
Опрос
|
реклама
Быстрый переход
В Сети всплыла «ничейная» мощная ИИ-модель — в ней заподозрили разработку DeepSeek
18.03.2026 [19:20],
Анжелла Марина
Мощная ИИ-модель без указания авторства, появившаяся недавно на платформе OpenRouter, породила слухи о том, что китайский стартап DeepSeek может в скрытом режиме тестировать свою систему следующего поколения перед официальным запуском. Бесплатная модель под названием Hunter Alpha возникла на OpenRouter 11 марта без какой-либо атрибуции разработчика и позже была промаркирована самой платформой как «скрытая модель». Источник изображения: AI Во время тестов, проведённых агентством Reuters, чат-бот Hunter Alpha описал себя как китайскую ИИ-модель, обученную преимущественно на китайском языке, и сообщил, что его данные обучения охватывают период до мая 2025 года. Эта дата знаний совпадает с точкой, указанной собственным чат-ботом компании DeepSeek. Однако, когда собеседник спросил о создателе системы, она отказалась идентифицировать разработчика, заявив, что знает только своё имя, масштаб параметров и длину контекстного окна. Ни компания DeepSeek, ни платформа OpenRouter также не назвали создателя модели и не ответили на запросы о комментарии. Страница профиля Hunter Alpha раскрывает её внушительные технические характеристики: модель обладает 1 трлн параметров, что подразумевает высокие требования к вычислительным мощностям. Кроме того, система поддерживает контекстное окно до 1 млн токенов, позволяя обрабатывать огромные объёмы текста за один сеанс. Инженер, специализирующийся на создании ИИ-агентов, Набиль Хауам (Nabil Haouam), отметил, что сочетание окна в 1 млн токенов, возможностей логического рассуждения и бесплатного доступа сразу бросается в глаза, поскольку аналогичные по характеристикам модели обычно требуют значительных затрат при масштабировании. Именно эти значения (1 трлн параметров и 1 млн токенов контекста) связывают с грядущей моделью DeepSeek V4, чей выход прогнозируется в апреле. Совпадение породило волну слухов о том, что Hunter Alpha может быть ранней тестовой версией нового продукта китайского стартапа. Анализ модели, также проведённый инженером Дэниелом Дьюхерстом (Daniel Dewhurst), показал, что ключевым сигналом может служить паттерн цепочки рассуждений. По его словам, стиль логических построений, который использует чат-бот, очень трудно подделать, и он обычно отражает метод обучения модели. Тем не менее не все разделяют эту уверенность. Умур Озкул (Umur Ozkul), проведя независимый бенчмарк, заявил, что его анализ указывает на то, что Hunter Alpha, вероятно, не является DeepSeek V4. Он сослался на различия в поведении, связанном с токенами, и архитектурных паттернах по сравнению с существующими системами DeepSeek. Независимо от авторства модель быстро набрала популярность. Согласно статистике OpenRouter, по состоянию на воскресенье она обработала более 160 млрд токенов. Значительная часть активности исходила от инструментов разработки и фреймворков для ИИ-агентов. Отметим, что практика анонимного запуска моделей не является чем-то исключительным — это распространённый способ получения разработчиками объективной обратной связи от сообщества. Мультимодальная ИИ-модель DeepSeek-V4 с контекстным окном в 1 млн токенов выйдет в апреле
16.03.2026 [07:43],
Владимир Фетисов
С тех пор, как в январе прошлого года DeepSeek выпустила рассуждающую ИИ-модель DeepSeek-R1, которая получила широкую известность, крупных обновлений не выходило. Слухи о появлении новой ИИ-модели от DeepSeek время от времени вызывают волну обсуждений в интернете, но, по всей видимости, в следующем месяце состоится релиз мультимодальной модели DeepSeek-V4, которая получит значительные улучшения по сравнению с предыдущей версией. 
Источник изображения: mp.weixin.qq.com По данным источника, последние полгода команда разработчиков DeepSeek во главе с сооснователем компании Лян Вэньфэном (Liang Wenfeng) работала над устранением недостатков DeepSeek в плане обработки визуального контента и улучшением ИИ-поиска. Компания стремилась улучшить способности ИИ-модели в области генерации программного кода, а также работала над расширением контекстного окна. Для достижения поставленных целей ещё в прошлом году DeepSeek начала сотрудничать с Baidu. Пользователи платформ для профессионалов по всему миру пытаются уловить признаки появления новой версии DeepSeek. Несколько дней назад на OpenRouter, крупнейшем агрегаторе API для ИИ-моделей, появились алгоритмы Healer Alpha и Hunter Alpha. Модель Healer Alpha — это мультимодальная языковая модель, способная воспринимать визуальную и звуковую информацию, проводить кросс-модальные рассуждения и с высокой точностью выполнять многошаговые задачи. При этом размер контекстного окна алгоритма составляет всего 260 тыс. токенов. Hunter Alpha создана специально для агентных приложений. Это модель с триллионами параметров и контекстным окном в 1 млн токенов. В описании сказано, что алгоритм хорошо справляется с долгосрочным планированием, сложными рассуждениями и непрерывным выполнением многошаговых задач. Она может точно следовать полученным инструкциям, что важно при работе с фреймворками вроде OpenClaw, позволяющими создавать ИИ-агентов. 
