|
Опрос
|
реклама
Быстрый переход
На Луну отправят цифровой архив для хранения в течение миллиардов лет данных о Земле и людях
19.09.2023 [15:21],
Геннадий Детинич
Сообщается, что фонд Arch Mission Foundation готовит к отправке на Луну уникальный носитель для хранения в течение миллиардов лет данных о Земле и земной цивилизации. Подобные архивы планируется разбросать по другим небесным телам Солнечной системы, чтобы в далёком будущем люди смогли прикоснуться к истории планеты и людей, если по каким-то причинам на самой Земле эти данные будут утеряны. 
Источник изображения: Pixabay Следует сказать, что это не первая попытка фонда сохранить память о людях и Земле. Ранняя версия архива в виде 5-слойного диска была отправлена в космос в бардачке автомобиля Tesla Roadster, который компания Илона Маска запустила в качестве доказательства способности доставлять полезную нагрузку на орбиту Марса. Второй архив в виде 25-слойного носителя был отправлен на Луну в израильском спускаемом аппарате Beresheet, но тот разбился при посадке. Очередной накопитель фонда также должен был быть доставлен на лунную поверхность, что планировалось совершить на спускаемом аппарате Peregrine Mission One компании Astrobotic. Однако компания затянула с изготовлением аппарата, а потом произошёл взрыв на ракете-носителе Vulcan Centaur компании United Launch Alliance (UAL), которая готовит его запуск. Тем самым начало миссии задержалось больше чем на год, но возможно, состоится в ноябре этого года. Носитель Arch Mission Foundation представляет собой 120-мм 4-граммовый диск в специальном картридже. Четыре верхних слоя содержат инструкцию в текстовом и графическом виде, как самому собрать DVD-проигрыватель. Это примерно 60 тыс. страниц, доступных для чтения с оптическим увеличением от 100 до 200 крат. Эта информация поможет читателю извлечь и интерпретировать данные, записанные на остальных 21 слоях уже как на DVD-диске. Содержание первых слоёв также включает в себя учебник, состоящий из тысяч страниц, на которых раскрываются значения более миллиона слов и понятий на многих языках. Кроме того, в него входят коллекции знаний по многим предметным областям, например, набор жизненно важных статей из «Википедии». 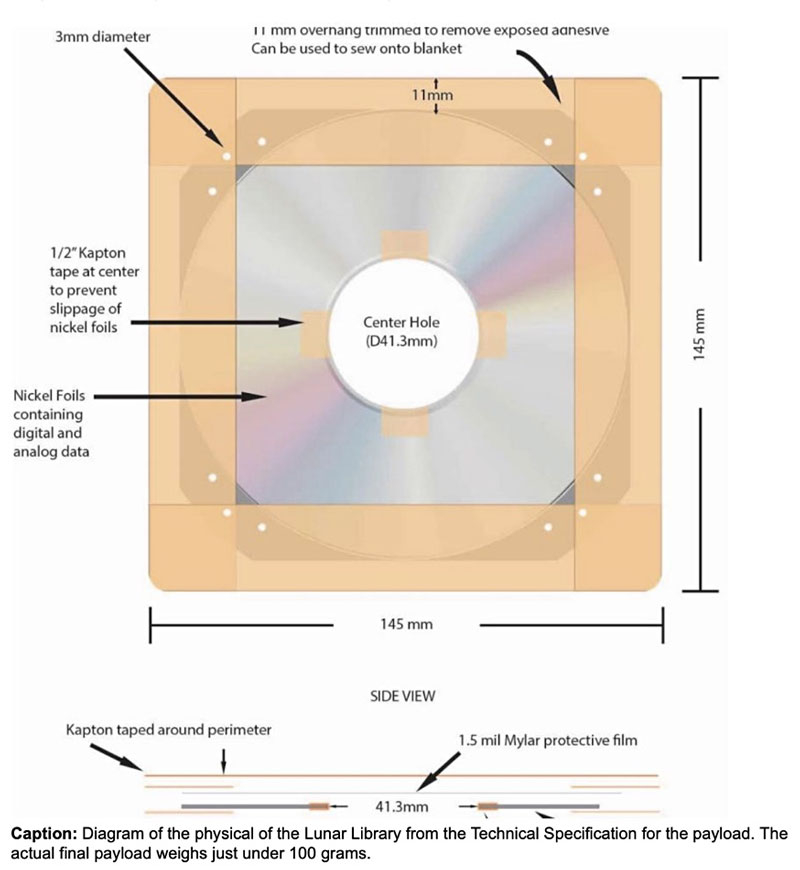
25-слойный носитель Arch Mission Foundation Каждый слой DVD-диска содержит свыше 100 Гбайт сжатых цифровых данных или более 200 Гбайт в распакованном виде. В набор для архива включены англоязычная «Википедия», книжная библиотека Project Gutenberg, интернет-архив, информация о почти 7000 языках мира с полным набором данных PanLex и многое другое. Особняком стоят данные об известном фокуснике-иллюзионисте Дэвиде Копперфильде (David Copperfield). Он является одним из спонсоров проекта и позаботился, чтобы о нём было как можно больше данных в архиве, включая описание всех его знаменитых фокусов. У «Яндекса» украли и опубликовали 45 Гбайт исходных кодов — в компании взлом отрицают
26.01.2023 [11:48],
Павел Котов
В Сети появились архивы с исходными кодами проектов «Яндекса». В компании признали их подлинность — материалы действительно были похищены из внутреннего репозитория, — но отвергли предположения, что это произошло в результате взлома. 
