







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexMeta✴ представила Llama 3 — большую языковую модель нового поколения, которую без лишней скромности называет «самой способной LLM с открытым исходным кодом». Компания выпустила две версии: Llama 3 8B и Llama 3 70B соответственно с 8 и 70 миллиардами параметров. По словам компании, новые ИИ-модели значительно превосходят соответствующие модели прошлого поколения и являются одними из лучших моделей для генеративного ИИ из ныне существующих.

Источник изображения: vecstock / freepik.com
В подтверждение своих слов Meta✴ приводит результаты популярных тестов MMLU (знания), ARC (способность к обучению) и DROP (анализ фрагментов текста). Llama 3 8B превосходит другие модели своего класса с открытым исходным кодом, такие как Mistral 7B от Mistral и Gemma 7B от Google с 7 миллиардами параметров, по крайней мере в девяти тестах: MMLU, ARC, DROP, GPQA (вопросы по биологии, физике и химии), HumanEval (тест на генерацию кода), GSM-8K (математические задачи), MATH (ещё один математический тест), AGIEval (набор тестов на решение задач) и BIG-Bench Hard (оценка рассуждений на основе здравого смысла).
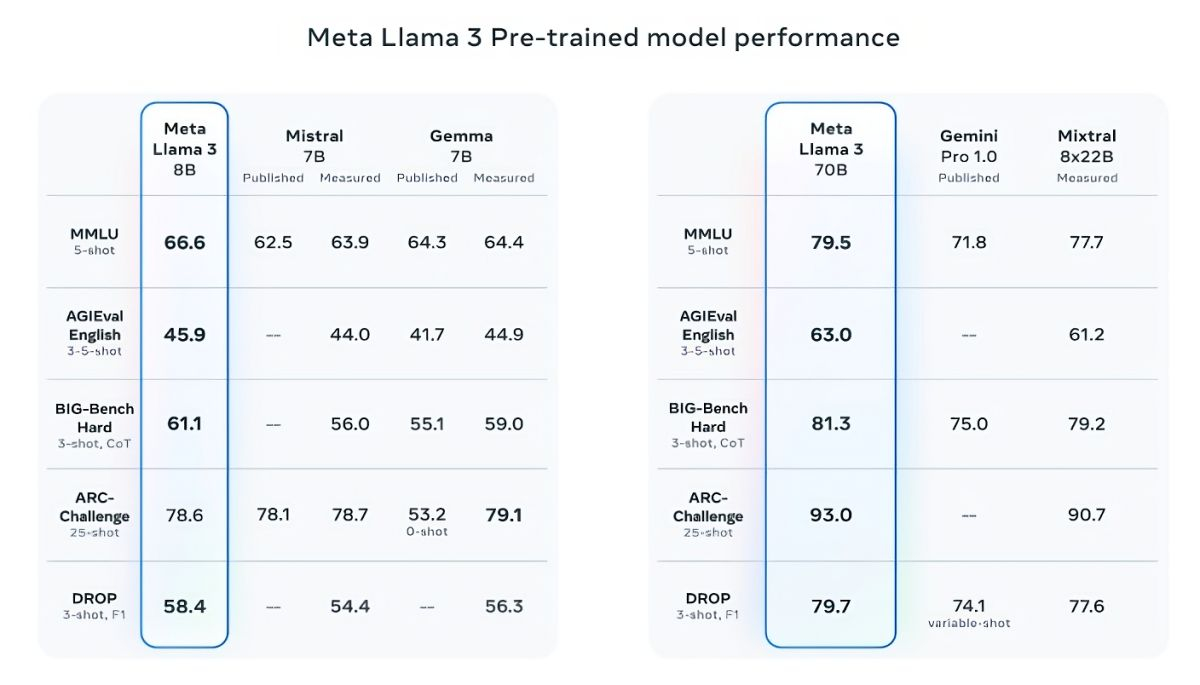
Источник изображений: Meta✴
Mistral 7B и Gemma 7B уже не назвать современными, при этом в некоторых тестах Llama 3 8B не показывает значимого превосходства над ними. Однако куда сильнее Meta✴ гордится более продвинутой моделью, Llama 3 70B, которую ставит в один ряд с другими флагманскими моделями для генеративных ИИ, включая Gemini 1.5 Pro — самую продвинутую в линейке Gemini от Google. Llama 3 70B опережает Gemini 1.5 Pro в тестах MMLU, HumanEval и GSM-8K, но уступает передовой модели Claude 3 Opus от Anthropic, превосходя лишь слабейшую модель серии, Sonnet, в пяти тестах: MMLU, GPQA, HumanEval, GSM-8K и MATH. Meta✴ также разработала собственный набор тестов, от написания текстов и кода до обобщений и выводов, в котором Llama 3 70B обошла Mistral Medium, GPT-3.5 от OpenAI и Claude Sonnet от Anthropic.
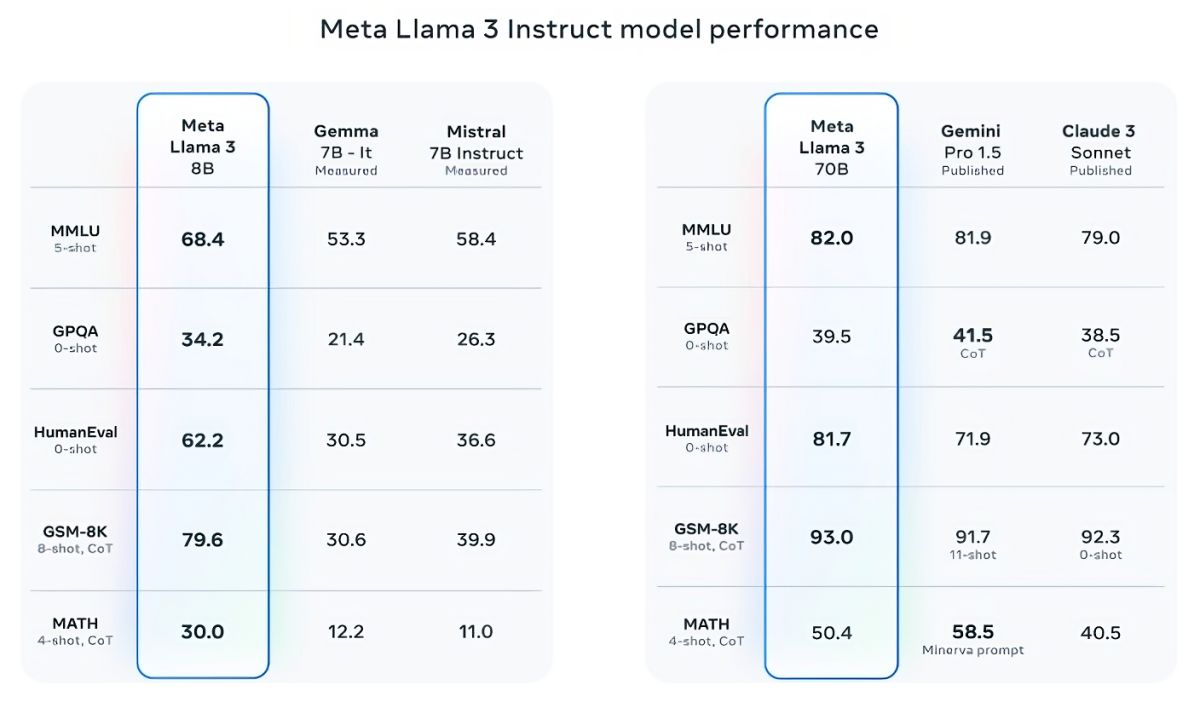
По словам Meta✴, новые модели более «управляемы», реже отказываются отвечать на вопросы и в целом выдают более точную информацию, в том числе в некоторых научных областях, что, вероятно, обосновано огромным количеством данных, использованных для их обучения: 15 триллионов токенов и 750 миллиардов слов, что в семь раз больше, чем в случае с Llama 2.
Откуда столько данных? Meta✴ ограничилась заверением, что все они взяты из «общедоступных источников». При этом в наборе данных для обучения Llama 3 содержалось в четыре раза больше кода в сравнении с использованным для Llama 2, а 5 % набора составляли данные на 30 отличных от английского языках, чтобы улучшить работу с ними. Кроме того, использовались синтетические данные, то есть полученные от других ИИ-моделей.
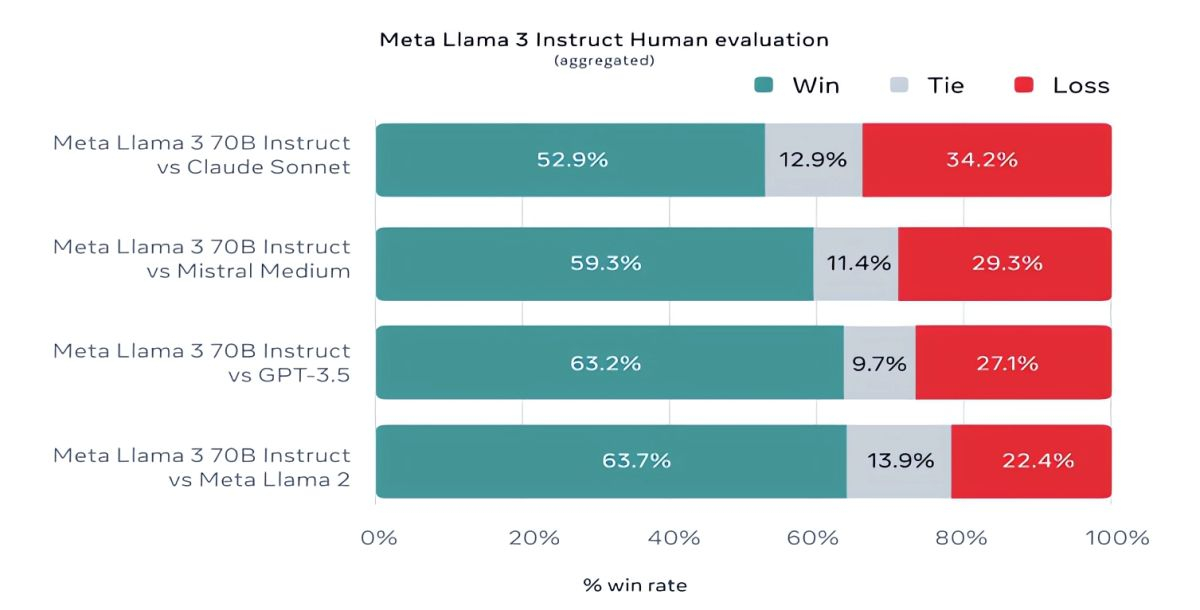
«Наши текущие ИИ-модели настроены отвечать лишь на английском, но мы обучаем их с использованием данных на других языках, чтобы ИИ лучше распознавал нюансы и закономерности», — прокомментировала Meta✴.
Вопрос необходимого количества данных для дальнейшего обучения ИИ в последнее время поднимается особенно часто, и Meta✴ уже успела подпортить репутацию на этом поприще. Не так давно сообщалось, что Meta✴ в погоне за конкурентами «скармливала» ИИ защищённые авторским правом электронные книги, хотя юристы компании предупреждали о возможных последствиях.
Что касается безопасности, Meta✴ встроила в новое поколение собственных ИИ-моделей несколько протоколов безопасности, таких как Llama Guard и CybersecEval, чтобы бороться с неправомерным использованием ИИ. Компания также выпустила специальный инструмент Code Shield для анализа безопасности кода открытых моделей генеративных ИИ, позволяющий обнаружить потенциальные уязвимости. Известно, что ранее эти же протоколы не уберегли Llama 2 от недостоверных ответов и выдачи персональной медицинской и финансовой информации.
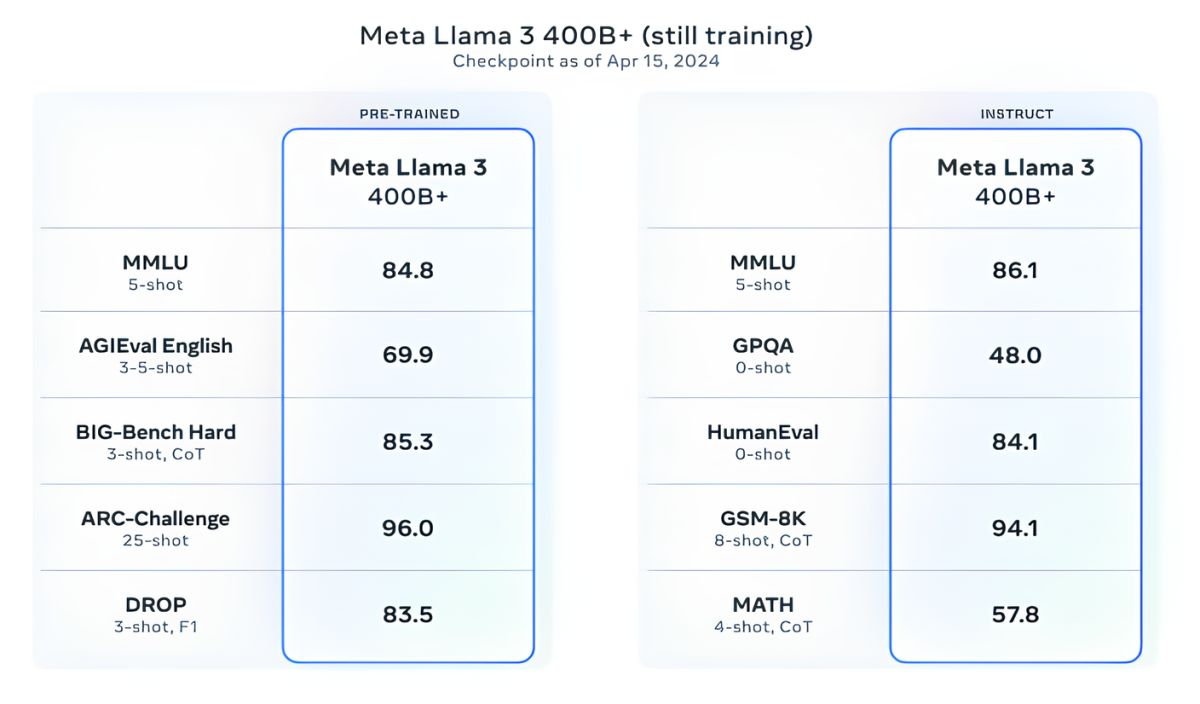
Но и это ещё не всё. Meta✴ обучает модель Llama 3 с 400 миллиардами параметров — она сможет разговаривать на разных языках и принимать больше входящих данных, в том числе работать с изображениями. «Мы стремимся сделать Llama 3 многоязычной и мультимодальной моделью, умеющей учитывать больше контекста. Мы также стараемся улучшить производительность и расширить возможности языковой модели в рассуждениях и написании кода», — сказали в Meta✴.
Источник:










 Подписаться
Подписаться
Все комментарии премодерируются.