|
Опрос
|
реклама
Быстрый переход
OpenAI опробовала рекламу в ChatGPT — она уже может приносить более $100 млн в год
27.03.2026 [07:03],
Алексей Разин
Исчерпав возможности привлечения капитала в прежних объёмах, OpenAI начинает формировать более благопристойное впечатление о себе в глазах инвесторов. В поисках путей монетизации своих услуг, стартап пару месяцев назад запустил в США пилотный проект по демонстрации рекламы пользователям. Представители OpenAI говорят, что в годовом выражении выручка компании от рекламы уже может превышать $100 млн. 
Источник изображения: OpenAI Ещё в январе OpenAI начала демонстрировать рекламу подписчикам тарифа ChatGPT Go и пользователям бесплатного варианта этого чат-бота. По словам представителей OpenAI, на которые ссылается CNBC, компания работает с более чем 600 рекламодателями, не наблюдая каких-либо проблем, касающихся конфиденциальности передаваемых им данных о привычках и предпочтениях пользователей. Сейчас OpenAI рассматривает идею начала демонстрации рекламы пользователям ChatGPT в Австралии, Канаде и Новой Зеландии. Демонстрацию рекламы даже в подходящих для этого тарифах подписки OpenAI ограничивает определёнными правилами. Пользователям младше 18 лет она не демонстрируется, прочие видят её под ответом чат-бота с явной маркировкой. При обсуждении ряда тем типа политики и здоровья, включая ментальное, реклама также не демонстрируется в ChatGPT. На содержание ответа чат-бота реклама тоже не влияет, по словам представителей OpenAI. В США около 85 % пользователей бесплатного тарифа ChatGPT и версии Go являются аудиторией, которой демонстрируется реклама, но на ежедневной основе не более 20 % пользователей её просматривают. Медленное развёртывание рекламного бизнеса OpenAI в компании объясняют необходимостью тщательной проработки всех деталей. Как отмечают в OpenAI, «ранние сигналы от пользователей и участвующих брендов воодушевляют нас, мы продолжаем видеть сильную заинтересованность со стороны рекламодателей». OpenAI передумала развращать ChatGPT — проект ИИ-бота для взрослых отправили «в долгий ящик»
26.03.2026 [16:51],
Алексей Разин
Усилия руководства OpenAI по оптимизации бизнес-стратегии начинают определять те приоритетные направления развития стартапа, которые достойны запланированных многомиллиардных инвестиций. Вслед за неожиданным отказом от поддержки ИИ-генератора видео Sora, как отмечает Financial Times, компания решила отложить в «долгий ящик» и проект эротического чат-бота. 
Источник изображения: Unsplash, Brian Lawson Прошлая публикация на эту тему позволяет понять, что темой запуска эротических ИИ-сервисов OpenAI интересуется уже на протяжении нескольких лет, и после длительных колебаний воплотить эти планы в жизнь сперва было решено до конца первого квартала текущего года, но недавно стало известно, что в этой сфере возникает задержка как минимум на месяц. Теперь Financial Times со ссылкой на осведомлённые источники заявляет, что проект эротической направленности отложен в «долгий ящик» на неопределённое время, поскольку инвесторы и сами сотрудники OpenAI выражают глубокую озабоченность его вероятными социальными и экономическими последствиями. Внутри стартапа даже высказываются мнения о необходимости полностью отказаться от идеи запуска эротического чат-бота. Растёт беспокойство связанных с OpenAI лиц по поводу усиления нездоровой атмосферы вокруг чат-бота, а также последствий получения доступа к взрослому контенту со стороны несовершеннолетних пользователей. Представители OpenAI в комментариях Financial Times подтвердили, что эротическая ИИ-модель отложена по срокам реализации на неопределённое время. Прежде чем принять какие-то решения о жизнеспособности проекта, OpenAI хочет провести глубокое исследование по поводу его возможного влияния на общество. Каких-либо эмпирических данных на этот счёт до сих пор не существует, поэтому к изучению проблемы важно подойти досконально. Кроме того, распылять ресурсы на второстепенные инициативы OpenAI сейчас не желает, предпочитая сосредоточиться на разработке ИИ-инструментов для повышения производительности умственного труда и их монетизации. По некоторым данным, самые востребованные свои инструменты создатели ChatGPT намерены объединить в мощном настольном приложении. Выпуск платформы с эротическим уклоном мог бы вызвать неоднозначную реакцию аудитории в ближайшее время, поскольку на фоне скандала с «раздевающим» людей чат-ботом Grok компании xAI внимание регуляторов к этой теме резко возросло. Выход апеллирующего к теме эротики ИИ-решения OpenAI мог бы насторожить инвесторов с учётом планируемого IPO компании. Тем более, что перспективы серьёзной монетизации такого продукта многим из них тоже кажутся сомнительными. Наконец, создание такого продукта могло бы натолкнуться на чисто технические трудности. Годами ChatGPT развивался с учётом определённых этических ограничений, а для реализации «эротического проекта» их пришлось бы выборочно снимать, причём с сохранением категорической блокировки некоторых табуируемых в обществе тем. Сохранить оптимальный баланс между жизнеспособностью такой модели и её безопасностью было бы крайне сложно. Недавно модернизированная система верификации возраста пользователей по-прежнему даёт сбой в более чем 10 % случаев. Это означает, что миллионы несовершеннолетних могли бы получить доступ к контенту для взрослых, и подобные факты повлекли бы серьёзные юридические риски для OpenAI. ChatGPT научился давать прогноз погоды на срок до 10 дней с помощью AccuWeather
25.03.2026 [15:26],
Дмитрий Федоров
AccuWeather запустила приложение для ChatGPT, которое добавляет в сервис информацию о текущей погоде в заданной точке, прогноз на срок до 10 дней, сведения с учётом исторических данных и официальные предупреждения, связанные с погодой. Это помогает лучше планировать прогулки и поездки и, по замыслу разработчиков, должно снизить вероятность неточных ответов ChatGPT о погоде. 
Источник изображения: accuweather.com Для доступа к функции пользователю необходимо подключить приложение AccuWeather к своему профилю ChatGPT. После этого запрос оформляется через символ @: пользователь выбирает AccuWeather и затем вводит запрос, который приложение должно обработать. 
Источник изображения: chatgpt.com Иными словами, речь идёт не просто об улучшении ИИ-модели, а о явной связке ChatGPT с внешним погодным сервисом, доступ к которому инициирует сам пользователь. 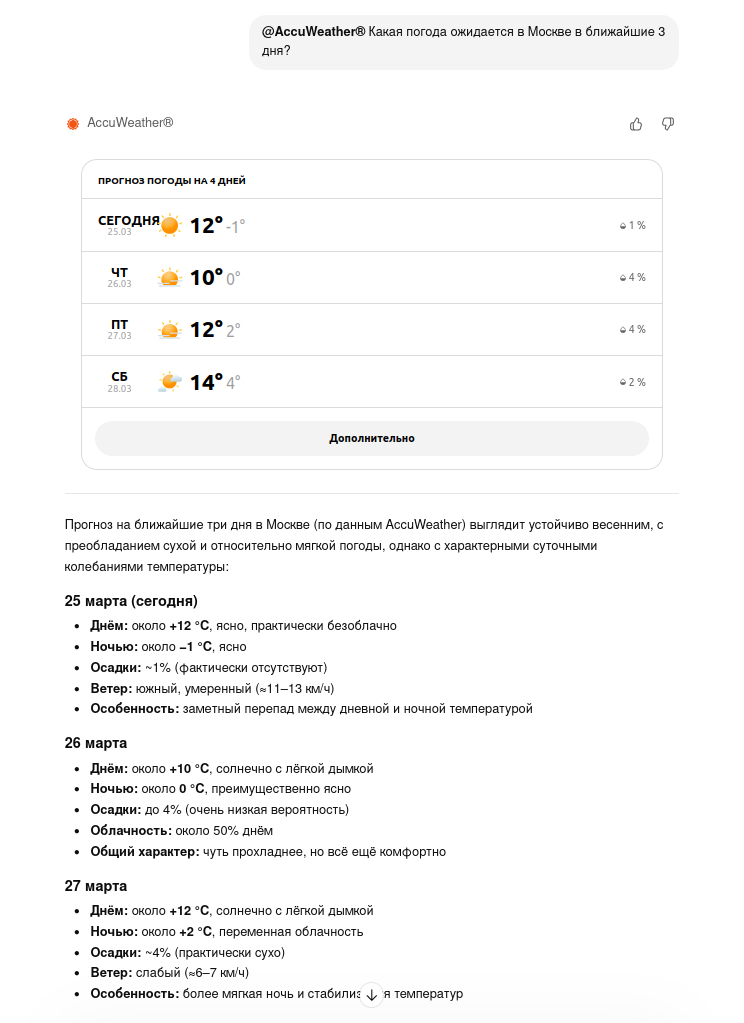
Источник изображения: chatgpt.com Запуск приложения последовал вскоре после объявления OpenAI о прекращении развития Sora. После этого изменения OpenAI ограничит генерацию видео платными тарифами в ChatGPT и сторонними инструментами через API. OpenAI представила ChatGPT Library — облачное хранилище, которое доступно не всем
24.03.2026 [11:22],
Павел Котов
OpenAI представила новую функцию Library для ChatGPT — возможность держать личные файлы и изображения в облачном хранилище платформы. Воспользоваться ChatGPT Library могут подписчики версий Plus, Pro и Business; новая функция доступна пользователям по всему миру за исключением Швейцарии, Великобритании и стран Европейской экономической зоны. 
Источник изображения: Dima Solomin / unsplash.com Раздел Library уже начал появляться в боковой панели веб-версии ChatGPT — в хранилище уже помещены некоторые файлы, которые пользователи загружали ранее в чат. По умолчанию данные из переписки попадают в безопасное хранилище и могут использоваться в качестве справочных материалов в будущих чатах. Генерируемые чат-ботом изображения по-прежнему отображаются в соответствующей вкладке на боковой панели. Уже присутствующие в ChatGPT Library файлы можно быстро добавлять в чат для анализа ИИ или в качестве контекста. Есть также возможность удалять их из хранилища — для этого напротив каждого файла появляется значок с изображением корзины. Удалённые из хранилища файлы сохраняются на серверах OpenAI ещё в течение 30 дней. В компании не объяснили, почему система работает подобным образом — возможно, тому есть юридические причины. OpenAI планирует удвоить штат ради укрепления корпоративных продаж ChatGPT
22.03.2026 [07:35],
Дмитрий Федоров
К концу 2026 года OpenAI готовит почти двукратное расширение штата. Параллельно стартап с оценкой капитализации в $730 млрд усиливает продажи корпоративным клиентам, расширяет офисные площади в Сан-Франциско и меняет продуктовые приоритеты, пытаясь сократить отставание от Anthropic и укрепить позиции в корпоративном сегменте, где Anthropic в последние месяцы наращивает преимущество, а также сдержать давление со стороны Google. 