Источник изображения: Unsplash, Solen Feyissa На фоне появления этих двух языковых моделей в соцсети X снова поднялась волна обсуждений о скором выходе DeepSeek-V4. Однако, судя по предыдущим публичным сообщениям о DeepSeek-V4, модель обладает десятками триллионов параметров, контекстным окном в 1 млн токенов, а также способностью понимать и генерировать мультимодальные данные, т.е. обрабатывать и создавать текст, изображения и видео. Это означает, что характеристики недавно появившихся на OpenRouter алгоритмов не в полной мере соответствуют ожидаемым параметрам DeepSeek-V4. По данным источника, направление развития следующей версии DeepSeek связано с улучшением долгосрочной памяти, считающейся одной из важнейших характеристик языковых моделей. За последние полгода Лян Вэньфэн стал соавтором трёх научных работ, связанных, в том числе, с изучением возможностей расширения долгосрочной памяти языковых моделей. Результаты исследований Вэньфэна и его команды также демонстрируют чёткую траекторию технологической эволюции. Утвердив парадигму обучения с подкреплением для способностей к рассуждению в DeepSeek-R1, разработчики исследуют дальнейшие инновации в базовой архитектуре. В частности, через новые модули, такие как «условная память», они пытаются повысить производительность алгоритма, решив известные проблемы традиционной архитектуры в части памяти и вычислительных мощностей. Эта деятельность также является технологической подготовкой к запуску DeepSeek-V4. Кроме того, новый алгоритм будет глубоко адаптирован под китайские ИИ-ускорители и может стать первой ИИ-моделью, полностью работающей в рамках «экосистемы отечественных вычислительных мощностей». В апреле на рынке китайских ИИ-моделей ожидается высокая активность. Помимо появления новой версии DeepSeek, ожидается запуск очередной ИИ-модели Tencent с 30 млрд параметров. Новейшая ИИ-модель DeepSeek V4 должна быть оптимизирована под китайские ускорители вычислений
02.03.2026 [09:00],
Алексей Разин
На этой неделе, как сообщает Financial Times, китайская DeepSeek должна представить долгожданную мультимодальную ИИ-модель V4, которая была оптимизирована под использование ускорителей Huawei и Cambricon. В совокупности это позволит китайским компаниям добиться определённых успехов во внедрении технологий ИИ без чрезмерной зависимости от импортных решений. 
Источник изображения: DeepSeek По данным источника, сроки анонса модели DeepSeek V4 будут привязаны к парламентскому заседанию в КНР, которое начнётся 4 марта. Данный релиз для DeepSeek станет крупнейшим с января прошлого года, когда была представлена рассуждающая модель R1. Тогда утверждалось, что китайской компании удалось создать сопоставимую по эффективности с западными решениями ИИ-модель при значительно меньших затратах. Позже выяснилось, что DeepSeek не только могла использовать данные американских моделей для обучения своих, но и опираться на ускорители вычислений Nvidia, которые в необходимом компании ассортименте моделей находятся в КНР под санкциями. Как ожидается, оптимизация DeepSeek V4 под ускорители Huawei и Cambricon будет способствовать росту спроса на эти аппаратные решения в Китае, а также снижению импортозависимости. DeepSeek якобы даже намеренно не оптимизировала свою новейшую модель под ускорители Nvidia. Ранее сообщалось, что первые попытки DeepSeek обучать модель V4 на ускорителях Huawei не увенчались особым успехом. Аннотация к DeepSeek V4 выйдет на этой неделе в сокращённом виде, но примерно через месяц будет опубликована в полном размере. Американская Anthropic недавно обвинила DeepSeek в «дистилляции» собственных ИИ-моделей. DeepSeek отвернулась от Nvidia в пользу Huawei при подготовке новой ИИ-модели
26.02.2026 [04:46],
Алексей Разин
Как утверждает Reuters, в мировой практике разработки больших языковых моделей подразумевается заключительный этап, на котором перед их выходом на рынок они подвергаются оптимизации силами поставщиков ускорителей вычислений. DeepSeek при доводке своей новейшей ИИ-модели отдала предпочтение Huawei и другим китайским производителям ускорителей. 
Источник изображения: Nvidia Суть заключается в том, как поясняет Reuters, что традиционно «право первой брачной ночи» предоставлялось ведущим американским поставщикам ускорителей, а именно — компании Nvidia. Подготовка ИИ-моделей DeepSeek ранее тоже следовала этому правилу, но в случае с новейшей V4 китайские разработчики отдали предпочтение соотечественникам типа Huawei и других поставщиков ускорителей из КНР. За несколько недель до выхода новой ИИ-модели DeepSeek открыла доступ к ней именно китайским поставщикам ускорителей. Это позволит оптимизировать программное обеспечение под особенности данной аппаратной базы и затем добиться более высокой эффективности работы модели. По словам независимых разработчиков, современные средства оптимизации позволяют провести такую работу в считанные недели против нескольких месяцев ранее. По всей видимости, подобная расстановка приоритетов в случае с DeepSeek является частью политики, проводимой китайскими властями. Оборудование и программное обеспечение местного происхождения должно получать приоритет по сравнению с американскими. Правда, эти новости не очень уживаются с ранними сообщениями об использовании DeepSeek секретного ЦОД на основе ускорителей Nvidia поколения Blackwell для обучения своей новейшей ИИ-модели. Американские чиновники считают, что DeepSeek постарается скрыть факт использования ускорителей Blackwell при подготовке новой модели к выходу, а также заявить об использовании ускорителей Huawei. Санкции не помеха: DeepSeek могла обучить ИИ на запрещённых Nvidia Blackwell
24.02.2026 [07:42],
Алексей Разин
Несмотря на некоторое смягчение политики экспортных ограничений США в отношении поставок в Китай ускорителей вычислений для систем ИИ, решения Nvidia семейства Blackwell остаются в этой стране под запретом. Это не помешало китайской DeepSeek, по данным некоторых источников, обучить свою новейшую ИИ-модель именно на этих ускорителях. 
