|
Опрос
|
реклама
Быстрый переход
Qualcomm вернулась в большие вычисления: представлены ИИ-ускорители AI200 и AI250 для дата-центров
27.10.2025 [23:13],
Николай Хижняк
Компания Qualcomm анонсировала два ускорителя ИИ-инференса (запуска уже обученных больших языковых моделей) — AI200 и AI250, которые выйдут на рынок в 2026 и 2027 годах. Новинки должны составить конкуренцию стоечным решениям AMD и Nvidia, предложив повышенную эффективность и более низкие эксплуатационные расходы при выполнении масштабных задач генеративного ИИ. 
Источник изображений: Qualcomm Оба ускорителя — Qualcomm AI200 и AI250 — основаны на нейронных процессорах (NPU) Qualcomm Hexagon, адаптированных для задач ИИ в центрах обработки данных. В последние годы компания постепенно совершенствовала свои нейропроцессоры Hexagon, поэтому последние версии чипов уже оснащены скалярными, векторными и тензорными ускорителями (в конфигурации 12+8+1). Они поддерживают такие форматы данных, как INT2, INT4, INT8, INT16, FP8, FP16, микротайловый вывод для сокращения трафика памяти, 64-битную адресацию памяти, виртуализацию и шифрование моделей Gen AI для дополнительной безопасности. Ускорители AI200 представляют собой первую систему логического вывода для ЦОД от Qualcomm и предлагают до 768 Гбайт встроенной памяти LPDDR. Система будет использовать интерфейсы PCIe для вертикального масштабирования и Ethernet — для горизонтального. Расчётная мощность стойки с ускорителями Qualcomm AI200 составляет 160 кВт. Система предполагает использование прямого жидкостного охлаждения. Для Qualcomm AI200 также заявлена поддержка конфиденциальных вычислений для корпоративных развертываний. Решение станет доступно в 2026 году.  Qualcomm AI250, выпуск которого состоится годом позже дебютирует с новой архитектурой памяти, которая обеспечит увеличение пропускной способности более чем в 10 раз. Кроме того, система будет поддерживать возможность дезагрегированного логического вывода, что позволит динамически распределять ресурсы памяти между картами. Qualcomm позиционирует его как более эффективное решение с высокой пропускной способностью, оптимизированное для крупных ИИ-моделей трансформеров. При этом система сохранит те же характеристики теплопередачи, охлаждения, безопасности и масштабируемости, что и AI200. Помимо разработки аппаратных платформ, Qualcomm также сообщила о разработке гипермасштабируемой сквозной программной платформы, оптимизированной для крупномасштабных задач логического вывода. Платформа поддерживает основные наборы инструментов машинного обучения и генеративного ИИ, включая PyTorch, ONNX, vLLM, LangChain и CrewAI, обеспечивая при этом беспроблемное развертывание моделей. Программный стек будет поддерживать дезагрегированное обслуживание, конфиденциальные вычисления и подключение предварительно обученных моделей «одним щелчком мыши», заявляет компания. IBM заставила алгоритм коррекции ошибок квантовых компьютеров работать на обычных чипах AMD
24.10.2025 [19:57],
Сергей Сурабекянц
Сегодня компания IBM сообщила о реальной возможности запуска ключевого алгоритма коррекции ошибок квантовых вычислений на общедоступных чипах производства компании Advanced Micro Devices. Это открытие может существенно приблизить начало коммерческого использования квантовых вычислений. 
Источник изображения: IBM Квантовые компьютеры используют так называемые кубиты для решения специфических задач, например, расчёта взаимодействия триллионов атомов на протяжении больших временных промежутков. На поиск ответа обычным компьютерам потребовались бы тысячи лет. Однако квантовые вычисления подвержены ошибкам и влиянию шума, которые могут быстро свести на нет вычислительную мощность квантового чипа. В июне IBM заявила, что разработала алгоритм для работы с квантовыми чипами, способный устранять подобные ошибки. В исследовательской работе, которая должна быть опубликована 27 октября, компания продемонстрирует его запуск в реальном времени на чипе AMD типа Valve Array («программируемая вентильная матрица»). 
Источник изображения: AMD По словам директора по исследованиям IBM Джей Гамбетта (Jay Gambetta), исследование доказало, что новый алгоритм IBM для коррекции ошибок квантовых вычислений не только работает в реальном мире, но и запускается на существующем чипе AMD, который «смехотворно дёшев». Он также подчеркнул, что «внедрение алгоритма и демонстрация того, что он действительно в 10 раз быстрее, чем требуется, — это большая задача», которая была завершена на год раньше запланированного. IBM стремится завершить работы по созданию полноценного квантового компьютера Starling к 2029 году. 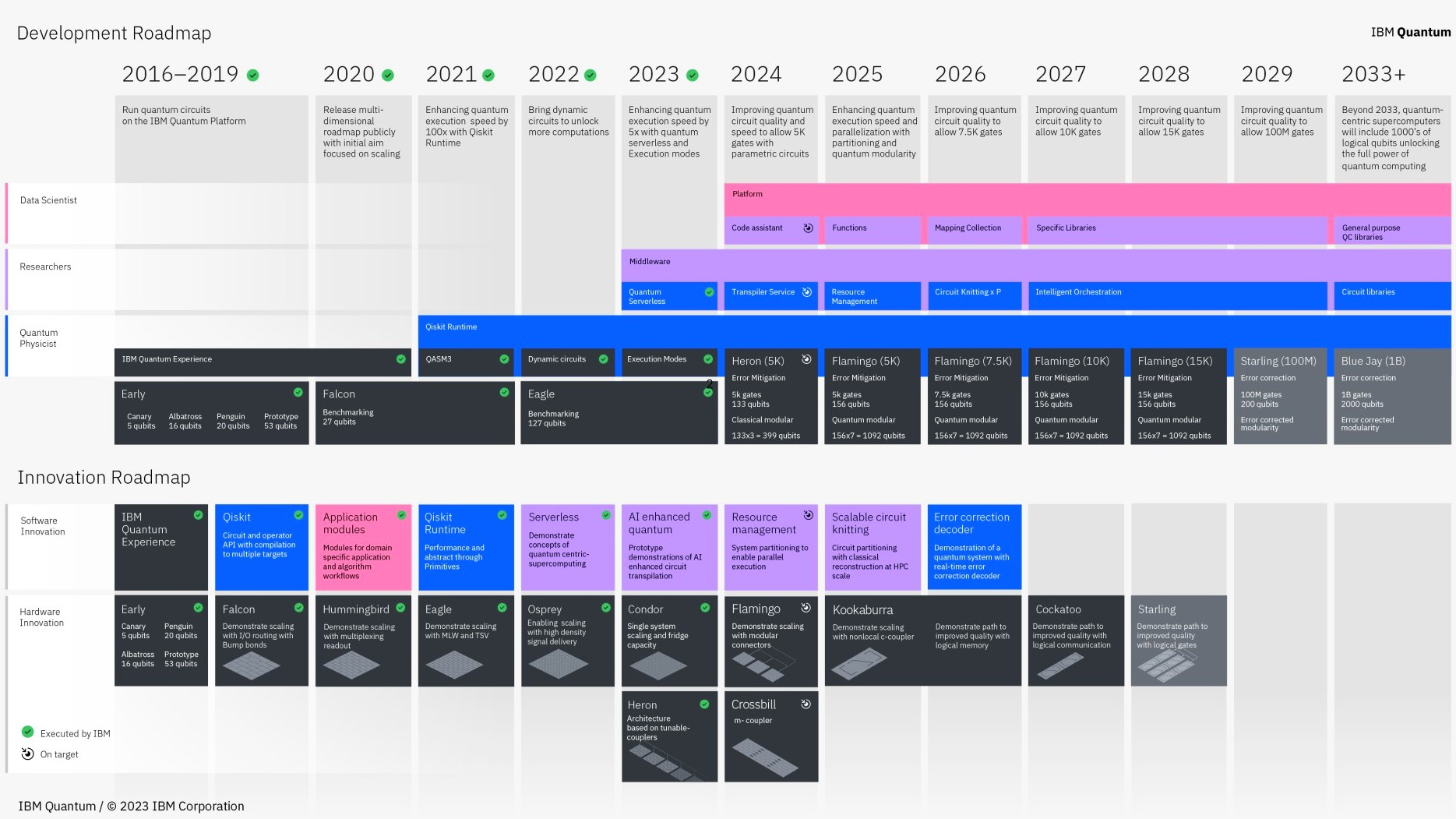
Источник изображения: IBM Google на практике доказала квантовое превосходство — новый алгоритм сулит прорывы в науке, технике и медицине
23.10.2025 [13:38],
Геннадий Детинич
Несколько лет назад Google выступила с заявлением о достижении первого в мире квантового превосходства, которое вызвало резкое неприятие в отрасли высокопроизводительных вычислений. С точки зрения Google, она была права, хотя тот первый алгоритм не имел никакой практической ценности. Сегодня компания снова сообщила о достижении квантового превосходства — но уже для алгоритма, имеющего практическую ценность. Если Google права, это — новая глава в истории. 
Источник изображений: Google Напомним, в октябре 2019 года сотрудники Google в журнале Nature опубликовали статью, в которой рассказали о работе одного статистического алгоритма на своём квантовом компьютере Sycamore с 53 кубитами. Квантовая система за 200 секунд решила синтетическую задачу, на решение которой, по мнению Google, одному из лучших на тот момент суперкомпьютеров — IBM Summit — потребовалось бы 10 000 лет. За это сравнение Google потом ответила сполна, но активнее всего против неё выступили китайские программисты, которые за считанные часы решили ту же задачу на дюжине графических карт Nvidia. Сегодня в активе Google новый квантовый процессор — Willow, со 105 кубитами, и серьёзный багаж опыта за шесть лет развития квантовых алгоритмов. Поэтому сотрудники Google в журнале Nature опубликовали новую статью, также посвящённую достижению квантового превосходства. Но в этот раз компания представила алгоритм, имеющий практическую ценность. Он используется для симуляции ядерных взаимодействий в молекулах и может быть использован для прорывных исследований в науке и технике. По словам Google, классический компьютер будет решать сходную по объёму задачу в 13 тыс. раз дольше. В частности, если квантовая система затратила на работу 2,1 часа, то на суперкомпьютере Frontier работа алгоритма продлится 3,2 года. Для оптимизации расчётов с использованием квантовых характеристик элементарных частиц и их взаимодействий компания сосредоточилась на технологии, которую назвала «квантовым эхом». На практике это — последовательность обычных одно- и двухкубитных операций, которые ведут к изменению квантовых состояний кубитов в рабочем массиве. Каждый кубит связан со своими соседями, что позволяет его состоянию суперпозиции влиять на состояния всех окружающих кубитов. После запуска сигнала включаются двухкубитные вентили в квантовой схеме, которая по достижении завершающего этапа производит обратные переключения. Это должно возвращать систему в исходное состояние. Однако, чтобы этого не произошло и получилось настоящее «эхо» — возвращение искажённого сигнала, — в процессе первого этапа параллельно активируются однокубитные вентили со случайным параметром. Это создаёт гарантии получения на выходе иного сигнала, чем тот, что был изначально подан на вход системы. Однако, поскольку это квантовая система, в ней происходят странные вещи. «В квантовом компьютере эволюция в прямом и обратном направлении накладывается друг на друга», — поясняют в Google. Один из способов понять эту интерференцию — рассмотреть её с точки зрения вероятностей. У системы есть несколько путей между начальной точкой и точкой отражения, где она переходит от эволюции в прямом направлении к эволюции в обратном. С каждым из этих путей связана определённая вероятность. А поскольку речь идёт о квантовой механике, эти пути могут накладываться друг на друга, усиливая одни вероятности за счёт других. В конечном счёте именно эта интерференция определяет, в каком состоянии окажется система.  Самое важное — как Google удалось превратить квантовые эхо-сигналы в алгоритм? Само по себе одно «эхо» мало что может рассказать о системе: из-за вероятностной природы квантовой механики любые два запуска могут показать разное поведение. Но если повторить операции многократно, можно начать разбираться в деталях квантовой интерференции — накапливать статистику поведения системы. Проделать такое на классическом компьютере — значит растянуть работу на годы. Квантовый же компьютер позволяет просто перезапускать операции с разными случайными однокубитными вентилями и быстро получать множество примеров начальных и конечных состояний — а значит, и представление о распределении вероятностей в весьма конкретной физической системе. В этом и заключается квантовое преимущество Google. Точное поведение квантового эха небольшой сложности можно смоделировать с помощью любого ведущего суперкомпьютера. Но на это уходит слишком много времени, поэтому многократное моделирование становится невозможным. По оценкам авторов статьи, измерение, на которое у квантового компьютера ушло 2,1 часа, у суперкомпьютера Frontier заняло бы около 3,2 года. Впрочем, остаётся вероятность разработки более эффективного алгоритма, который снова отсрочит приход квантового преимущества. В чём же практическая польза такого алгоритма? Повторная выборка может напоминать статистическую выборку методом Монте-Карло, которая используется для изучения поведения самых разных физических систем. Однако в Google подчёркивают, что речь идёт не о простом моделировании, а о некоторой «естественной копии» реального мира, поведение которой можно понять с помощью квантовых эхо. В частности, предложенная компанией платформа имитирует поведение небольшой молекулы, которую можно исследовать с помощью ядерного магнитного резонанса (ЯМР). ЯМР-спектроскопия основана на том, что ядро каждого атома обладает квантовым свойством — спином. Когда ядра находятся близко друг к другу, например в одной молекуле, их спины могут влиять друг на друга. ЯМР-спектроскопия использует магнитные поля и фотоны для управления этими спинами и позволяет получать структурные данные, например о расстоянии между двумя заданными атомами. Но по мере увеличения размера молекул спиновые сети могут растягиваться на большие расстояния, и их становится всё сложнее моделировать. Поэтому ЯМР-спектроскопия ограничена изучением взаимодействия относительно близко расположенных спинов. Предложенный Google алгоритм позволяет рассчитать взаимодействия спинов в образцах на больших расстояниях между атомами — таких, которые недоступны для современных приборов. Это может использоваться при изучении реальных химических веществ, например, если в них внедрить «эха-излучающие» атомы (в работе предложено использовать изотоп углерод-13). Квантовая система поможет интерпретировать поведение «растянутой» физической структуры (молекулы), опираясь на данные ЯМР-спектроскопии. Классические системы здесь не помощники — ждать результата три года никто не будет. Квантовое моделирование методом эха, предложенное Google, даст оценку экспериментальным данным, которые иначе невозможно интерпретировать. На данный момент команда ограничилась демонстрацией метода на очень простых молекулах, так что эта работа в основном служит подтверждением концепции. Но исследователи с оптимизмом смотрят в будущее и считают, что эту систему можно использовать для получения структурной информации о молекулах на расстояниях между атомами, которые в настоящее время недоступны для ЯМР-спектроскопии. Они перечисляют множество потенциальных преимуществ, которые следует учитывать при обсуждении статьи. Есть немало исследователей, желающих найти новые способы использования своих ЯМР-установок, так что, скорее всего, довольно быстро станет ясно, какой из подходов окажется практически полезным — квантовый или классический. Китайцы научились моделировать масштабные квантовые процессы на классических компьютерах
22.10.2025 [20:13],
Геннадий Детинич
Квантовая революция подкралась откуда не ждали — китайские инженеры сделали, казалось бы, невозможное: на классическом суперкомпьютере они запустили квантовую симуляцию сложных химических процессов, чего ранее ожидали лишь с появлением квантовых компьютеров. В этом им помогла нейросеть, обученная работать с квантовыми уравнениями. 
Источник изображения: ИИ-генерация Grok 4/3DNews Значительного прорыва в квантовой химии добились китайские специалисты из компании Sunway, которые показали успешное моделирование сложного поведения молекул на классическом суперкомпьютере Oceanlite с привлечением к решению задачи искусственного интеллекта. Традиционно такие симуляции требуют огромной вычислительной мощности, часто недоступной даже для мощнейших в мире вычислительных платформ из-за экспоненциального роста числа квантовых состояний. Однако привлечение нейронных сетей позволило преодолеть эти ограничения, обработав поведение почти «настоящих» молекул с десятками электронов и более чем 100 спиновыми орбиталями — функциями спиновых координат, иначе говоря, комплексной информацией о спине электрона и его положении в пространстве в электронном облаке в составе молекулы. Тем самым исследователи показали, что для квантовой физики и химии вовсе необязательно ждать пришествия квантовых компьютеров. При определённом умении работать с квантовым миром можно делать это уже сегодня. В квантовой механике состояние системы описывается волновой функцией Ψ, которая определяет все возможные конфигурации частиц — от позиций и спинов электронов до энергетических уровней и вероятностей. С ростом числа частиц пространство состояний экспоненциально расширяется, делая точное моделирование на классических компьютерах практически невозможным и вынуждая учёных прибегать к упрощениям. Упрощения заставляют балансировать между точностью симуляции процессов и требуемыми для расчётов ресурсами. На современных суперкомпьютерах высочайшей точности можно достичь лишь при моделировании совсем простых молекул, что не даёт развернуться для научных прорывов. Тогда китайские инженеры начали рассматривать вариант стыка ИИ и квантовых симуляций, что привело к разработке нейронных сетей квантовых состояний — NNQS. Эта технология позволила сочетать масштабируемость машинного обучения с квантовой точностью. Тем самым появилась возможность на обычной системе моделировать многоэлектронные молекулы с сильными корреляциями, в которых взаимодействуют десятки и даже сотни спиновых орбиталей. Нейронную сеть обучили предсказывать волновую функцию для моделирования молекулы со 120 спиновыми орбиталями, что стало самой масштабной симуляцией на классическом компьютере — пусть даже с приставкой «супер». Сеть оценивала вероятные положения электронов, вычисляя локальные энергии и корректируя параметры до соответствия реальной квантовой структуре. Этот метод позволил симулировать динамику электронов в сложных молекулах, открывая путь к анализу процессов, ранее недоступных для вычислений. Расчёты были проделаны на суперкомпьютере Oceanlite, построенном на 384-ядерных процессорах Sunway SW26010-Pro. Нюанс в том, что эта система создавалась для высокопроизводительной обработки данных, а не для ИИ. Для «подселения» ИИ на непривычную для него вычислительную архитектуру пришлось адаптировать программное обеспечение, чтобы обеспечить наивысший параллелизм и оптимальную загрузку всех миллионов ядер платформы. Оптимизация была проведена настолько блестяще, что обеспечила 92 % сильного и 98 % слабого масштабирования задач при подгонке «железа» под программную нагрузку. В целом китайская классическая платформа справилась с химической симуляцией молекул со 120 спиновыми орбиталями — немыслимый ранее масштаб для квантовой симуляции на классических платформах. Без лишней скромности учёные заявили о прорыве для ИИ в квантовом моделировании. И у этого будут последствия. Надеемся, хорошие. NextSilicon похвасталась превосходством ускорителя Maverick-2 над Nvidia HGX B200 и представила чип Arbel на базе RISC-V
22.10.2025 [20:09],
Николай Хижняк
Стартап NextSilicon, основанный в 2017 году, представил специализированный ускоритель Maverick-2. Компания называет его интеллектуальным вычислительным ускорителем (Intelligent Compute Accelerator). Его впервые анонсировали ещё в прошлом году. NextSilicon утверждает, что Maverick-2 превосходит ускоритель Nvidia HGX B200 и процессоры Intel Sapphire Rapids в высокопроизводительных вычислениях и задачах искусственного интеллекта. 
Источник изображений: NextSilicon Maverick-2, созданный по 5-нм техпроцессу TSMC, доступен в виде однокристальной карты расширения PCIe с 96 Гбайт памяти HBM3e и энергопотреблением 300 Вт, а также в виде двухкристальной версии на модуле OAM с 192 Гбайт памяти HBM3e и энергопотреблением 600 Вт. Согласно внутренним тестам, Maverick-2 обеспечивает до 4 раз более высокую производительность в операциях FP64 на ватт, чем Nvidia HGX B200, и более чем в 20 раз более высокую эффективность, чем процессоры Intel Xeon Sapphire Rapids. В тестах производительности GUPS он достиг 32,6 GUPS при 460 Вт мощности, что, как сообщается, в 22 раза быстрее, чем у центральных, и в 6 раз быстрее, чем у графических процессоров. В рабочих нагрузках HPCG он достиг 600 GFLOPS при 750 Вт, потребляя при этом примерно вдвое меньше энергии, чем конкурирующие решения. Компания объясняет этот прирост эффективности архитектурой, основанной на потоках данных, которая переносит управление ресурсами с аппаратного уровня на адаптивное программное обеспечение, позволяя использовать большую часть площади кремния для вычислений, а не для управляющей логики.  Компания также анонсировала Arbel — чип корпоративного класса на базе RISC-V, также построенный по 5-нм техпроцессу TSMC. NextSilicon утверждает, что Arbel уже превосходит текущие разработки RISC-V конкурентов, а также ядра Intel Lion Cove и AMD Zen 5. Arbel оснащён 10-канальным конвейером инструкций с 480-элементным буфером переупорядочивания для высокой загрузки ядра, работающим на частоте 2,5 ГГц. Чип может выполнять до 16 скалярных инструкций параллельно и включает четыре 128-битных векторных блока для параллельной обработки данных. Кеш первого уровня объёмом 64 Кбайт и большой общий кеш третьего уровня обеспечивают высокую пропускную способность памяти и низкую задержку, что позволяет сократить узкие места в производительности в ресурсоёмких приложениях.  NextSilicon не поделилась ни полными результатами тестов нового чипа, ни информацией о том, когда он станет доступен. В то же время компания заявляет, что Arbel представляет собой шаг к полностью открытой, программно-адаптивной кремниевой платформе для будущих систем высокопроизводительных вычислений и искусственного интеллекта. Левитирующие электроны — новые кандидаты на роль идеальных кубитов
10.10.2025 [11:55],
Геннадий Детинич
Проблема с квантовыми компьютерами не в том, чтобы доказать их возможность. Вся трудность заключается в масштабировании таких вычислителей. Этому мешают большие физические размеры кубитов и сложности в управлении ими. Идеальный кубит пока не создан, но кандидаты на его роль появляются всё чаще и чаще. 
Источник изображения: techspot.com Традиционные архитектуры кубитов, такие как сверхпроводящие схемы или ионные ловушки, чувствительны к внешним воздействиям, дороги в производстве и требуют сложной криогенной инфраструктуры. Исследователи из чикагского стартапа EeroQ предлагают перспективный подход, разработав и создав в лаборатории систему, которая использует одиночные электроны, «плавающие» на поверхности жидкого гелия. Предложенный метод обещает привести к созданию миллионов кубитов на одном чипе, попутно устраняя узкие места в интерфейсе и системе управления кубитами и, что самое важное, такие квантовые процессоры можно выпускать с использованием зрелых техпроцессов для производства чипов, что будет очень дёшево. Концепция EeroQ основана на эффекте так называемого «зеркального заряда» на границе раздела сред — это виртуальный заряд, который является следствием стабилизации электромагнитного поля заряжённой частицы рядом с проводником или диэлектриком. Когда отрицательно заряженный электрон приближается к поверхности жидкого гелия, под её поверхностью как бы возникает слабый положительный заряд, стабилизирующий положение электрона в пространстве. Дополнительным стабилизатором выступает жидкий гелий. В результате электрон парит над поверхностью гелия. За счёт стабилизирующих факторов он становится менее чувствителен к помехам — главному бичу всех схем кубитов. Предложенная схема — это готовая ловушка для электронов. Сверхтекучие свойства жидкого гелия позволяют ему без помех равномерно распределяться по микроканалам в чипе. Эта же среда открывает возможность по транспортировке электронов из одной ловушки в другую, что означает способность чипа выполнять вычисления с использованием электронов как кубитов. В своих экспериментах исследователи EeroQ показали, что электроны могут путешествовать на фантастические расстояния по чипу — до одного километра и больше. 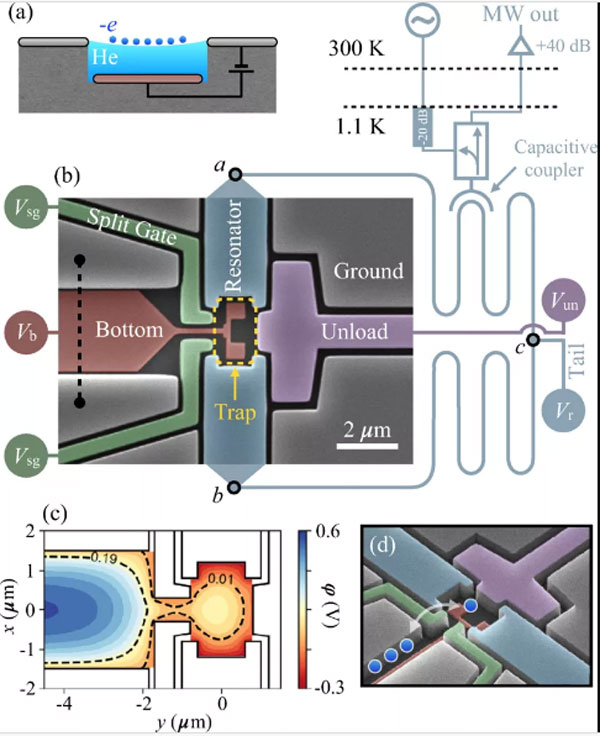
Источник изображения: EeroQ Используя вольфрамовую нить и электромагнитные электроды, учёные заполняли ловушки электронами, где изолировали их с помощью энергетических барьеров, просто повышая напряжение на контактах ловушки. Поскольку ловушки подключены к резонаторам, по их частоте можно судить, сколько там электронов. Эти частицы можно буквально по одной выщёлкивать из ловушек, просто меняя высоту энергетических барьеров (напряжение на контактах) до тех пор, пока там не останется одна частица и с ней можно начать работать, как с кубитом. Ключевым преимуществом разработки является высокая спиновая когерентность электрона (способность долго оставаться в состоянии суперпозиции), которая, по словам главного научного эксперта EeroQ Йоханнеса Полланена (Johannes Pollanen), «не может быть хуже, чем в кремнии и потенциально достигает фантастических значений». Система использует стандартные CMOS-процессы для изготовления электродов и схем, что упрощает массовое производство и позволяет интегрировать миллионы кубитов без суперсовременных полупроводниковых сканеров. Учёные уже продемонстрировали захват и контроль одиночного электрона, а также его перемещение на значительные расстояния — до километра — без потери стабильности. Следующий этап — это кодирование информации в спине электрона для создания работающих кубитов. Для снижения декогеренции от неоднородных магнитных полей планируется использовать пары электронов с противоположными спинами: любая фаза, нарушенная в одном, будет компенсирована в другом. Это позволит выполнять логические операции и взаимодействия между кубитами, перемещая электроны по чипу для реализации квантовых алгоритмов. Подход EeroQ может революционизировать квантовые вычисления, сделав платформы компактными, дешёвыми и масштабируемыми, с минимальным внешним интерфейсом для управления миллионами кубитов. Хотя технология пока на ранней стадии — без полноценных вентилей и крупномасштабной интеграции — её потенциал огромен. Устранение ключевых барьеров, таких как сложность производства и чувствительность к шуму, открывает путь к практическим квантовым компьютерам, способным решать задачи, недоступные классическим системам. В итоге это открытие подчёркивает, как переосмысление материалов и физических эффектов может преодолеть давние ограничения в области квантовых вычислений. Разработчиков квантовых компьютеров заливают деньгами — их акции взлетели на 20 % за неделю
04.10.2025 [15:43],
Геннадий Детинич
На этой неделе акции ряда наиболее популярных компаний в сфере разработки квантовых компьютеров выросли в цене на десятки процентов, что удвоило и даже утроило стоимость ценных бумаг некоторых из них по сравнению с ценой на начало года. Подобный интерес инвесторов объясняется активностью в области квантовых вычислений и вовлечение в этот процесс лидеров отрасли. 
Источник изображения: CNBC Хочется верить, что накачка деньгами квантовых компаний — это не очередной пузырь для инвесторов. Одни, такие как глава квантового подразделения Google — Джулиан Келли (Julian Kelly), обещают создание имеющих практическую ценность квантовых компьютеров к концу десятилетия. Другие, в число которых входит множество независимых экспертов, ожидают медленного продвижения к этой заветной цели в течение десяти и более лет. В чём можно не сомневаться — чем дальше, тем больше будет новостей в области развития квантовых вычислений. Эти новости подогревают рынок, а представители отрасли, например, как специалисты компании Nvidia, будут ещё сильнее возбуждать интерес обещаниями скорого прорыва в развитии технологий. Более того, они уже сообщают о прорыве, обещая ускорение квантовых операций уже сейчас с помощью библиотеки CUDA-X. Герои последних новостей — компании Rigetti Computing и D-Wave. Их акции за последние несколько дней выросли более чем на 20 %. С начала года ценные бумаги Rigetti и D-Wave Quantum подорожали более чем вдвое и втрое соответственно. Акции Arqit Quantum на этой неделе взлетели более чем на 32 %. Компания Rigetti сообщила, что получила заказы на покупку двух своих 9-кубитных квантовых вычислительных систем Novera на общую сумму $5,7 млн. Имя клиента источники не раскрывают. Кроме того, фармацевтическая компания Novo Nordisk и правительство Дании инвестировали €300 млн в венчурный фонд развития квантовых технологий. Ранее в этом году о своих новых квантовых чипах рассказали Microsoft и Amazon. Много интересных анонсов сделала и Nvidia — преимущественно о создании гибридных платформ и интерфейсов. Характерным для этого года событием также стала покупка компанией IonQ из США британского стартапа Oxford Ionics за $1,1 млрд. Около трети миллиарда долларов привлекла финская компания IQM — и таких примеров становится всё больше. Обещанные Джулианом Келли пять лет, отпущенные на достижение прорыва в области квантовых вычислений, не оставляют инвесторам времени на раздумья и подталкивают их вкладывать средства в новую сферу, не вдаваясь в детали критики. Такое поведение тоже имеет право на существование — и нередко приводит к интересным результатам. В Гарварде создали систему для «вечной» работы квантового компьютера
02.10.2025 [15:16],
Геннадий Детинич
Учёные из Гарвардского университета (Harvard University) сообщили о прорыве в создании развитых квантовых компьютеров. За последние пять лет они разработали платформу для поддержки непрерывной работы квантового вычислителя. Платформа сама без участия человека поддерживает кубиты в рабочем состоянии, пополняя их атомами взамен случайно покинувших кубиты частиц, что обеспечивает непрерывную работу системы без досадных сегодня перезагрузок. 
Источник изображения: Harvard University О прорыве сообщила группа физиков Гарварда под руководством бывшего выпускника МФТИ профессора Михаила Лукина. Они создали первую в мире квантовую вычислительную машину, способную работать непрерывно без перезапусков. О достижении рассказано в последнем выпуске журнала Nature. Созданная в лаборатории система позволила квантовой платформе работать более двух часов, а теоретически — бесконечно. В отличие от классических компьютеров, использующих биты с состояниями 0 или 1, квантовые машины оперируют кубитами, в том числе на основе субатомных частиц, которые могут существовать в нескольких состояниях одновременно — в суперпозиции. Это позволяет решать сложные задачи за минуты вместо тысячелетий. Сделанное открытие, достигнутое в партнёрстве с учёными из Массачусетского технологического института (MIT), обещает революцию в медицине, финансах и криптографии, где требуются интенсивные вычисления для моделирования молекул и оптимизации. Основной проблемой квантовых компьютеров на протяжении многих лет оставалась потеря атомов — процесс, при котором субатомные частицы, формирующие кубиты, покидают систему, что ведёт к утрате информации и сбоям. Ранее даже самые передовые устройства работали всего несколько миллисекунд, максимум — около 13 секунд, что делало невозможными длительные расчёты. Это касается не всех квантовых вычислителей, но особенно сильно влияет на кубиты из нейтральных атомов, которыми как раз и занимается в Гарварде группа Лукина. Проект Лукина, запущенный пять лет назад, был направлен именно на преодоление этого барьера. Новая машина с 3000 кубитами демонстрирует стабильность, вводя до 300 000 атомов в секунду для компенсации потерь. Ключевым решением стали два инновационных инструмента: «оптическая решётка-конвейер» и «оптические пинцеты», которые перемещают и пополняют атомы без нарушения квантовой информации. По словам учёных, «теперь ничто фундаментально не ограничивает продолжительность работы наших атомных квантовых компьютеров — мы можем заменять потерянные атомы свежими». Эта технология обеспечивает непрерывность, сохраняя целостность системы. Исследователи подчёркивают, что план дальнейшего развития ясен, и машина уже демонстрирует потенциал для масштабирования. «Это просто область с огромным потенциалом для инноваций, — поясняют исследователи. — Мы устраняем разрыв между тем, что может сделать аппаратное обеспечение, и тем, что обещают алгоритмы. Эта область созрела для открытий». Президент OpenAI: человечеству потребуется 10 млрд ИИ-ускорителей — по одному на каждого жителя Земли
30.09.2025 [06:58],
Алексей Разин
Сейчас стартап OpenAI использует любую возможность для привлечения не только финансовых ресурсов, но и заключения контрактов с поставщиками тех же ускорителей вычислений, коим является Nvidia. Президент компании Грег Брокман (Greg Brockman) убеждён, что человечеству потребуется до 10 млрд ускорителей вычислений, и каждого жителя планеты буквально будет обслуживать отдельный ИИ-чип. 
Источник изображения: Nvidia Своими соображениями президент OpenAI поделился в интервью CNBC, в котором также приняли участие генеральный директор компании Сэм Альтман (Sam Altman), а также глава и основатель Nvidia Дженсен Хуанг (Jensen Huang). По мнению Альтмана, масштабы сотрудничества с Nvidia по своей значимости для человечества окажутся важнее программы доставки до Луны американских астронавтов, которую NASA реализовало в прошлом веке. Альтман видит будущее человечества с неразрывным присутствием «супермозга», созданного искусственным интеллектом и активно влияющего на повседневную жизнь людей. Брокман же считает, что ИИ будет действовать в качестве «агента, который работает на опережение, пока вы спите». Каждый работающий житель Земли, по его мнению, будет использовать ресурсы как минимум одного ускорителя вычислений при выполнении своих должностных обязанностей. «Вам действительно захочется, чтобы у каждого человека был свой собственный выделенный GPU», — охарактеризовал свой прогноз Брокман. Сейчас подобное предсказание может казаться нереалистичным, но достаточно вспомнить, что в начале девяностых годов прошлого века один из основателей Microosft Билл Гейтс (Bill Gates) указывал на неизбежность появления компьютера не только в каждом домохозяйстве, но и на каждом рабочем столе. В какой-то мере его предсказание сбылось, пусть даже если вместо компьютеров в их классической форме речь идёт о смартфонах, которые помещаются в карман. Брокман считает, что сейчас отрасль ИИ на три порядка отстаёт от потенциальных потребностей в вычислительных мощностях, и для создания постоянно функционирующей глобальной системы искусственного интеллекта человечеству может потребоваться до 10 млрд ускорителей вычислений. По сути, это даже больше, чем проживает людей на Земле (8,2 млрд человек). Мир, по мнению Брокмана, движется к состоянию, при котором экономику подпитывают вычисления. Вычислительных мощностей сейчас не хватает, как он считает, а наличие достаточно мощных центров обработки данных в будущем станет определять состоятельность экономики целых стран. В какой-то мере они заменят валюту в качестве источника ресурсов для развития экономики. Клин клином: российские учёные заглушили шумы квантовых вычислений контролируемым шумом
25.09.2025 [11:44],
Геннадий Детинич
В Национальном исследовательском технологическом университете «МИСиС» (НИТУ МИСИС) разработан перспективный протокол для квантовых вычислений, который превращает неизбежный шум в инструмент оптимизации. Учёные предложили введение контролируемого шума в квантовые схемы, что позволяет повышать эффективность поиска оптимальных решений. Технология обещает значительно увеличить точность и скорость квантовых алгоритмов, делая их применимыми для реальных задач. 
Источник изображения: ИИ-генерация Grok 3/3DNews Одной из ключевых проблем квантового машинного обучения является сложность тренировки и оптимизации моделей. Из-за огромного пространства возможных состояний алгоритмы часто «застревают» в локальных минимумах, не достигая глобально оптимальных решений. Новый протокол решает эту задачу путём регулирования оптимизационных ландшафтов с помощью специальных каналов шума, которые вводятся целенаправленно. В отличие от случайных помех, этот контролируемый шум помогает преодолевать барьеры, связанные с мелкомасштабными флуктуациями функции потерь, что делает процесс обучения более устойчивым. Традиционно шум в квантовых системах — это главный источник ошибок, вызванных взаимодействием с окружающей средой, такими как температурные колебания или электромагнитные поля. Однако учёные МИСИС продемонстрировали, что введение определённого количества шума в выбранные элементы квантовой схемы может сглаживать эти флуктуации и улучшать качество решений. Протокол протестирован на простых оптимизационных задачах и в квантовой свёрточной нейросети: в обоих случаях вероятность нахождения правильного решения выросла в несколько раз по сравнению с классическими методами, о чём исследователи рассказали в журнале Physical Review A (Q1). 
Источник изображения: НИТУ МИСИС «Когда мы тренируем модель, будь то классическая нейросеть или квантовый алгоритм, у неё есть функция потерь. Это мера того, насколько её подход к решению задачи неверный: чем выше потери, тем хуже. Параметров модели может быть много, например, вращения, фазы, вес и т. п. Каждая комбинация этих параметров даёт свой результат и функция потерь присваивает этому результату число — “высоту”. Представьте: вы стоите на горе и пытаетесь спуститься к самой низкой точке. Высота указывает, как далеко вы от цели. На пути встречается множество мелких ям и впадин и в них можно легко застрять, так и не добравшись до цели. Обычно так и происходит — мы блуждаем и попадаем в локальные ловушки. Наш метод похож на то, как если бы ямы засыпали песком. Он заполняет мелкие впадины, выравнивая поверхность, и путь становится проще: мы больше не задерживаемся и можем двигаться дальше. Таким образом, добавление шума — регуляризация — сглаживает ландшафт и значительно упрощает поиск оптимального решения», — отметил к.ф.-м.н. Никита Немков, старший научный сотрудник лаборатории квантовых информационных технологий НИТУ МИСИС. Предложенный протокол легко интегрируется с существующими методами, такими как квантовый оптимизатор естественного градиента, и не требует значительных дополнительных ресурсов. Он применим как в симуляторах на классических компьютерах, так и на реальных квантовых устройствах, открывая путь к более надёжным системам квантового ИИ. Учёные укротили свет в алмазах для прорыва в квантовых технологиях
23.09.2025 [11:31],
Геннадий Детинич
Учёные добились значительного прорыва в разработке методики улавливания фотонов от дефектов в алмазах. Представленный метод регистрирует подавляющее большинство фотонов, испускаемых алмазными NV-центрами, причём при комнатной температуре, что открывает путь к новому поколению квантовых датчиков и средствам абсолютно безопасной квантовой связи. 
Источник изображения: ИИ-генерация Grok 3/3DNews Разработку представили учёные из Еврейского университета в Иерусалиме (Hebrew University of Jerusalem) в сотрудничестве с Университетом Гумбольдта (Humboldt University) в Берлине. Они работали с так называемыми NV-центрами (центрами «азот–вакансия»). Это дефекты в кристаллической решётке алмаза, которые могут играть роль кубитов или квантовых датчиков. Эти центры легко приводятся в состояние суперпозиции и демонстрируют эффект запутанности под воздействием либо света, либо микроволнового излучения. Тем самым NV-центры могут использоваться как для квантовых вычислений, так и для сверхчувствительных датчиков. При воздействии на такие дефекты в алмазах обычно значительная часть света рассеивалась, что снижало эффективность систем. Новый подход, описанный в журнале APL Quantum, использует гибридные наноантенны в форме мишени для тира (bullseye), состоящие из слоёв металла и диэлектриков, в которые встраиваются наноалмазы с NV-центрами. Это позволяет направлять до 80 % фотонов в нужном направлении при комнатной температуре, что в разы превосходит предыдущие методы. Техническая суть инновации заключается в интеграции NV-центров в чипы с одновременным усилением и фокусировкой излучения. Наноантенны действуют как оптические линзы на наноуровне, минимизируя потери света и повышая яркость сигнала. Исследователи протестировали лабораторную систему, подтвердив её работоспособность в простых чипах. Такой дизайн не требует криогенного охлаждения, что упрощает производство и интеграцию с существующими электронными системами, делая квантовые технологии более доступными для массового применения. Потенциальные области применения новой технологии обширны. В квантовой связи она позволит создавать безопасные каналы передачи данных с использованием запутанных фотонов. Сверхчувствительные сенсоры на основе NV-центров найдут применение в медицине для визуализации на клеточном уровне, в навигации для точного позиционирования без GPS и в материаловедении для анализа свойств веществ. Кроме того, это ускорит развитие квантовых компьютеров, делая их компактнее (буквально на чипах) и быстрее, с возможностью масштабирования. Профессор Кармиэль Рапапорт (Carmiel Rapaport) из Еврейского университета подчеркнул: «Это приближает нас к практическим квантовым устройствам». Доктор Йонатан Любецки (Yonatan Lubotzky) добавил, что его впечатляет простота ориентированного на чипы дизайна и работа при комнатной температуре, что облегчает интеграцию в реальные системы. Это открытие не только продвигает фундаментальную науку, но и открывает коммерческие перспективы, потенциально привнося революцию в отрасли, зависящие от квантовых разработок. Квантовые компьютеры ещё не готовы, но в ПО для них уже инвестируют миллионы
02.09.2025 [18:54],
Владимир Мироненко
В течение десятилетий усилия разработчиков в сфере квантовых вычислений в основном были направлены на создание аппаратного обеспечения. После того как в этом наметился определённый прогресс, внимание отрасли переключилось на программное обеспечение, которое требуется для функционирования таких систем, пишет ресурс The Financial Times. 
Источник изображения: Mohammad Rahmani/unsplash.com Британская компания Phasecraft, занимающаяся квантовыми алгоритмами, сообщила, что привлекла $34 млн от инвесторов, в числе которых инвестиционная компания, связанная с датской фармацевтической компанией Novo Nordisk. Хотя эта сумма и невелика, инвестиции свидетельствуют о том, что специализированные компании, разрабатывающие квантовое программное обеспечение, начали привлекать всё больше внимания инвесторов, отметил The Financial Times. «В какой-то момент людям интересны только приложения, — говорит Боб Сьютор (Bob Sutor), бывший ведущий эксперт IBM по квантовым технологиям. — В истории вычислительной техники программное обеспечение всегда становится более доминирующим и приоритетным». Как отметил ресурс, растущий интерес к алгоритмам отражает стремление компаний использовать квантовые компьютеры для более широкого круга задач, а также повысить их эффективность. По словам Стива Брирли (Steve Brierley), гендиректора британской компании Riverlane в сфере квантовых вычислений, усовершенствование квантовых алгоритмов за последние десять лет привело к «экспоненциальному снижению» объёма вычислительной мощности, необходимой для их запуска. Квантовое оборудование пока не достигло уровня для их использования, но, как заявил Питер Барретт (Peter Barrett), партнёр венчурной компании Playground Global, «мы находимся на пороге этого». В связи с успехами в разработке ПО, появились заявления о том, что отрасль близка к достижению квантового преимущества — точки, когда квантовые машины смогут выполнять полезные задачи, которые практически невозможно выполнить на традиционных, или «классических», компьютерах. Эшли Монтанаро (Ashley Montanaro), гендиректор Phasecraft, утверждает, что разработанные его компанией алгоритмы смогут выполнять «научно важные» вычисления «к весне следующего года», а некоторые коммерчески полезные приложения могут быть разработаны «в течение ближайших нескольких лет». Вместе с тем он предупредил, что краткосрочные результаты будут относительно незначительными, отметив, что отрасль уже пережила «своего рода пик квантовой спекуляции». В США разработали квантовую память на звуковых волнах — она в 30 раз превосходит электронную
22.08.2025 [10:39],
Геннадий Детинич
Больное место квантовых платформ — это запоминание квантовых состояний. Без памяти невозможно передавать данные на большие расстояния, а также выполнять сложные расчёты. А всё потому, что квантовые состояния — это математические функции с множеством переменных. Поэтому запоминать приходится не значения, а уравнения в динамике. Но и к этому можно найти подход. 
Источник изображения: ИИ-генерация Grok 3/3DNews По большому счёту, для математики не имеет значения, на какую основу «натягивать» уравнения. Классические сверхпроводящие кубиты оперируют квантовыми состояниями электронов и, следовательно, электромагнитными полями и соответствующими колебаниями (частотами). Но там настолько высокие частоты, что они удерживают состояния лишь очень короткий промежуток времени. А если взять звуковые колебания? Их частоты ведь намного ниже. Это означает, что квантовые состояния смогут продержаться дольше, если их представить в звуковых волнах. Чем не память — пусть время удержания квантовой информации будет куда короче, чем у той же DRAM. Но для квантовых вычислений или квантового интернета это уже колоссальное достижение. Команда Калифорнийского технологического института (Caltech) разработала гибридный подход, использующий звук для хранения квантовой информации. В проведённом эксперименте сверхпроводящий кубит был интегрирован с механическим генератором — миниатюрным устройством, напоминающим камертон, которое преобразует электрические сигналы в акустические волны с частотой в гигагерцовом диапазоне. Выяснилось, что эти волны, или фононы, позволяют сохранять квантовые состояния в 30 раз дольше, чем лучшие сверхпроводящие кубиты. 
Квантовое запоминающее устройство под микроскопом. Источник изображения: Caltech Механический генератор состоит из гибких пластин, которые вибрируют под воздействием звуковых волн и при этом взаимодействуют с электрическими сигналами, несущими квантовую информацию от расположенных рядом кубитов. Это позволяет записывать квантовые состояния в устройство и извлекать их обратно, что аналогично работе квантовой памяти. Преимущество подхода заключается в относительно медленном распространении акустических волн по сравнению с электромагнитными, что делает устройства компактными и минимизирует потери энергии. Кроме того, механические колебания не распространяются в свободном пространстве, что снижает нежелательное взаимодействие между соседними устройствами и увеличивает время хранения информации. Несмотря на успех, команда отмечает, что для полноценного применения разработки в квантовых вычислениях необходимо увеличить скорость взаимодействия между кубитами и генератором в 3–10 раз. Исследователи уже работают над улучшением системы, чтобы повысить её эффективность. Этот подход открывает перспективы для создания масштабируемых квантовых запоминающих устройств с интеграцией множества механических генераторов на одном чипе, что может стать важным шагом в развитии квантовых технологий. ИИ помог китайцам создать крупнейшие массивы атомов для квантовых компьютеров будущего
14.08.2025 [13:03],
Геннадий Детинич
Китайские ученые сообщили о значительном прорыве в области квантовых вычислений, создав крупнейшие в мире массивы из 2024 атомов рубидия. О работе, опубликованной в журнале Physical Review Letters, рецензенты уже заявили, что это важный шаг в развитии квантовой физики, связанной с атомами. Новая платформа использует искусственный интеллект и оптические пинцеты, благодаря чему способна формировать массивы атомов в 10 раз больше предыдущих. 
Кошка Шрёдингера, нарисованная с помощью 550 атомов рубидия. Источник изображения: University of Science and Technology of China Каждый атом в таком массиве играет роль кубита — базовой единицы квантовых вычислений. Исследование стало продолжением работы группы физиков из Университета науки и технологий Китая (University of Science and Technology of China). В отличие от других подходов к созданию квантовых компьютеров, таких как использование сверхпроводящих цепей или ионов, нейтральные ультрахолодные атомы при масштабировании обладают большей стабильностью и управляемостью. Однако до сих пор системы на основе атомов были ограничены массивами из нескольких сотен элементов из-за медленного процесса их позиционирования, когда каждый атом индивидуально перемещается оптическим пинцетом в виде лазера. Университетская команда совместно с учёными Шанхайской лаборатории искусственного интеллекта разработала систему на базе ИИ, которая с помощью высокоскоростного пространственного модулятора света одновременно перемещает атомы в нужное место. Это позволило создать идеальный массив из 2024 атомов всего за 60 мс, причём время перестановки не зависело от размера массива, что открывает путь к дальнейшему масштабированию числа кубитов. В условиях лаборатории система продемонстрировала впечатляющую точность: операции с одним кубитом выполнялись с точностью 99,97 %, а с двумя кубитами — 99,5 %. Точность определения состояния кубитов достигла 99,92 %, что сопоставимо с результатами, полученными в ведущих мировых институтах. Однако текущая версия системы имеет ограничения: в 3D-моделях атомы можно перемещать только в пределах одного слоя, а размер массива ограничен мощностью и точностью используемых лазеров. Тем самым полученные результаты подчёркивают потенциал технологии, но требуют дальнейших улучшений для создания масштабируемых квантовых компьютеров. Для дальнейшего прогресса учёные планируют разработать более мощные лазеры и высокоточные модуляторы света. Способность идеально упорядочивать десятки тысяч атомов в предсказуемые матрицы может стать основой для создания надёжных квантовых компьютеров в будущем. Этот прорыв подтверждает лидерство Китая в области квантовых технологий и открывает новые горизонты для исследований, направленных на преодоление текущих ограничений и достижение практической реализации квантовых вычислений. Nvidia представила крошечные видеокарты RTX Pro 4000 SFF и RTX Pro 2000 для профессионалов
11.08.2025 [19:35],
Николай Хижняк
Nvidia расширила ассортимент профессиональных видеокарт поколения Blackwell, представив модели RTX Pro 4000 SFF и RTX Pro 2000 на конференции SIGGRAPH 2025. Эти видеокарты дополняют линейку решений Nvidia для рабочих станций. Помимо повышенной производительности по сравнению с моделями предыдущего поколения, новинки также оптимизированы для ускорения задач ИИ, что делает их актуальными для различных рабочих процессов в самых разных отраслях. 
Источник изображений: Nvidia Модель RTX Pro 4000 Blackwell SFF — это уменьшенная версия уже доступной видеокарты RTX 4000 Blackwell. Компания утверждает, что новинка обеспечивает более чем двукратный прирост производительности в задачах ИИ по сравнению с RTX A4000 SFF предыдущего поколения, предлагая при этом улучшенные возможности трассировки лучей и на 50 % увеличенную пропускную способность. При этом уровень энергопотребления остался на прежнем уровне — 70 Вт. Благодаря 24 Гбайт памяти ECC GDDR7 и заявленной производительности 770 TOPS в задачах ИИ, эта видеокарта может стать отличным выбором для профессионалов, которым требуется высокая вычислительная мощность в составе компактной рабочей станции.  Новая модель RTX Pro 2000 оснащена 16 Гбайт памяти ECC GDDR7 и предлагает производительность до 545 TOPS в задачах ИИ при том же уровне энергопотребления — 70 Вт. По заявлению Nvidia, карта разработана для массового дизайна и рабочих процессов с применением искусственного интеллекта. Новинка примерно в 1,5 раза быстрее модели Nvidia RTX A2000 в задачах 3D-моделирования, автоматизированного проектирования и рендеринга. Кроме того, она обеспечивает более высокую эффективность при генерации изображений и текста с помощью ИИ. Точные характеристики и стоимость моделей RTX Pro 4000 SFF и RTX Pro 2000 в рамках презентации Nvidia не раскрыла. Ожидается, что видеокарты поступят в продажу в конце текущего года. RTX Pro 2000 будет доступна у компаний PNY и TD Synnex как отдельное решение, а также появится у системных интеграторов Boxx, Dell, HP и Lenovo в составе готовых рабочих станций. RTX Pro 4000 SFF будет предлагаться в системах от партнёров Nvidia, включая Dell, HP и Lenovo. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