Источник изображения: openai.com По данным источников, компания намерена увеличить численность сотрудников примерно с 4 500 до 8 000 человек к концу 2026 года. Новые сотрудники, как ожидается, будут наняты прежде всего в продуктовые, инженерные, исследовательские и коммерческие подразделения. Отдельный акцент компания делает на специалистах по техническому сопровождению внедрения. Их задача — помогать заказчикам быстрее интегрировать инструменты OpenAI в рабочие процессы и повышать прикладную отдачу от использования ИИ. Компания заключила новый договор аренды в Сан-Франциско, увеличив общий объём занимаемых площадей в городе до 92 903 м2. По словам источников, в 2026 году компания рассчитывает расти примерно на 12 сотрудников в день. Такой темп указывает на системное масштабирование, а не на донабор отдельных команд. Перестройка связана с ухудшением позиций OpenAI в корпоративных продажах. По данным финтех-компании Ramp с более чем 50 000 клиентов, компании, впервые закупающие решения на базе ИИ, выбирают Anthropic в 3 раза чаще, чем OpenAI. Год назад ситуация была обратной. В OpenAI с такой оценкой не согласны. Представитель компании заявил, что делать выводы о доле корпоративного рынка на основе данных платежей по банковским картам некорректно, поскольку крупные клиенты не оплачивают многомиллионные контракты картами и, вероятно, вообще не используют Ramp для таких платежей. В конце 2025 года генеральный директор OpenAI Сэм Альтман (Sam Altman), как сообщалось, объявил внутри компании о всеобщей мобилизации ресурсов и потребовал вернуть фокус на ключевой продукт — ChatGPT. В марте 2026 года руководитель прикладного бизнеса OpenAI Фиджи Симо (Fidji Simo) призвала сотрудников отказаться от второстепенных задач и сосредоточиться на трёх направлениях: развитии Codex, расширении корпоративной клиентской базы и превращении ChatGPT в полноценный инструмент продуктивной работы. 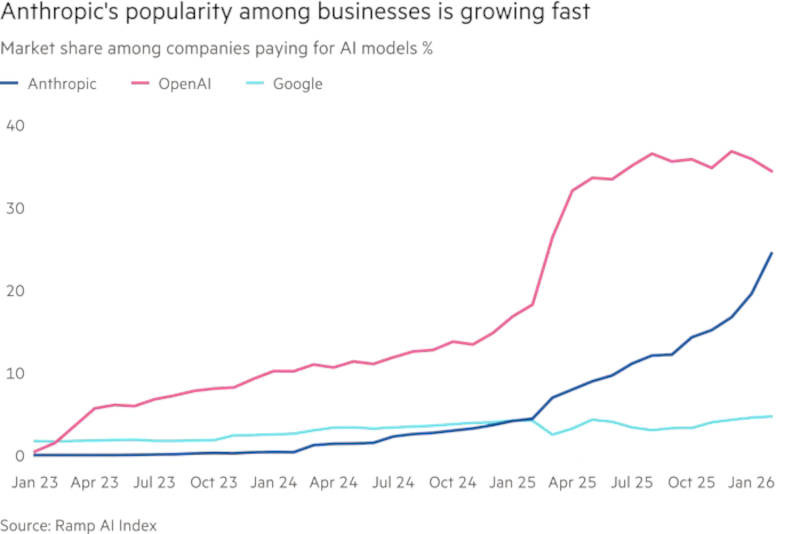
Anthropic быстро наращивает долю в корпоративном ИИ. Источник изображения: ramp.com Симо также курирует объединение Codex и ChatGPT в единое настольное приложение, которое планируется продавать как частным пользователям, так и компаниям. Параллельно OpenAI обсуждает с инвестиционными фондами создание совместного предприятия для внедрения своих продуктов в портфельных компаниях этих фондов. Для компании это способ быстрее расширить присутствие в корпоративной среде. ChatGPT остаётся самым успешным массовым приложением в сфере генеративного ИИ с момента запуска в 2023 году. При этом более 90 % из не менее чем 900 млн пользователей, регулярно взаимодействующих с сервисом, не платят OpenAI. Компания располагает огромной аудиторией, но значительная её часть не формирует выручку. Поэтому OpenAI одновременно ищет способы монетизации массовой базы, включая рекламу, и усиливает корпоративные продажи, где контракты крупнее и выручка устойчивее. Anthropic с самого начала выбрала более узкую стратегию. Основанная в 2021 году бывшими исследователями OpenAI, компания сделала ставку прежде всего на корпоративных заказчиков. После запуска Claude Code эта стратегия, по данным источников, начала приносить особенно быстрый результат: в 2026 году Anthropic еженедельно увеличивала годовой темп выручки на $1 млрд. Это один из факторов, заставивших OpenAI ускорить пересмотр приоритетов. При этом ни OpenAI, ни Anthropic пока не вышли на прибыльность. Обе компании тратят на обучение ИИ-моделей на миллиарды долларов больше, чем зарабатывают. На этом фоне для них критически важно одновременно удерживать технологический темп, сокращать издержки, наращивать выручку и приближаться к прибыли, особенно с учётом возможной подготовки к публичному размещению акций (IPO) уже в 2026 году. 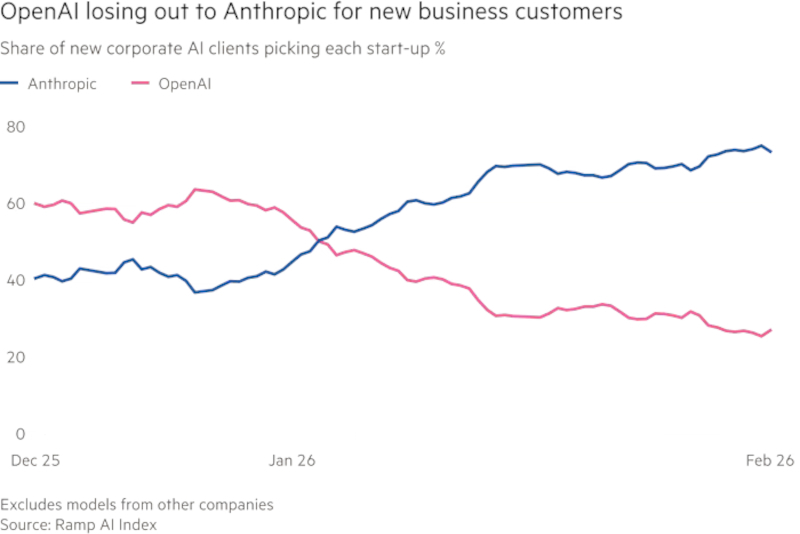
Anthropic опережает OpenAI у новых корпоративных клиентов. Источник изображения: ramp.com Следствием этого стало и быстрое распространение практики найма инженеров, работающих непосредственно у заказчика. Такие специалисты помогают адаптировать ИИ-модели, настраивать интеграции и ускорять внедрение. Подход, который раньше активно использовала Palantir, становится одним из стандартов рынка генеративного ИИ. OpenAI рассчитывает, что к концу 2026 года около 50 % её выручки будет приходиться на корпоративных клиентов против примерно 40 % сейчас. Это означает, что корпоративный сегмент становится опорной частью её финансовой модели. Внутри OpenAI новый акцент связывают прежде всего с успехом инструментов для программирования, таких как Claude Code и Codex. По словам одного из руководителей компании, именно эти продукты открыли для бизнеса новые направления роста и заставили OpenAI изменить представление о том, как строить продуктовую линейку и работать с рынком. Риск этой стратегии в том, что OpenAI приходится одновременно догонять Anthropic в корпоративном сегменте и удерживать позиции в массовом рынке, где с высокой интенсивностью конкурирует Google. Именно поэтому нынешнее расширение штата, рост офисных площадей и смещение продуктового фокуса следует рассматривать не как обычный этап развития, а как попытку заново определить место компании на быстро меняющемся рынке. Пользователи бесплатного режима ChatGPT в США в ближайшие недели столкнутся с необходимостью просматривать рекламу
22.03.2026 [06:27],
Алексей Разин
Для многих видов бизнеса, связанных с интернетом и информационным технологиями, продажа рекламы исторически являлась одним из важных источников дохода. ChatGPT в этом отношении долго баловал пользователей, но в ближайшие недели им придётся столкнуться с необходимостью просмотра рекламы — по крайней мере, в США. 
Источник изображения: Unsplash, Levart_Photographer Об этом первоначально сообщило издание The Information, а Reuters удалось подтвердить эти данные в самой OpenAI. Демонстрация рекламы скоро будет осуществляться всем пользователям ChatGPT в США, которые выбрали либо бесплатный вариант доступа к чат-боту, либо предпочли тарифный план подписки Go. Для интеграции рекламы OpenAI привлекла специализирующуюся на таких услугах компанию Criteo. На территории США партнёры реализуют пилотный проект по монетизации ChatGPT через рекламу. Сейчас Criteo занимается отбором рекламодателей, которые готовы потратить на размещение рекламы от $50 000 до $100 000, им предоставляются все сопутствующие услуги. По мнению OpenAI, увеличение разнообразия текстовых и визуальных рекламных материалов позволяет повысить частоту их демонстрации и саму эффективность рекламы. Для OpenAI продажа рекламы в ChatGPT должна стать одним из источников выручки, в дополнение к поступлениям от подписок. Расходы компании на развитие вычислительной инфраструктуры и разработку новых ИИ-моделей до сих пор значительно превышают доходы, но руководство это не особо беспокоит, пока оно находит желающих покрывать её многомиллиардные затраты инвесторов. Реклама в ChatGPT забуксовала: крупные агентства вложили сотни тысяч, но аудитории не хватает
21.03.2026 [17:06],
Павел Котов
Когда OpenAI впервые объявила о намерении запустить рекламу в ChatGPT, крупнейшие агентства изъявили желание протестировать новый формат, чтобы разработать рекламные стратегии показов на платформах искусственного интеллекта, сообщает CNBC. 
Источник изображения: BoliviaInteligente / unsplash.com В программе тестирования приняли участие три крупнейших в мире рекламных агентства: WPP, Omnicom и Dentsu. Программа развивается очень медленно, чтобы оправдать ожидания, — OpenAI слишком неспешно расширяет аудиторию. Требуемые для участия в тестировании рекламные обязательства оказались необычно высокими для экспериментальных форматов — некоторые бренды выделили на проект от $200 тыс. до $250 тыс., что вдвое превышает типичные для экспериментов объёмы. Пилотная программа продлится до конца марта, и уже есть мнение, что средства не будут освоены в полной мере. OpenAI, конечно, вернёт все излишки, но бюджеты в крупных организациях уже были выделены на пробный период, и до конца квартала потратить эти деньги на другие цели не выйдет. Плюс рекламодатели не получат того объёма аналитических данных, на который рассчитывали. «Мы находимся на раннем этапе тестирования рекламы в ChatGPT, и сейчас наша цель — изучить и улучшить схемы работы пользователей, прежде чем расширяться на более широкую аудиторию. Нас обнадёжили первые отзывы пользователей и участвующих брендов, мы продолжаем отмечать высокий интерес со стороны рекламодателей», — заявили в OpenAI. В Dentsu отметили, что хотят и дальше участвовать в тестировании нового формата совместно с разработчиком ChatGPT. Другие компании положительно оценили оперативность, с которой OpenAI вносит изменения, а в последнее время и наращивает темпы. Осторожный подход они назвали хорошим признаком стремления выстроить устойчивый и успешный рекламный бизнес. Количество показов рекламы с начала по середину марта выросло на 600 %; в начале месяца её видел 1 % мобильных пользователей ChatGPT, а в середине — 5 %. Аналитики финансовой компании Truist назвали 2026-й «переломным годом» в области рекламы на платформах чат-ботов с ИИ: по итогам текущего года мировая рекламная выручка в этом сегменте будет менее $1 млрд, но уже к 2030 году она превысит $30 млрд. Наиболее эффективной, по мнению Dentsu, она может быть для пользователей ChatGPT с конкретными запросами. Примечательно, что коллеги относятся к рекламе в чат-ботах с осторожностью: Anthropic высмеяла инициативу OpenAI, а Perplexity хотя и тестировала показы с 2024 года, но недавно полностью удалила рекламу со своей платформы. Google не делала официальных объявлений о рекламе в Gemini, но дала понять, что не исключает такого сценария — пока же ей хватает показов в «Обзорах от ИИ». По итогам 2026 года выручка Google от поисковой рекламы, по оценкам Truist, достигнет $252 млрд, и для OpenAI это повод крепко задуматься. OpenAI создаёт настольное суперприложение, объединяющее браузер, ChatGPT и Codex
20.03.2026 [08:03],
Алексей Разин
Усилия руководства OpenAI сейчас направлены на поиск приоритетных направлений развития с целью недопущения отставания от конкурентов. В рамках подобных инициатив стартап сейчас готовится создать унифицированное настольное приложение, которое объединит функции браузера, ChatGPT и ассистента для разработки программного обеспечения Codex. 
Источник изображения: Unsplash, Jacob Mindak Как сообщает The Wall Street Journal, новая идея будет курироваться лично президентом OpenAI Грегом Брокманом (Greg Brockman) с точки зрения руководства реорганизацией бизнес-процессов, а недавно назначенная директором по приложениям Фиджи Симо (Fidji Simo) сосредоточится на продвижении нового суперприложения на рынке. Если в прошлом году OpenAI хваталась буквально за любую новую идею использования генеративного ИИ, чтобы в числе первых занять место в новом рыночном сегменте, то теперь компания намерена не распылять ресурсы напрасно и сосредоточиться на самом важном. OpenAI намерена создать настольное приложение с развитыми агентскими возможностями, которые позволили бы буквально выполнять работу за пользователя в самом широком спектре задач, включая создание программного кода и анализ данных. «Мы поняли, что тратили наши усилия на слишком большое количество приложений и стеков, и что нам нужно упростить свою работу. Эта фрагментация замедляла нас и затрудняла достижение того уровня качества, к которому мы стремились», — отметила Симо в рассылке для сотрудников OpenAI, которую они получили вчера. Скорее всего, появление мощного приложения для написания программного кода и анализа данных позволит OpenAI потеснить конкурирующую Anthropic в корпоративном сегменте рынка. Он позволяет максимально быстро монетизировать новые сервисы, а для OpenAI проблема выхода на прибыльность с каждым годом обретает всё более высокую актуальность. В этом месяце, как добавляет CNBC, Фиджи Симо провела общее собрание сотрудников OpenAI, на котором обозначила приоритеты в развитии на ближайшее время. По её словам, сейчас компания «агрессивно ориентируется» на области применения своих разработок, которые обеспечивают рост производительности труда. «Что для нас сейчас действительно важно, так это сохранение концентрации и качественное выполнение работы», — пояснила подчинённым Фиджи Симо. В социальной сети X она отметила, что когда новые инициативы типа Codex начинают работать, очень важно удвоить усилия по их развитию и избегать отвлекающих факторов. По всей видимости, недавняя сделка по покупке стартапа Astral также направлена на усиление позиций OpenAI в сфере автоматизации разработки ПО. «Британская энциклопедия» подала в суд на OpenAI — ChatGPT почти дословно воспроизводит её статьи
16.03.2026 [21:44],
Николай Хижняк
«Британская энциклопедия» (Encyclopedia Britannica) и издатель словарей Merriam-Webster подали иск против OpenAI. Они утверждают, что компания использовала их защищённый авторским правом контент для обучения своего ИИ, а затем генерировала ответы, которые были «существенно похожи» на их контент. Об этом сообщило издание Reuters. 
Источник изображения: Levart_Photographer / unsplash.com «Британская энциклопедия» утверждает, что OpenAI неоднократно копировала их контент без разрешения. «GPT-4 сама “запомнила” большую часть защищенного авторским правом контента энциклопедии и будет выдавать почти дословные копии значительных фрагментов по запросу. Запомненные примеры являются несанкционированными копиями, которые [OpenAI] использовала для обучения своих моделей, включая GPT-4», — утверждается в иске. В иске также приводятся примеры ответов моделей OpenAI рядом с текстом «Британской энциклопедии», в которых целые отрывки совпадают слово в слово. «Британника» также утверждает, что OpenAI «перетягивает» на себя её веб-трафик, генерируя ответы, которые «заменяют или напрямую конкурируют» с контентом энциклопедии, вместо того чтобы направлять пользователей на свой веб-сайт, как это делала бы традиционная поисковая система. Как пишет The Verge, это последний из растущей череды исков о нарушении авторских прав от издателей, направленных против компаний, занимающихся искусственным интеллектом, за последние несколько лет. Ранее газета The New York Times выдвигала аналогичные обвинения в своём продолжающемся судебном процессе против OpenAI, в том числе обвиняя компанию в массовом копировании её защищённого авторским правом контента. В сентябре компания Anthropic урегулировала коллективный иск об использовании защищённых авторским правом книг для обучения своих моделей ИИ, выплатив авторам книг $1,5 млрд. OpenAI объяснила, почему реклама в ChatGPT появилась не везде и не у всех
16.03.2026 [15:59],
Анжелла Марина
OpenAI опровергла слухи о глобальном развёртывании рекламы в ChatGPT. Несмотря на то, что некоторые пользователи заметили новые пункты в политике конфиденциальности, касающиеся рекламных объявлений, компания заверила ресурс BleepingComputer, что на данный момент эта функция работает пока исключительно на территории США. 
Источник изображения: AI Как пояснили в компании, реклама в чат-боте действительно существует, но её показ строго ограничен территорией Соединённых Штатов. Запуск состоялся 9 февраля 2026 года, и в настоящее время OpenAI находится на этапе постепенного расширения доступа внутри страны. Только после тщательного изучения поведения пользователей и реакции на рекламу в реальных условиях будет принято решение о выводе монетизации на международный уровень. Технически объявления показываются непосредственно под сгенерированными ответами, но только тем пользователям, которые авторизованы в системе и используют тарифные планы Free или Go. Существуют строгие возрастные фильтры: реклама не демонстрируется лицам моложе 18 лет, даже по их запросу. Хотя OpenAI утверждает, что коммерческие блоки не влияют на содержание ответов, компания не отрицает факта глубокой персонализации объявлений, основанной на запросах пользователя. 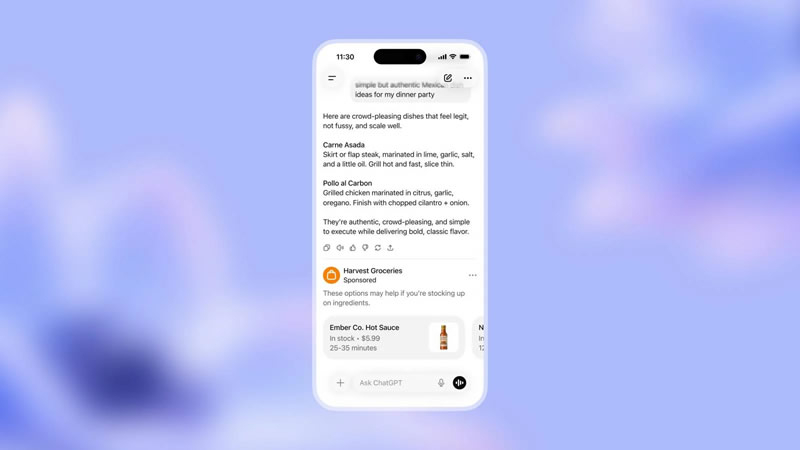
Источник изображения: bleepingcomputer.com В своих разъяснениях OpenAI отметила, что реклама управляется независимыми программными системами, и у рекламодателей нет возможности влиять на работу языковой модели. «Реклама работает в отдельных системах, отличных от нашей ИИ-модели, и рекламодатели не имеют возможности формировать, ранжировать или изменять ответы ChatGPT», — отмечается в документе OpenAI. Также подчёркивается, что все объявления являются платными размещениями и отделены от контента: «Это платное размещение, и просмотр рекламы не означает, что OpenAI одобряет или рекомендует рекламодателя, его продукты или услуги». Ключевым аспектом остаётся защита пользовательских данных: OpenAI заявила, что не делится с рекламодателями диалогами и гарантирует, что третьи лица не получают доступа к истории чатов, функции памяти или личной информации клиентов. На прямой вопрос BleepingComputer о сроках более широкого распространения рекламы компания ответа не предоставила. OpenAI отложила запуск эротических чатов в ChatGPT из-за опасений по поводу их безопасности
16.03.2026 [09:32],
Алексей Разин
Многие отрасли в своё время получили развитие, в том числе, и благодаря природному интересу человека к материалам эротического содержания, а потому сфера искусственного интеллекта не является исключением. Компании борются с соблазном использовать эротику для продвижения своих платформ, пытаясь при этом остаться в каких-то законодательных и этических рамках. OpenAI пока не готова запустить эротические чаты. 
Источник изображения: Unsplash, Alexander Krivitskiy О возможности появления такого направления в работе ChatGPT ещё в середине прошлого года заявил генеральный директор OpenAI Сэм Альтман (Sam Altman). Сперва он вынашивал идею запуска функции эротических чатов к декабрю прошлого года, потом сроки перенесли на текущий квартал, но теперь становится понятно, что и этот график не будет выдержан. Как минимум, задержка с дебютом функции эротических чатов будет измеряться одним месяцем, сообщает The Wall Street Journal. Эксперименты в использовании ИИ для создания текстового контента эротического содержания OpenAI предпринимала задолго до запуска ChatGPT. Ещё в 2021 году клиентам OpenAI предлагалась игра AI Dungeon с нелинейным сюжетом, направление развития которого могли задавать пользователи. Тогда специалисты OpenAI установили, что ИИ-платформа порой предлагает игрокам обсудить темы сексуальных взаимоотношений, даже если они никак не провоцировали подобный поворот сюжета. Если же пользователь сам предлагал умеренную степень эротизма, ИИ буквально «перегибал палку» в проявлениях откровенности соответствующих бесед. OpenAI уже тогда задумалась о привлекательности подобного применения чат-ботов, но при этом осознала и необходимость введения этических ограничений. Руководство OpenAI в последнее время всё более благосклонно высказывалось в отношении идеи запуска эротических чатов, подчёркивая, что всё ограничится только текстовой информацией, без создания изображений и видео откровенного содержания. Конкуренты тоже не стоят на месте. В прошлый четверг Илон Маск (Elon Musk) заявил, что его чат-бот Grok в части генерирования видео скоро сможет создавать контент, относящийся к категории «18+». Meta✴✴ позволяет пользователям своего чат-бота вести романтические ролевые игры, но только при наличии уверенности в их совершеннолетии. У самой OpenAI с механизмами подтверждения возраста пока имеются проблемы. Сейчас профильная система в 12 % случаев ошибочно принимает подростков за совершеннолетних. С учётом наличия примерно 100-миллионной аудитории несовершеннолетних пользователей ChatGPT, такой уровень погрешности позволил бы миллионам подростков на регулярной основе получать доступ к эротическим чатам. Созванная OpenAI в январе экспертная комиссия также выразила озабоченность угрозой появления запретного с точки зрения общественной морали и законодательства контента, который подразумевает насильственные действия сексуального характера, упоминание несовершеннолетних и другие специфические сценарии. Кроме того, увлечение подобным контентом может вызывать у людей психологическую зависимость и снижать их мотивацию поддерживать взаимоотношения с реальными партнёрами в офлайне. OpenAI хочет принудительно напоминать таким увлекающимся натурам, что им следует строить отношения с реальными людьми. Это особенно важно с учётом наличия не совсем приятных инцидентов, возникших по мере распространения чат-ботов. Существуют примеры доведения людей до самоубийства в результате длительного общения с вымышленными персонажами в чат-боте, включая и подростковые суициды. Эксперты опасаются, что эротический уклон подобных бесед только спровоцирует рост количества таких случаев. В части механизмов проверки возраста пользователей у представителей OpenAI особых иллюзий нет — они, по их словам, никогда не смогут быть идеальными и в 100 % случаев рабочими. С 2021 года часть сотрудников OpenAI выражает сопротивление идее запуска эротических чатов на платформе из опасения окончательного сползания в эту сферу: «Мы не хотели быть просто компанией, распространяющей эротику». На данный момент руководство OpenAI считает целесообразным запуск эротических чатов, руководствуясь следующими принципами: «Мы всё ещё верим, что со взрослыми надо обращаться как со взрослыми, но формирование правильного опыта потребует большего времени». OpenAI встроит генератор видео Sora прямо в ChatGPT
11.03.2026 [15:07],
Павел Котов
Компания OpenAI намерена открыть доступ к генератору видео на основе искусственного интеллекта Sora прямо в интерфейсе ChatGPT. Об этом сообщил ресурс The Information со ссылкой на информированные источники. 
Источник изображения: BoliviaInteligente / unsplash.com Генератор видео Sora помог OpenAI расширить возможности в области мультимодальных технологий ИИ — он выступает конкурентом аналогичным сервисам от Meta✴✴ и Google. Предназначенные для работы с текстом ИИ-модели уже широко используются как частными лицами, так и предприятиями, и очередным этапом в развитии технологий ИИ стали генераторы статических изображений и видеороликов — они обещают кардинальные изменения в отрасли. OpenAI запустила Sora как самостоятельное приложение в сентябре 2025 года. Оно позволяет пользователям генерировать видео по текстовым запросам и публиковать их. Разработчик заключил партнёрское соглашение с компанией Disney, согласно которому платформа может генерировать персонажей, которые принадлежат гиганту развлекательной индустрии. Созданные сервисом ролики можно публиковать в соцсетях. После открытия доступа к Sora через ChatGPT компания OpenAI намерена сохранить генератор видео и как самостоятельное приложение. Сам разработчик информацию об этом не прокомментировал, передаёт Reuters. ChatGPT получил визуальную функцию, которая «заставит» полюбить математику
11.03.2026 [06:08],
Анжелла Марина
Компания OpenAI представила новую функцию ChatGPT под названием «динамические визуальные объяснения» (dynamic visual explanations). Функция позволяет не просто читать разъяснения математических и научных концепций в виде текста, а взаимодействовать с интерактивными модулями в реальном времени. 
Источник изображения: xAI Как поясняет TechCrunch, принцип работы прост. Если спросить, что такое уравнение линзы или как найти площадь круга, ChatGPT выдаст не только текст, но и представит визуальный модуль, в котором можно менять значения переменных и мгновенно наблюдать за изменениями. Например, при изучении теоремы Пифагора можно регулировать длины сторон треугольника и видеть, как пересчитывается гипотенуза. 
Источник изображения: OpenAI На данный момент интерактивная визуализация доступна для более чем 70 тем по математике и естественным наукам. Среди них — биномиальный квадрат, закон Шарля, площадь круга, сложные проценты, закон Кулона, разность квадратов, экспоненциальный распад, закон Гука, кинетическая энергия, линейные уравнения и закон Ома. Функция доступна всем авторизованным пользователям ChatGPT, а список тем будет постепенно расширяться. Запуск нового инструмента примечателен тем, что он смещает роль ChatGPT от простой выдачи готовых ответов к вовлечению пользователя в процесс понимания, отмечает TechCrunch. Приведёт ли это к более глубокому усвоению материала, во многом будет зависеть от того, как именно люди станут использовать эту возможность. По данным OpenAI, более 140 миллионов человек еженедельно обращаются к ChatGPT с вопросами, связанными с математикой и естественными науками — то есть, теми предметами, которые традиционно вызывают трудности у учащихся. При этом в образовательном сообществе продолжаются споры: часть педагогов опасается чрезмерной зависимости от ИИ, тогда как многие учителя и студенты уже активно интегрируют технологию в учебный процесс. Отметим, новая функция дополняет другие образовательные инструменты ChatGPT, в частности, режим обучения, который пошагово ведёт пользователя через решение задач, и QuizGPT, позволяющий создавать карточки и проходить тестирование по любой теме. Аналогичную функцию интерактивных диаграмм в ноябре запустил сервис Gemini от Google. ChatGPT научился распознавать музыку — в него интегрировали Shazam
10.03.2026 [17:12],
Владимир Фетисов
ИИ-бот OpenAI ChatGPT научился распознавать музыкальные треки, для чего он задействует принадлежащий Apple сервис Shazam. Новая интеграция позволяет ввести запрос, например, «Shazam, что это за песня?», после чего появится интерфейс, с помощью которого можно узнать, что за песня играет. 
Источник изображения: macrumors.com Это нововведение избавит пользователей ChatGPT от необходимости закрывать окно приложения и переключаться к взаимодействию с другим сервисом в случаях, когда нужно распознать какую-либо композицию и прослушать её фрагмент. Взаимодействие с сервисом в ИИ-боте происходит аналогично тому, как Shazam работает на устройствах Apple. Shazam можно добавить в ChatGPT, открыв настройки ИИ-бота, перейдя в раздел приложений и выполнив поиск по доступным сервисам. После установки взаимодействовать с сервисом можно будет посредством запросов с упоминанием слова «Shazam». Функция распознавания песен может использоваться на любой платформе даже без установки приложения Shazam. Если же установить приложение, то определяемые в ChatGPT песни можно добавлять в библиотеку Shazam для дальнейшего взаимодействия. OpenAI отложила запуск «режима для взрослых» в ChatGPT — нужно решить проблему определения возраста
07.03.2026 [22:13],
Владимир Фетисов
В конце прошлого года OpenAI объявила о намерении запустить в ChatGPT «режим для взрослых» в первом квартале 2026 года, но, по всей видимости, ждать этого пользователям придётся дольше. По сообщениям сетевых источников, компания откладывает запуск функции, позволяющей генерировать контент для взрослых с помощью ИИ-бота. 
Источник изображения: unsplash.com В сообщении сказано, что OpenAI хочет добиться большего прогресса в улучшении алгоритмов определения возраста пользователей, чтобы не допустить ситуаций, когда «режим для взрослых» доступен несовершеннолетним. В начале года компания начала использовать инструменты прогнозирования возраста, которые анализируют разные факторы, такие как давность создания аккаунта и особенности его использования для определения реального возраста пользователей. «Мы по-прежнему верим в принцип отношения к взрослым как ко взрослым, но, чтобы сделать пользовательский опыт действительно качественным, потребуется больше времени», — прокомментировал данный вопрос представитель OpenAI. Он также добавил, что компания откладывает запуск «режима для взрослых» в ChatGPT, чтобы «сосредоточиться на работе, которая в данный момент является более приоритетной для большего числа пользователей», в первую очередь, на улучшении характеристик нейросети. Гендиректор OpenAI Сэм Альтман (Sam Altman) впервые намекнул на «режим для взрослых» в ChatGPT в октябре 2025 года. Тогда же он упомянул изменения, которые позволят пользователям сделать так, чтобы ChatGPT действовал «очень похоже на человека». Осторожность OpenAI с запуском «режима для взрослых» выглядит вполне логичной. Компания уже сталкивается с многочисленными исками из-за нескольких случаев суицида и причинения себе вреда пользователями после длительно общения с ИИ-ботом. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