Источник изображения: Nvidia На следующей неделе, как поясняет Reuters, китайская DeepSeek представит свою новейшую ИИ-модель, и у источника есть все основания полагать, что она была обучена с использованием санкционных ускорителей Nvidia Blackwell, которые эксплуатируются во Внутренней Монголии — регионе Китая, обладающем определённой автономией. Соответствующей информацией располагают американские чиновники, а это может стать поводом для определённых действий в отношении китайских разработчиков ИИ. Как последние получили доступ к ускорителям Blackwell в условиях санкций, источники не поясняют. В целом, американские политики разделились на два лагеря. Одни под воздействием основателя Nvidia Дженсена Хуанга (Jensen Huang) склонились к идее о необходимости сохранения зависимости Китая от поставок американских ускорителей вычислений, которые могут отставать от передовых на одно или два поколения. Другие считают, что предоставление Китаю доступа к таким инструментам сродни передаче ему ядерного оружия по доброй воле. Американские чиновники опасаются, что китайские ИИ-решения будут поставлены на службу оборонной отрасли КНР. Принято считать, что в августе прошлого года американский президент Дональд Трамп (Donald Trump) был близок к выдаче разрешения на поставку в Китай модифицированных ускорителей Blackwell, которые отставали бы от предлагаемых в США по уровню быстродействия. Вместо этого в декабре Трамп разрешил поставки в КНР ускорителей H200 с более старой архитектурой Hopper. Учитывая растущее количество жалоб американских разработчиков на хищение данных со стороны китайских конкурентов, американские власти могут ввести дополнительные ограничения в сфере ИИ на китайском направлении экспорта. Anthropic обвинила DeepSeek и ещё двух китайских конкурентов в 16 млн попыток дистилляции моделей Claude
24.02.2026 [07:04],
Алексей Разин
OpenAI в этом месяце уже предупреждала американских законодателей в применении китайской компанией DeepSeek метода дистилляции её ИИ-моделей для ускорения собственного прогресса. Теперь со схожими обвинениями выступила Anthropic, причём в адрес сразу трёх китайских конкурентов: DeepSeek, MiniMax Group и Moonshot. 
Источник изображения: Unsplash, Solen Feyissa По словам представителей Anthropic, на которые ссылается Bloomberg, три указанные китайские компании нарушили правила использования её моделей семейства Claude, осуществив не менее 16 млн сессий обмена данными с использованием тысяч поддельных учётных записей. Метод дистилляции в сфере обучения моделей позволяет разработчикам добиваться прогресса в сжатые сроки, совершенствуя свои системы на основе данных, получаемых от уже обученных сторонних моделей. Как отмечает Anthropic в своём блоге, действия китайских разработчиков в этой сфере становятся всё более активными и изощрёнными. При этом окно времени для решительных ответных действий становится всё более узким, а угроза распространяется за пределы одной компании и конкретного региона. Триумф китайской DeepSeek состоялся примерно год назад, когда она представила свою модель R1, которая при сопоставимой результативности обошлась в обучении в разы дешевле создаваемых западными конкурентами. С тех пор китайские разработчики буквально наводнили рынок более доступными ИИ-моделями, которые позволяют работать с текстом, видео и изображениями. Американским компаниям, которые опираются на закрытую экосистему, стало сложнее монетизировать свои разработки. По данным Anthropic, китайские конкуренты использовали подставные учётные записи и прокси-серверы для доступа к данным Claude с минимальным риском обнаружения. Если DeepSeek осуществила более 150 000 обменов данными с Claude, то MiniMax преодолела планку в 13 млн обменов, пытаясь воссоздать передовые функции по примеру Claude, как считают в Anthropic. Отследить подобную активность Anthropic помогли партнёры, и в достоверности своих выводов компания очень уверена. Она формирует новые методы защиты от дистилляции своих моделей и готова делиться ими с другими представителями отрасли: «Ни одна из компаний не сможет с этим справиться в одиночку. Дистилляционные атаки такого масштаба требуют скоординированного ответа всей ИИ-отрасли, включая провайдеров облачных услуг и регуляторов». OpenAI обвинила китайскую DeepSeek в краже данных для обучения ИИ-модели R1
13.02.2026 [12:11],
Алексей Разин
Агентство Bloomberg со ссылкой на служебную записку OpenAI сообщает, что создатели ChatGPT обвинили китайскую DeepSeek в использовании ухищрений, позволяющих добывать информацию американских ИИ-моделей для обучения китайского чат-бота R1 следующего поколения. Соответствующий доклад был направлен американским парламентариям, по данным источника. 
Источник изображения: Unsplash, Solen Feyissa По мнению представителей OpenAI, китайский конкурент использовал метод так называемой дистилляции, чтобы «бесплатно выехать на успехе технологий, разработанных OpenAI и других передовых американских компаний». Создателям ChatGPT якобы удалось выявить новые изощрённые методы получения доступа китайской DeepSeek к информации американских ИИ-моделей, которые призваны обходить существующие методы защиты. Беспокойство на эту тему OpenAI и Microsoft проявили ещё в прошлом году, когда начали соответствующее расследование в отношении деятельности DeepSeek. Метод дистилляции позволяет ускорить обучение сторонних ИИ-моделей с использованием данных уже обученных систем. Анализ активности на собственной платформе, как отмечает OpenAI, позволяет говорить об участившихся случаях применения дистилляции сторонними разработчиками ИИ-моделей — преимущественно расположенными в Китае, хотя в отчёте упоминается и Россия. Поскольку DeepSeek не предлагает своим клиентам платных подписок, как и многие другие китайские провайдеры подобных услуг, они получают большее распространение, чем проприетарные коммерческие решения западного происхождения, по мнению авторов доклада. Это угрожает мировому главенству ИИ-моделей американской разработки, как резюмируют они в своём обращении к специальному комитету американского парламента. Полученные методом дистилляции сторонние ИИ-модели, по словам представителей OpenAI, нередко лишены тех ограничений, которые устанавливаются создателями исходных систем, а потому могут использоваться во вред человечеству или отдельным странам. Попытки OpenAI оградить себя от дистилляции китайскими разработчиками успехом не увенчались, поскольку представители DeepSeek якобы получали доступ к американским ИИ-моделям разного рода окольными путями. По словам представителей OpenAI, существуют целые сети посредников, которые предоставляют доступ к услугам компании в обход существующих ограничений. Для американских чиновников существование подобных практик тоже не является откровением, отмечает Bloomberg. Американские политики обеспокоены и возможностью получения компанией DeepSeek доступа к более современным ускорителям вычислений Nvidia H200, поскольку их поставки в Китай в прошлом году успел разрешить американский президент Дональд Трамп (Donald Trump). В сочетании с существующими методами обучения своих моделей, DeepSeek могла бы в результате добиться существенного прогресса. Прежние расследования уже выявили, что DeepSeek использовала для обучения своих предыдущих ИИ-моделей оборудование Nvidia, хотя основная его часть была доставлена в Китай в рамках существовавших на тот момент правил экспортного контроля США. Политики теперь опасаются, что доступ DeepSeek к более современным чипам H200 сильнее навредит позициям США на мировой технологической арене. Китайские ИИ-модели с открытым исходным кодом уже заняли 15 % мирового рынка
26.01.2026 [08:27],
Алексей Разин
Прошлогодний успех первой ИИ-модели DeepSeek в целом привлёк внимание общественности к китайским разработкам в этой сфере, которые чаще всего сохраняют исходный код открытым, позволяя сторонним разработчикам использовать соответствующее ПО для своих нужд. Доступность китайских решений способствовала быстрому росту их популярности в мире. 
Источник изображения: Unsplash, Solen Feyissa По данным Nikkei, на которые ссылается TrendForce, в ноябре прошлого года китайские ИИ-модели благодаря использованию открытого исходного кода смогли увеличить своё присутствие на мировом рынке с 1 до 15 %. По статистике, более 40 % создаваемых китайскими компаниями ИИ-моделей используются в достаточно сложных задачах типа разработки ПО. Самой популярной в мире ИИ-платформой с открытым исходным кодом остаётся Qwen компании Alibaba, поскольку пользователи по состоянию на текущий месяц скачали её более 700 млн раз. Alibaba в целом предлагает клиентам широкий выбор ИИ-моделей с открытым исходным кодом, количество параметров у них варьируется от 600 млн до десятков миллиардов. Если говорить о DeepSeek, то она готовится в ближайшее время представить свою ИИ-модель нового поколения, а в рейтинге Nikkei её выпущенная в декабре модель при работе с японским языком демонстрирует быстродействие, соответствующее девятому месту из 92. Среди моделей с открытым исходным кодом DeepSeek предлагает самую быструю, за ней следует Alibaba Qwen, а версии моделей Google и OpenAI с открытым исходным кодом уступают им обеим. В Японии шесть из десяти разрабатываемых местными компаниями ИИ-моделей построены на DeepSeek и Qwen. Глава Google DeepMind оценил отставание китайских ИИ-моделей в шесть месяцев
21.01.2026 [07:36],
Алексей Разин
Генеральный директор DeepMind Демис Хассабис (Demis Hassabis) на прошлой неделе уже заявлял, что отставание китайских ИИ-моделей от западных за последние пару лет заметно сократилось, но оно всё же измеряется несколькими месяцами. В интервью Bloomberg на форуме в Давосе он предпочёл определить этот разрыв величиной в шесть месяцев. 
Источник изображения: Isomorphic Labs Как отметил Демис Хассабис, китайские разработчики неплохо себя проявили в преследовании лидеров отрасли, но им лишь представить доказать, что они способны опередить их и преодолеть соответствующий барьер на уровне инноваций. Прошлогоднюю модель китайской DeepSeek глава DeepMind до сих пор называет «впечатляющей». Любопытно, что не все ведущие западные игроки ИИ-сегмента положительно оценивают решение властей США открыть поставки ускорителей Nvidia H200 в Китай. По мнению главы Anthropic Дарио Амодеи (Dario Amodei), поставки таких ускорителей в Китай схожи с продажей ядерного оружия в Северную Корею. DeepMind в составе Google работает не только над совершенствованием ИИ-ассистента на базе Gemini, но и интересуется направлением робототехники, которая всё чаще ассоциируется у участников рынка со следующим по важности воплощением искусственного интеллекта. По мнению Хассабиса, в сфере «физического ИИ» в скором времени должны произойти прорывные изменения. При этом перед разработчиками стоят сложные проблемы. «Очень сложно добиться надёжности, силы и подвижности человеческой кисти», — признаётся глава DeepMind. DeepSeek научилась тренировать языковые ИИ-модели без оглядки на ограничения по скорости памяти
14.01.2026 [11:55],
Алексей Разин
Как отмечалось недавно, пропускная способность памяти, используемой в инфраструктуре ИИ, становится одним из серьёзных ограничителей дальнейшего роста быстродействия языковых моделей. Представители DeepSeek утверждают, что разработали метод обучения ИИ-моделей, который позволяет обойти подобные ограничения со стороны памяти. 
Источник изображения: Unsplash, Solen Feyissa Группа исследователей Пекинского университета в сотрудничестве с одним из основателей DeepSeek Лян Вэньфэном (Liang Wenfeng) опубликовала научную работу, в которой рассматривается новый подход к обучению языковых моделей, позволяющий «агрессивно увеличивать количество параметров» в обход ограничений, накладываемых подсистемой памяти используемых в ускорителях GPU. От DeepSeek ожидают выхода новой версии большой языковой модели, но ритмичность их создания в случае с китайскими разработчиками сильно страдает от экспортных ограничений США и нехватки ресурсов в Китае. Текст нового исследования, соавтором которого является один из основателей DeepSeek, будет подробно изучаться специалистами в области искусственного интеллекта как в Китае, так и за его пределами. Описываемая в документе методика «условного» использования памяти получила обозначение Engram, как отмечает South China Morning Post. Существующие подходы к вычислениям при обучении больших языковых моделей, по мнению китайских исследователей, вынуждают напрасно тратить ресурсы на тривиальные операции, которые можно было бы высвободить для высокоуровневых операций, связанных с рассуждениями. Исследователи предложили в некотором смысле разделить вычисления и работу с памятью, обеспечивая поиск базовой информации более эффективными способами. Одновременно новая технология позволяет большим языковым моделям лучше обрабатывать длинные цепочки контекста, что приближает цель превращения ИИ-агентов в полноценных помощников человека. В рамках эксперимента новый подход при обучении модели с 27 млрд параметров позволил поднять общий уровень быстродействия на несколько процентов. Кроме того, система получила больше доступных ресурсов для осуществления сложных операций с рассуждениями. По мнению авторов исследования, данный подход будет незаменим при обучении языковых моделей нового поколения в условиях ограниченности ресурсов. По данным The Information, китайская компания DeepSeek намеревается представить новую модель V4 с развитыми способностями в области написания программного кода к середине февраля этого года. Китайский ИИ стал популярнее американского за пределами западных стран — Microsoft бьёт тревогу
13.01.2026 [12:04],
Алексей Разин
Президент Microsoft Брэд Смит (Brad Smith) в интервью Financial Times признался, что американские разработчики ИИ уже проигрывают гонку китайским ИИ-моделям с точки зрения охвата аудитории за пределами западных стран. Непосредственно внутри Китая бурному развитию ИИ способствуют не только ориентация на открытый исходный код, но и предполагаемые государственные субсидии. 
Источник изображения: Nguyen Dang Hoang Nhu / unsplash.com По словам Смита, за прошедший год ситуация в сфере ИИ резко поменялась. Китайские разработчики успели предложить пользователям по всему миру сразу несколько ИИ-моделей с открытым исходным кодом, на обучение которых можно тратить гораздо меньше ресурсов, чем в случае с западными решениями. При этом уровень быстродействия китайских разработок делает их вполне конкурентоспособными. Президент Microsoft убеждён, что именно активные субсидии со стороны властей КНР позволяют китайским разработчикам опережать американских с точки зрения ценовой привлекательности. Доступность и низкая стоимость китайских языковых моделей за прошедшее с момента выхода DeepSeek R1 позволили искусственному интеллекту шагнуть далеко вперёд в масштабах всего мира, а особенно это ощущалось в странах так называемого «глобального юга». Нередко китайские ИИ-модели разработчики в прочих странах могут использовать безвозмездно для адаптации под свои потребности, и это сказывается на их популярности. Западные разработчики стараются монетизировать свои ИИ-решения, предлагая продвинутые функции по платной подписке. По данным исследователей Microsoft, в самом Китае доля DeepSeek на рынке ИИ достигает 89 %, на втором месте оказывается Беларусь с 56 %, третье занимает Куба с 49 %, а России досталось четвёртое место с 43 %. Страны Африки замыкают первую десятку, начиная с восьмого места: Эфиопия (18 %), Зимбабве (17 %) и Эритрея (17 %). Популярность DeepSeek в РФ, Беларуси и на Кубе отчасти объясняется и запретами на использование моделей западного происхождения во многих инфраструктурных проектах. 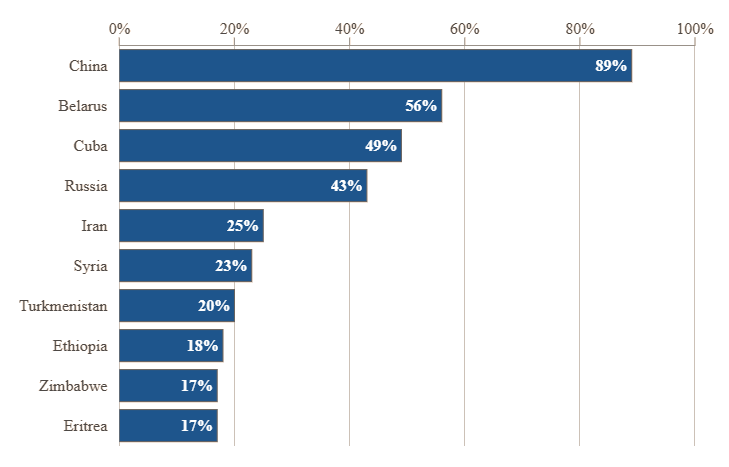
Источник изображения: Financial Times По оценкам Microsoft, для адекватного развития ИИ-инфраструктуры африканские страны потребуют международных кредитов, которые отчасти могли бы пойти на субсидирование расходов на электроэнергию. По мнению президента корпорации, соревноваться с китайскими разработчиками, нередко серьёзно субсидируемыми, просто бессмысленно, если говорить об отдельных региональных рынках. Многим африканским странам приходится выбирать наиболее дешёвые ИИ-платформы, и китайские с их открытым кодом нередко соответствуют этому критерию. Кроме того, в Африке существуют небольшие локальные языковые модели типа Masakhane и InkubaLM. В мировых масштабах, как удалось установить Microsoft, практическое использование ИИ сосредоточено в странах «глобального севера», где оно достигает 25 % от всего экономически активного населения. На глобальном юге эта доля не превышает 14 %, а в целом по миру составляет 16 %. Тем не менее, лидером по использованию ИИ является ОАЭ, поскольку в этой стране почти 60 % работающего населения используют данные технологии. Сингапур отстаёт совсем чуть-чуть, а в самих США этот показатель едва дотягивает до 26 %. 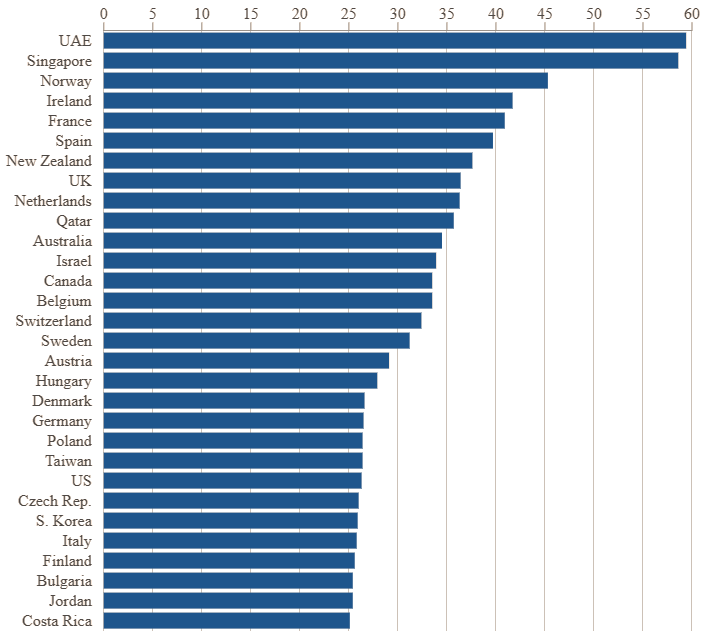
Источник изображения: Financial Times По мнению руководства Microsoft, «ИИ-неравенство» между странами глобального юга и севера будет расти и дальше, если не предпринимать компенсирующих мер. Президент корпорации заявил, что инвестиции в развитие инфраструктуры и обучение кадров должны направлять не только государственные институты, но и частные компании. Тот факт, что американские разработчики имеют доступ к более прогрессивным чипам, по словам Смита, ещё не гарантирует достижения ими более низких цен для клиентов, желающих воспользоваться ИИ. Игнорирование потребностей той же Африки странами Запада, по мнению президента Microsoft, создаст благоприятные условия для развития идей, не очень соответствующих западным ценностям и ориентирам. Китайские разработчики ИИ признают, что в ближайшие несколько лет им вряд ли удастся опередить США
12.01.2026 [08:11],
Алексей Разин
Представители китайской ИИ-отрасли достаточно трезво смотрят на перспективы её ближайшего развития, упоминая ограниченность вычислительных ресурсов и экспортные ограничения США в качестве главных препятствий к переходу к доминированию над геополитическим соперником в этой сфере в течение ближайших трёх или пяти лет. 
Источник изображения: DeepSeek Как отмечает Bloomberg, руководящий созданием больших языковых моделей семейства Qwen в компании Alibaba Джастин Линь (Justin Lin), оценивает шансы любой из китайских компаний на прорыв в этой сфере менее чем в 20 %, если говорить о перспективе ближайших трёх или пяти лет. Подобные взгляды на ситуацию разделяют и другие представители китайской ИИ-отрасли типа Tencent и Zhipu AI. Представитель Alibaba пояснил, что в сравнении с OpenAI китайский конкурент обделён необходимыми для качественного прорыва ресурсами. Этот вопрос, по его словам, давно известен: чьи шансы на инновации выше, если сравнивать богатых и бедных? При этом китайские разработчики пытаются привлекать средства на своё развитие на фондовом рынке. На прошлой неделе Zhipu и MiniMax Group сообща смогли привлечь более $1 млрд на своё развитие. По мнению сооснователя Zhipu, отставание китайских разработчиков от американских будет только увеличиваться. Год назад неожиданный успех китайской DeepSeek заставил многие компании пойти путём создания больших языковых моделей с открытым исходным кодом. На тот момент казалось, что они исключили отставание от проприетарных моделей OpenAI, Anthropic и Google. Участники тематического китайского мероприятия признали, что ограничения США на поставку в Китай оборудования и технологий для выпуска передовых чипов существенным образом сдерживают развитие китайской ИИ-отрасли. Она в целом сильнее ограничена в ресурсах. Перешедший на работу из OpenAI в Tencent Яо Шунью (Yao Shunyu) призвал представителей китайской отрасли уделять больше внимания устранению узких мест в больших языковых моделях следующего поколения. К ним он отнёс долгосрочную память и функцию самообучения. Tencent в этом году намерена открыть доступ ИИ-ассистенту Yuanbao к истории чатов в WeChat, чтобы на основе этих данных ускорить совершенствование собственных моделей. Alibaba собирается делать упор на мультимодальность и агентов для работы с реальными приложениями. Участники мероприятия высказались за сотрудничество и отказ от бессмысленной конкуренции внутри Китая. Местные разработчики должны объединить усилия, чтобы успешно представлять КНР на международном рынке систем генеративного ИИ. Новая ИИ-модель DeepSeek V4 выйдет в феврале, и она должна понравиться вайб-кодерам
10.01.2026 [13:04],
Николай Хижняк
Китайский стартап DeepSeek, занимающийся разработкой искусственного интеллекта и в прошлом году потрясший Кремниевую долину и Уолл-стрит, готовится к запуску своей модели следующего поколения в ближайшие недели, сообщает Yahoo Finance со ссылкой на отчёт издания The Information. 
Источник изображения: Solen Feyissa / unsplash.com Ожидается, что новая модель, получившая название V4, будет обладать расширенными возможностями программирования, которые, согласно внутренним тестам, позволят ей превзойти лидеров отрасли, включая серию GPT от OpenAI и Claude от Anthropic. По словам двух источников, непосредственно знакомых с ситуацией и цитируемых The Information, DeepSeek планирует выпустить модель примерно в середине февраля, в период празднования китайского Нового года, хотя сроки пока окончательно не определены. Время предполагаемого запуска соответствует стратегии, которая ранее принесла пекинскому стартапу огромный культурный и рыночный эффект. В прошлом году DeepSeek выпустила свою флагманскую модель R1 20 января, всего за неделю до недельных китайских новогодних праздников. Этот шаг обеспечил модели доминирование в глобальном технологическом дискурсе в период пикового внимания. DeepSeek, поддерживаемая хедж-фондом High-Flyer Quant, стала глобальным феноменом после выпуска R1. «Рассуждающая» модель, разработанная для «обдумывания» сложных запросов перед ответом, произвела фурор в секторе ИИ не только своей производительностью, но и эффективностью. На рынке, где американские гиганты тратят миллиарды на вычислительные ресурсы, способность DeepSeek достигать сопоставимых результатов за гораздо меньшую стоимость привела к резкой переоценке стоимости ИИ и зависимости от аппаратного обеспечения на западных рынках. Хотя модель DeepSeek V3.2, выпущенная в декабре, превзошла GPT-5 от OpenAI и Gemini 3.0 Pro от Google по некоторым показателям, компания ещё не выпустила нового поколения своей основной архитектуры. Модель V4 призвана заполнить этот пробел. Особый акцент в новой модели сделан на программировании. Умение программировать является основным критерием эффективности ИИ в корпоративной среде, и версия V4 может ещё больше укрепить позиции DeepSeek как недорогой и высокопроизводительной альтернативы американским моделям с закрытым исходным кодом. Для инвесторов предстоящий релиз DeepSeek V4 добавляет новый уровень волатильности в «гонку вооружений в области ИИ». Когда в прошлом году дебютировала DeepSeek R1, это вызвало временное падение акций американских производителей микросхем и лидеров в области ИИ, поскольку рынки столкнулись с реальностью сценария, когда китайский игрок достиг паритета, имея значительно меньше ресурсов, чем конкуренты. В DeepSeek придумали новый способ экономить ресурсы при обучении ИИ
02.01.2026 [13:57],
Павел Котов
Китайская DeepSeek проводила 2025 год публикацией материала, в котором предлагается переосмыслить фундаментальную архитектуру, используемую при обучении базовых моделей искусственного интеллекта. Одним из авторов работы выступил глава компании Лян Вэньфэн (Liang Wenfeng). 
Источник изображения: Solen Feyissa / unsplash.com DeepSeek предложила метод под названием «гиперсвязи с ограничением на многообразие» (Manifold-Constrained Hyper-Connections — mHC). Этот метод помогает повысить экономическую эффективность моделей и даёт им возможность не отставать от конкурирующих американских решений, разработчики которых располагают доступом к значительным вычислительным ресурсам. Опубликованная DeepSeek научная работа отражает сложившуюся в Китае открытую и основанную на взаимопомощи культуру разработчиков ИИ, которые публикуют значительную долю своих исследований в открытом доступе. Статьи DeepSeek также могут указывать на инженерные решения, которые компания использует в готовящихся к выпуску моделях. Группа из 19 исследователей компании отметила, что метод mHC тестировался на моделях с 3 млрд, 9 млрд и 27 млрд параметров, и его использование не дало существенного увеличения вычислительной нагрузки по сравнению с традиционным методом гиперсвязей (Hyper-Connections — HC). Базовый метод гиперсвязей в сентябре 2024 года предложили исследователи ByteDance в качестве модификации ResNet (Residual Networks) — доминирующей архитектуры глубокого обучения, которую ещё в 2015 году представили учёные Microsoft Research Asia. ResNet позволяет производить обучения глубоких нейросетей таким образом, чтобы ключевая информация (остаточные данные) сохранялась при увеличении числа слоёв. Эта архитектура используется при обучении моделей OpenAI GPT и Google DeepMind AlphaFold, и у неё есть важное ограничение: проходя через слои нейросети, обучающий сигнал может вырождаться в универсальное представление, одинаковое для всех слоёв, то есть рискует оказаться малоинформативным. Гиперсвязи успешно решают эту проблему, расширяя поток остаточных данных и повышая сложность нейросети «без изменения вычислительной нагрузки у отдельных блоков», но при этом, указывают в DeepSeek, растёт нагрузка на память, и это мешает масштабировать данную архитектуру при обучении больших моделей. Чтобы решить и эту проблему, DeepSeek предлагает метод mHC, который «поможет устранить существующие ограничения и в перспективе откроет новые пути эволюции фундаментальных архитектур нового поколения». Публикуемые компанией научные работы часто указывают на техническое направление, лежащее в основе последующих моделей, говорят эксперты. Новую крупную модель DeepSeek, как ожидается, может представить в середине февраля. США снова нацелились на Xiaomi: компанию хотят вернуть в чёрный список Пентагона вместе с DeepSeek и Unitree
24.12.2025 [08:31],
Алексей Разин
Давно понятно, что американские власти не брезгуют темой национальной безопасности для решения преимущественно коммерческих вопросов и защиты своих интересов в сфере внешней торговли. Хотя Xiaomi удалось в 2021 году доказать через суд свою непричастность к развитию китайского оборонного сектора, американские парламентарии опять требуют включить её в чёрный список Пентагона вместе с DeepSeek и Unitree. 
Источник изображения: Xiaomi Речь идёт, как поясняет South China Morning Post, о попытках включения указанных китайских компаний в так называемый раздел 1260H списка Пентагона, который содержит имена компаний, с которыми американским ведомствам и бизнесменам не рекомендуется иметь дело по соображениям национальной безопасности. Появление имени китайской компании в списке 1260H не означает моментального введения санкций против неё, но значительно усложняет ведение ими бизнеса. Девять сенаторов, представляющих интересы Республиканской партии США, на прошлой неделе обратились с открытым письмом к министру обороны Питу Хегсету (Pete Hegseth) с просьбой включить в список 1260H более десяти китайских компаний, среди которых оказались Xiaomi, DeepSeek и Unitree. Первая производит потребительскую электронику и электромобили, вторая разрабатывает систем генеративного искусственного интеллекта, а третья известна своими человекоподобными роботами. Кроме того, авторы инициативы предлагают включить в этот список и другие китайские компании из сектора робототехники, разработчиков чипов и представителей сегмента биотехнологий. Китайский производитель беспилотных летательных аппаратов DJI до сих пор судится с Министерством обороны США, пытаясь отменить своё включение в соответствующий список ведомства. Аналогичные попытки предпринимают интернет-гигант Tencent и китайский производитель тяговых батарей CATL. Xiaomi удалось в 2021 году добиться своего исключения из списка 1260H по итогам судебного разбирательства, новые обвинения в свой адрес компания тоже отвергает, подчёркивая свою причастность лишь к выпуску потребительской продукции гражданского назначения. Попытки включить Xiaomi в список 1260H американского военного ведомства являются безосновательными, по словам представителей китайской компании. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