Источник изображения: yandex.ru/company Общий объём опубликованных злоумышленниками архивов (.tar.bz2) составил более 44,7 Гбайт — хакеры утверждают, что им удалось получить доступ к исходным кодам проектов «Яндекса» за исключением правил антиспама. Произошло это, по версии похитителей данных, в июле 2022 года. В архивах представлены материалы на языках Python, C++, Go и TypeScript, а также методы работы с данными Protocol Buffers, YAML и JSON, говорится в публикации на «Хабре». К странным особенностям информации в архивах относятся большое количество вспомогательного кода на Python 2.7 и единая дата всех файлов и папок — «2022-02-24», что расходится с заявлениями хакеров. Представители «Яндекса» признали подлинность опубликованных материалов, но заявили, что взлома не было: «Служба безопасности "Яндекса" обнаружила в открытом доступе фрагменты кода из внутреннего репозитория. Однако, их содержимое отличается от текущей версии репозитория, которая используется в сервисах "Яндекса"». В компании также подчеркнули, что репозитории не предназначены для хранения персональных данных пользователей, так что угрозы им нет, но всё же проводят по факту инцидента расследование: «Мы проводим внутреннее расследование о причинах попадания фрагментов исходного кода в открытый доступ, но не видим какой-либо угрозы для данных наших пользователей или работоспособности платформы». Знакомый с ситуацией источник сообщил, что исходные коды проектов «Яндекса» попали в Сеть по вине одного из сотрудников. Стоит отметить, что утекшие исходные коды в большей степени интересны для изучения, но напрямую использовать и запустить на их основе «собственный «Яндекс» вряд ли получится. Здесь задействовано множество специфичных решений, в том числе заточенных под инфраструктуру самого «Яндекса». А для ИИ-проектов нет самого главного — натренированных нейросетей и набора данных для обучения тоже нет. «Яндекс» научил нейросеть расшифровывать архивные документы даже с дореволюционной орфографией
25.01.2023 [13:19],
Павел Котов
Специалисты «Яндекса» обучили нейросети расшифровке архивных записей — теперь препятствиями не являются ни рукописный текст, ни дореволюционная орфография. Поработать с технологией можно уже сейчас, открыв службу «Поиск по архивам», в которой доступны более 2,5 млн страниц исторических документов и их текстовая расшифровка. 
Источник изображения: Яндекс Нейросеть была обучена при помощи сотен тысяч рукописных строк в реальных архивных документах, датированных с XVIII по XIX вв., а также десятков миллионов примеров, которые были сгенерированы. В работе участвовали эксперты — они производили расшифровку и разметку документов, а также контролировали качество работы системы. Прочитать такие рукописи неподготовленному человеку очень сложно, но нейросеть «Яндекса» справляется с задачей почти мгновенно. При наличии расшифровки появилась возможность быстро находить документы с упоминанием ключевых слов, например, названий населённых пунктов и фамилий. Служба «Поиск по архивам» поможет в работе историкам, социологам, демографам и генеалогам, а также тем, кто не обладает профессиональной подготовкой, но хочет больше узнать об истории своей семьи. Первыми в базе появились материалы Главархива Москвы, потому что нейросеть обучали на них; впоследствии коллекция пополнилась документами из архивов Оренбургской и Новгородской областей. Со временем к проекту подключатся и другие архивы, документов станет больше. Сейчас в поиске доступны материалы с XVIII до начала XX вв. — они наиболее популярны у пользователей. В базе есть метрические книги, исповедные ведомости, а также ревизские сказки, в которые внесены результаты переписи населения. Документы открываются как по каталогу, так и через поисковую строку — на странице приводится скан листа и его построчная расшифровка с подсветкой при наведении. |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться