работе с инференсом и развёртывании инфраструктуры под уже обученные языковые модели вполне достаточными будут характеристики ускорителей китайского производства. В подобных случаях разработчикам предстоит обосновать свою потребность в импортных ускорителях. Во-вторых, ожидается, что разрешение на поставку первой немногочисленной партии H200 в Китай будет получено от местных властей в конце текущего месяца, но чиновники могут ограничить количество доступных ускорителей для каждой из нуждающихся компаний. Другой вариант схемы импорта ИИ-чипов в Китай предусматривает определённую пропорцию зарубежных ускорителей и выпускаемых местными компаниями. В этом случае закупающие импортные решения китайские разработчики будут обязаны в нагрузку приобрести некоторое количество местных ускорителей. Самое интересное, что китайские чиновники в общении с технологическими компаниями Поднебесной начали изучать потенциальный спрос на ускорители Nvidia поколения Blackwell, которые эта компания надеялась поставить в Китай ещё летом прошлого года, но русло переговоров с властями США привело к разрешению на поставки ускорителей H200 с более зрелой архитектурой Hopper. Напомним, недавно глава Nvidia Дженсен Хуанг (Jensen Huang) заявил, что хотел бы наладить поставки в Китай не только ускорителей Blackwell, но и следующих за ними Rubin. Правда, это станет возможным только при условии, что клиентам в США к тому времени будут доступны более совершенные ускорители. Дженсен Хуанг показал ускорители Rubin на CES 2026 — их массовое производство уже запущено
06.01.2026 [07:51],
Алексей Разин
Вполне предсказуемо, что основатель и генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) трибуну CES 2026 использовал не только для рассказа о новейших продуктах и технологиях компании, но и для убеждения инвесторов в том, что ИИ-пузырь далёк от схлопывания. Одним из аргументов стала демонстрация образцов ускорителей с архитектурой Rubin. 
Источник изображения: Nikkei Asian Review Они выйдут на рынок в этом году, во второй его половине, но глава Nvidia подчеркнул, что их производство уже идёт полным ходом. Архитектура Rubin является преемником весьма успешной Blackwell, и Nvidia не скрывает, что связывает с ней особые надежды. Отвечая на вопросы аудитории на CES 2026, основатель компании пояснил: «Мы попытаемся наращивать поставки изо всех сил. Во втором полугодии мы будет продавать много, поставлять много (ускорителей Rubin)». По сравнению с Blackwell, ускорители Rubin обеспечат рост производительности в инференсе в пять раз, а также в три с половиной раза в обучении языковых моделей. В обеих сферах удельная стоимость генерируемого токена сократится в десять раз по сравнению с Blackwell, поэтому разработчикам будет выгодно переходить на Rubin даже в том случае, если новые ускорители окажутся заметно дороже старых. 
Источник изображения: Nvidia Непосредственно графические процессоры поколения Rubin станут первыми продуктами Nvidia с памятью типа HBM4, которая обеспечит скорость передачи информации до 22 терабайт в секунду. Одними из первых клиентов Nvidia, получивших ускорители Rubin во втором полугодии, станут облачные провайдеры CoreWeave и Microsoft Azure. Образцы ускорителей Rubin уже вовсю тестируются клиентами Nvidia. В одной серверной стойке могут объединяться до 72 графических процессоров Rubin и 36 центральных процессоров Vera. В одном вычислительном кластере могут объединяться до 1000 чипов Rubin, эффективность обмена данными между ними будет во многом определяться новыми сетевыми интерфейсами, которые были представлены параллельно. При работе в инференсе с форматом данных NVFP4, который Nvidia будет продвигать, ускорители Rubin обеспечивают быстродействие на уровне 50 петафлопс. Кратное повышение производительности и эффективности вычислений по сравнению с Blackwell было достигнуто при всего лишь 1,6-кратном увеличении количества транзисторов на чипе. Gigabyte выпустила GeForce RTX 5070 Ti WindForce OC V2 — меньше первой версии и без сомнительного термогеля
22.12.2025 [21:43],
Николай Хижняк
Компания Gigabyte представила новую версию GeForce RTX 5070 Ti WindForce OC V2 16G (модель GV-N507TWF3OCV2-16GD). Новинка отличается от оригинальной модели WindForce OC размерами, а также изменениями в конструкции системы охлаждения. 
Источник изображений: VideoCardz / Gigabyte GeForce RTX 5070 Ti WindForce OC V2 16G предлагает те же заводские настройки разгона для GPU (Boost-частота 2497 МГц), что и существующая модель WindForce OC SFF для компактных ПК, а также оснащена 16 Гбайт памяти GDDR7 со скоростью 28 Гбит/с на контакт и поддержкой 256-битной шины. 
Gigabyte GeForce RTX 5070 Ti WindForce V2 
оригинальная Gigabyte GeForce RTX 5070 Ti WindForce В описании модели V2 говорится, что карта оснащена тремя 80-мм вентиляторами и восемью композитными теплотрубками, а её радиатор имеет медную основу. Характеристики также подтверждают, что карта сохранила толщину оригинальной модели (50 мм) и ту же высоту (126 мм), однако версия V2 стала значительно короче. Её длина составляет 261 мм против 304 мм у оригинальной модели WindForce OC. 
Gigabyte GeForce RTX 5070 Ti WindForce V2 Примечательно, что нигде в описании GeForce RTX 5070 Ti WindForce OC V2 16G не упоминается использование «термогеля серверного уровня» в качестве термоинтерфейса, который присутствует у других моделей видеокарт RTX 50 от Gigabyte. Например, на странице модели GeForce RTX 5070 Ti WindForce OC SFF есть упоминание термогеля. 
оригинальная Gigabyte GeForce RTX 5070 Ti WindForce Ранее сообщалось, что некоторые пользователи столкнулись с вытеканием термогеля из видеокарт Gigabyte. Компания признала проблему, сообщив, что в первых партиях ускорителей было нанесено избыточное количество термогеля, и пообещала пересмотреть объём термоинтерфейса в последующих партиях. Более того, сам по себе термогель оказался менее эффективен в охлаждении по сравнению с обычными термопрокладками, что было показано на примере видеокарты Gigabyte Aorus Radeon RX 9070 XT Elite 16G. Китайская Tencent получила доступ к 15 000 санкционных ИИ-чипов Nvidia Blackwell через Японию
22.12.2025 [08:12],
Алексей Разин
Не секрет, что нуждающиеся в доступе к передовым ускорителям вычислений западного производства китайские компании прибегают к аренде зарубежных облачных мощностей, чтобы избежать полного влияния американских санкций. Один из японских владельцев ЦОД на контрактах с китайской Tencent по этой схеме смог получить контракты на более чем $1,2 млрд. 
Источник изображения: Nvidia Как поясняет Financial Times, китайский гигант взаимодействует с японской Datasection через посредника, стараясь не слишком афишировать подобное сотрудничество, но эта схеме позволяет Tencent использовать основную часть из 15 000 ускорителей Nvidia с архитектурой Blackwell, которые установлены в ЦОД первой из компаний на территории Японии. В таком варианте доступа к вычислительным мощностям со стороны китайского разработчика нет ничего противозаконного, поскольку при Трампе власти США начали закрывать на такие проявления деятельности китайских компаний глаза. Тем не менее, лишнее внимание способно вызвать изменения в обстановке, которые для Tencent нежелательны. Характерно, что контракт с Tencent превратил Datasection в одного из крупнейших провайдеров на рынке «neocloud» в Азии, которые зарабатывают на аренде имеющихся у них вычислительных мощностей. Изначально Datasection работала в сфере маркетинговых услуг и строила ЦОД недалеко от Осаки для собственных нужд, но сдача их в аренду китайским клиентам оказалась более выгодным бизнесом. По словам главы Datasection Норихико Исихары (Norihiko Ishihara), ещё полгода назад для поддержания ИИ-модели было достаточно 5000 ускорителей Nvidia B200, а сейчас эта цифра как минимум удвоилась. Это предъявляет к участникам бизнеса особые требования. По оценкам аналитиков Bernstein Research, флагманские чипы Huawei и Alibaba обеспечивают около трети уровня производительности Nvidia B200, поэтому спрос на них в Китае сохраняется. Даже не самые современные H200, поставки которых США недавно разрешили в КНР, оказываются почти на четверть быстрее китайских лидеров. При этом первые примерно в четыре раза уступают передовым Nvidia B300, поставки которых в Китай запрещены. Как отмечается, японская Datasection свою сделку с Tencent через посредника заключила уже после того, как в мае Дональд Трамп (Donald Trump) отменил запрет на аренду зарубежных вычислительных мощностей китайскими компаниями. На первом этапе Datasection собирается на протяжении трёх лет сдавать в аренду 15 000 ускорителей Nvidia для нужд Tencent. В дальнейшем профильные мощности вырастут до более чем 100 000 ускорителей. Официально представители Datasection отрицают своё сотрудничество с китайской Tencent. Партия из 5000 ускорителей Nvidia B200 обошлась японской компании примерно в $272 млн по состоянию на июль этого года. За свой трёхлетний контракт с клиентом она при этом должна выручить $406 млн. Второй контракт на три года подразумевает получение $800 млн, которые будут направлены на строительство второго ЦОД, расположенного в Сиднее. Австралийская площадка разместит десятки тысяч передовых ускорителей Nvidia B300. Первая партия из 10 000 таких ускорителей будет стоить Datasection примерно $521 млн. По неофициальным данным, мощности австралийского ЦОД также будут использоваться преимущественно Tencent в ближайшие годы. Китайская компания утверждает, что использование зарубежных ЦОД никак не нарушает законы вовлечённых в процесс стран. Для провайдера в данном случае важно отбить затраты на закупку ускорителей. Как правило, срок амортизации рассчитан на пять лет, тогда как контракты заключаются на три года, но клиенты могут продлить их ещё на два года. Datasection оставляет за собой право разорвать соглашение с китайскими клиентами, если того потребуют изменения в законодательстве. По словам руководства компании, использование ускорителей Nvidia китайскими клиентами согласовано как с самим поставщиком, так с Министерством торговли США. Datasection намерена развивать ЦОД и на территории Европы, при этом потепления отношений между США и КНР компания не очень боится, поскольку в случае отказа китайских клиентов от аренды ЦОД она быстро найдёт новых, ведь спрос на инфраструктуру ИИ сейчас очень высок. В самом неблагоприятном случае, по словам провайдера, деятельность придётся остановить всего лишь на неделю. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex








