
Опрос
|
реклама
Быстрый переход
Google выпустила ИИ-модель Lyria 3 Pro для генерации трёхминутных музыкальных треков — но не бесплатно
25.03.2026 [21:32],
Николай Хижняк
Google сообщила о выпуске ИИ-модели Lyria 3 Pro для генерации музыки. В прошлом месяце компания представила модель Lyria 3 с той же функцией. Версия Pro позволит создавать треки продолжительностью до трех минут, в отличие от 30-секундных треков, предлагаемых в модели Lyria 3. 
Источник изображения: Google Помимо возможности создания более длинных треков модель Lyria 3 Pro предложит лучший творческий контроль и возможности настройки, заявляет Google. В запросе для модели пользователи могут указывать различные элементы музыкального произведения, такие как вступления, куплеты, припевы и бриджи — Lyria 3 Pro лучше понимает структуру трека, чем её предшественница. Ранее Google добавила возможность генерации музыки с помощью Lyria 3 в приложении Gemini. Модель Pro тоже доступна через Gemini, но доступ к ней получат только платные подписчики. Модель Lyria 3 Pro также добавлена в приложение для редактирования видео Google Vids и в состав ProducerAI, инструмента для создания музыки на основе искусственного интеллекта, который Google приобрела в прошлом месяце. Кроме того, Google добавляет возможность генерации музыки через Lyria 3 Pro в свои корпоративные инструменты с помощью Vertex AI (в публичной предварительной версии), API Gemini и AI Studio. Компания сообщила, что для обучения Lyria 3 Pro использовались данные от партнёров, а также разрешённые данные от YouTube. По словам Google, модель не имитирует конкретных исполнителей. Однако если пользователи указывают исполнителя в подсказках, модель использует «широкое вдохновение» от этого исполнителя для создания трека. Все треки, созданные с помощью Lyria 3 и Lyria 3 Pro, помечаются маркером SynthID, указывающим, что для создания этой композиции использовался ИИ. Марк Цукерберг создаёт ИИ-гендира: агента, который поможет ему руководить Meta✴
23.03.2026 [12:19],
Алексей Разин
Основателя Facebook✴✴ Марка Цукерберга (Mark Zuckerberg) можно назвать увлекающимся человеком, поскольку интересующие его области информационных технологий нередко удостаиваются серьёзных капиталовложений со стороны Meta✴✴ Platforms. Искусственный интеллект Цукерберг готов поставить на службу не только людям, но и себе лично, создавая агента для руководства своей корпорацией. 
Источник изображения: Марк Цукерберг Последняя, как напоминает The Wall Street Journal, насчитывает 78 000 сотрудников и развивается в стремительно меняющихся условиях, поэтому излишняя централизация функций в управлении бизнесом вредна для него. По имеющимся данным, Цукерберг готов создать ИИ-агента, который будет помогать ему в управлении бизнесом. Иерархия любой крупной корпорации подразумевает многоуровневую структуру управления, поэтому получить информацию от линейных специалистов руководству в сжатые сроки порой сложно. Цукерберг в настоящее время работает над тем, чтобы получать такую информацию от подчинённых в ускоренном режиме, и для этих целей создаёт персонального ИИ-агента. Глава Meta✴✴ Platforms убеждён, что генеративный ИИ поможет корпорации сохранить живость и гибкость, характерную для стартапов с небольшим штатным расписанием. В условиях постоянной конкуренции с ними такое качество весьма важно для бизнеса. В компании ИИ активно внедряется в последнее время, способность использовать его в повседневной деятельности стала важным критерием оценки эффективности многих сотрудников. «Мы вкладываем в создание инструментов с врождённой поддержкой ИИ, чтобы отдельные сотрудники могли в Meta✴✴ успевать больше. Мы выделяем вклад отдельных людей и усредняем команды. Если мы делаем это, то я думаю, что мы сможем успевать гораздо больше, и это будет гораздо веселее», — охарактеризовал подобные попытки сам Цукерберг на отчётной квартальной конференции Meta✴✴. Внутренние информационные ресурсы Meta✴✴, по данным источников, наполнены сообщениями сотрудников, которые либо предлагают новые способы использования искусственного интеллекта, либо уже создали профильные инструменты и опробовали их в деле. Некоторые «старожилы» сравнивают атмосферу, которая сейчас царит в Meta✴✴, с ранним периодом работы Facebook✴✴, когда компания руководствовалась принципом «двигайся быстро и ломай вещи». Позже под влиянием Цукерберга девиз трансформировался в «двигайся быстро со стабильной инфраструктурой». Сотрудники Meta✴✴ активно создают с помощью My Claw ИИ-агентов, которые имеют доступ к их рабочим документам и переписке. Порой от лица двух разных сотрудников друг с другом общаются именно ИИ-агенты, а не они сами. Получает распространение и инструмент по имени Second Brain, который сочетает элементы чат-бота и агента. Он основан на разработках Anthropic, помимо прочего, позволяя анализировать массивы документов и использовать обращения к ним при обработке запросов. Такие ИИ-агенты, по мнению их создателей, уже могут координировать работу подчинённых и созданных ими других агентов. Разработки купленного ранее Meta✴✴ сингапурского стартапа Manus также используются внутри компании. Отдельная группа специалистов Meta✴✴ работает над использованием ИИ для разработки новых больших языковых моделей. Она характеризуется наличием примерно 50 сотрудников, которые подчиняются одному руководителю и очень быстро с ним взаимодействуют. При создании группы изначально закладывалась возможность активного использования ИИ в её деятельности. Сотрудники Meta✴✴ в целом несколько раз в неделю принимают участие в обучающих семинарах по использованию ИИ, различных конкурсах по его применению, а создание собственных ИИ-инструментов всячески поощряется руководством. Кому-то из сотрудников высокие темпы внедрения ИИ нравятся, но некоторые обеспокоены риском новых сокращений штата. В ковидные годы Meta✴✴ нарастила численность персонала до 87 314 сотрудников, но к концу 2023 года их количество сократилось до примерно 67 000 человек. Позже на волне развития направления ИИ штат компании вернулся к росту, последние данные статистики говорят о наличии у компании 78 865 сотрудников. Финансовый директор Сьюзан Ли (Susan Li) заявила, что динамика изменения численности штата отображает озабоченность руководства компании её способностью работать столь же эффективно, как и компании, которые изначально занимались ИИ. Пентагон принял боевую ИИ-систему Palantir Maven в качестве основной для армии США
21.03.2026 [12:18],
Алексей Разин
Скандал с исключением Anthropic из числа благонадёжных поставщиков ИИ-решений с точки зрения Пентагона привлёк внимание общественности к деятельности американского военного ведомства по интеграции технологий искусственного интеллекта в свои операции. Новая памятка, полученная сотрудниками этого ведомства, гласит о выборе системы Maven компании Palantir в качестве основной для Пентагона. 
Источник изображения: Palantir При этом сама по себе ИИ-система Maven не является новой для Министерства войны США, просто теперь она будет использоваться в качестве базовой для построения всех прочих решений в сфере искусственного интеллекта, связанных с ведением боевых действий и разведывательной деятельностью. В своём письме сотрудникам Пентагона от 9 марта заместитель министра обороны США Стив Файнберг (Steve Feinberg) подтвердил выбор Maven в качестве основной ИИ-системы в инфраструктуре военного ведомства США. На документальном уровне данный выбор будет окончательно закреплён к сентябрю текущего года, когда завершится очередной фискальный год. Maven является ИИ-системой для боевого применения, которая позволяет обнаруживать цели на поле боя путём анализа поступающей разведывательной информации сразу по нескольким каналам. Только за время текущей операции США в Иране данная система позволила выбрать цели и нанести тысячи ударов по ним. Утверждение Maven в качестве главной системы такого типа позволит американским военным стандартизировать её применение во всех подразделениях и обеспечит Palantir долгосрочными оборонными контрактами. До сих пор эти контракты курировало Национальное агентство геопространственной разведки США, но в результате принятых решений они перейдут под контроль верховного командования американской армии. Только один контракт Palantir с американскими военными прошлым летом принёс компании $10 млрд, а в целом их было заключено несколько штук. Капитализация этого оборонного подрядчика оценивается в $360 млрд. Система Maven обучена в автоматическом режиме обнаруживать цели на поле боя, идентифицировать возможные укрытия и склады боеприпасов и горючего. На решение соответствующих задач привычными методами ранее уходили часы. Palantir подчёркивает, что конечное решение о применении оружия делает человек, а система Maven только определяет цели. Разработка системы ведётся с 2017 года, первый контракт с Пентагоном был заключён компанией Palantir в 2024 году, принеся ей $480 млн. В мае прошлого года потолок финансирования был увеличен до $1,3 млрд. Примечательно, что сама Palantir использует для работы своих систем ИИ-решения Anthropic, от которых теперь придётся избавляться, если соответствующий запрет не будет снят. Xiaomi в ближайшие три года вложит в развитие ИИ не менее $8,7 млрд
20.03.2026 [12:44],
Алексей Разин
Выход Xiaomi на рынок электромобилей можно признать достаточно успешным, поскольку в течение первых двух лет своего присутствия на нём она умудрилась попасть в десятку крупнейших игроков. Глава компании Лэй Цзюнь (Lei Jun) заявил, что в ближайшие три года она вложит в сферу ИИ не менее $8,7 млрд, тем самым обозначив новый приоритет для развития. 
Источник изображения: Xiaomi Эти слова, на которые ссылается Reuters, прозвучали на второй день после выхода ИИ-модели MiMo-V2-Pro, в причастности к которому многие источники подозревали компанию DeepSeek. Новинка была по достоинству оценена общественностью, что и позволило руководителю Xiaomi сделать соответствующее заявление. По словам Цзюня, модель MiMo-V2-Pro пользуется успехом во всём мире, она будет стремительно улучшаться, а бюджет Xiaomi на исследования и разработки в сфере ИИ заметно превысит первоначально намеченную сумму в $2,3 млрд. Как прояснил Лэй Цзюнь, модель MiMo-V2-Pro была создана для работы с агентскими нагрузками. Успех решений типа OpenClaw воодушевил присоединиться к тренду даже китайских гигантов в лице Alibaba и Tencent, которые надеются найти новые источники стабильной выручки. Разработчики, как отмечает Цзюнь, хвалят ИИ-модель Xiaomi как за скорость, так и за точность. Этим и объясняется глобальный успех MiMo-V2-Pro, по мнению основателя Xiaomi. Он также отметил, что средний возраст разработчиков этой ИИ-модели составляет 25 лет, при этом большинство из них закончили один из двух ведущих китайских университетов, а более половины членов команды имеют докторские учёные степени. Возглавляет команду специалистов бывшая сотрудница DeepSeek Ло Фули (Luo Fuli), родившаяся в 1995 году. ИИ по-русски: Минцифры РФ предложило правила регулирования нейросетей
19.03.2026 [13:00],
Владимир Мироненко
Минцифры РФ подготовило законопроект о регулировании искусственного интеллекта, который вводит понятия суверенной, национальной и доверенной моделей ИИ. Документ опубликован для обсуждения и может вступить в силу 1 сентября 2027 года. 
Источник изображения: BoliviaInteligente/unsplash.com Согласно законопроекту, разработкой, обучением и эксплуатацией суверенной и национальной моделей смогут заниматься только граждане России и российские юрлица. При этом обучение этих моделей будет производиться с использованием наборов данных, сформированных россиянами и российскими юрлицами на территории страны. Суверенные и национальные модели могут также относиться к категории доверенных моделей, у которых должно быть подтверждение соответствия требованиям безопасности и соответствия требованиям качества, установленным Банком России, федеральными органами исполнительной власти и госкорпорациями. Обработка данных доверенной модели должна осуществляться только на территории Российской Федерации. Согласно документу, нейросети из реестра доверенных моделей можно будет использовать в государственных информационных системах и на объектах критической инфраструктуры. В аппарате вице-премьера Дмитрия Григоренко сообщили Forbes, что законопроектом определены отдельные требования применения ИИ для конкретных сфер, например, госуправления, и коммерческого сектора это не коснётся. В документе указано, что изменения не будут распространяться на использование ИИ в ситуациях, связанных с обороной, госбезопасностью, чрезвычайными ситуациями и правопорядком, если иное не предусмотрено другими федеральными законами. Также документом определено, что одним из принципов регулирования в сфере ИИ является уважение традиционных российских духовно-нравственных ценностей. Разработчики, операторы и владельцы нейросетей будут нести ответственность за результат работы ИИ в случае нарушения закона, если они знали заранее о возможности такого исхода. Согласно законопроекту, международное сотрудничество в этой сфере будет возможно путём совместных научных исследований и обмена данными с другими странами. Также документом предусмотрено стимулирование со стороны правительства разработок в этой сфере путём приоритетного подключения ЦОД к электросетям, пониженных тарифов на электроэнергию, налоговых льгот и бюджетного финансирования. ByteDance отложила глобальный запуск ИИ-генератора видео Seedance 2.0 из-за проблем с авторскими правами
15.03.2026 [07:44],
Алексей Разин
Соблазн использования уже знакомых образов и сюжетов при генерации видео с помощью искусственного интеллекта весьма высок, поскольку это упрощает задачу создателю и одновременно позволяет гарантировать интерес аудитории к конечному результату. ByteDance решила отложить глобальный запуск генератора видео Seedance 2.0 из-за проблем с авторскими правами. 
Источник изображения: ByteDance Как отмечает Reuters со ссылкой на The Information, соответствующие трудности возникли у китайской компании в сфере взаимоотношений с крупными голливудскими студиями и стриминговыми платформами. Ещё в прошлом месяце ByteDance была вынуждена заявить, что предпримет меры для предотвращения неправомерного использования интеллектуальной собственности в работе ИИ-генератора видео Seedance 2.0 после того, как некоторые американские студии типа Disney пригрозили ей судебным преследованием. По версии Disney, компания ByteDance использовала персонажей, чьи образы принадлежат студии, для обучения Seedance 2.0 без соответствующего разрешения. Поводом для претензий стало распространение в китайских социальных сетях вирусного видео, на котором сгенерированные ИИ двойники Тома Круза (Tom Cruise) и Брэда Питта (Brad Pitt) участвуют в поединке. Как считает Disney, при обучении Seedance 2.0 китайская ByteDance использовала полученные незаконным способом образы персонажей из популярных кинофраншиз, включая Star Wars и Marvel, обращаясь с ними, как с общедоступными материалами. Представившая ИИ-генератор Seedance 2.0 на китайском рынке в феврале ByteDance отмечала, что он предназначен для профессионального использования при производстве фильмов и рекламных роликов. Способность данного продукта одновременно обрабатывать текст, изображения, видео и аудио, по словам представителей компании, позволяет снизить затраты на изготовление контента. Первоначально ByteDance намеревалась открыть доступ к Seedance 2.0 клиентам за пределами Китая в середине марта, но из-за потенциальных проблем с авторскими правами решила задержать график. Как отмечается, сейчас технические специалисты работают над внедрением защитных механизмов от использования охраняемых авторским правом персонажей, а юристы дополнительно прорабатывают правовые основы использования ИИ-модели. Nvidia выпустила Nemotron 3 Super 120B — открытую LLM для ИИ-агентов с пятикратным приростом скорости
11.03.2026 [21:48],
Николай Хижняк
Компания Nvidia выпустила Nemotron 3 Super — открытую ИИ-модель Mixture-of-Experts (MoE) с поддержкой 120 млрд общих параметров и 12 млрд активных параметров, предназначенную для задач агентного ИИ. Модель использует гибридную архитектуру Mamba-Transformer. 
Источник изображений: Nvidia По словам Nvidia, Nemotron 3 Super — это первая модель в серии Nemotron 3, которая объединяет парадигму LatentMoE, слои Multi-Token Prediction и предварительное обучение NVFP4. Компания заявляет, что этот стек повышает точность и ускоряет инференс, а гибридная архитектура Nemotron 3 Super обеспечивает до пяти раз более высокую пропускную способность и до двух раз более высокую точность по сравнению с предыдущей моделью Nemotron Super. Компания также отмечает поддержку контекстного окна в 1 млн токенов, что позволяет агентным ИИ сохранять в памяти полное состояние рабочего процесса и предотвращает отклонение от цели. 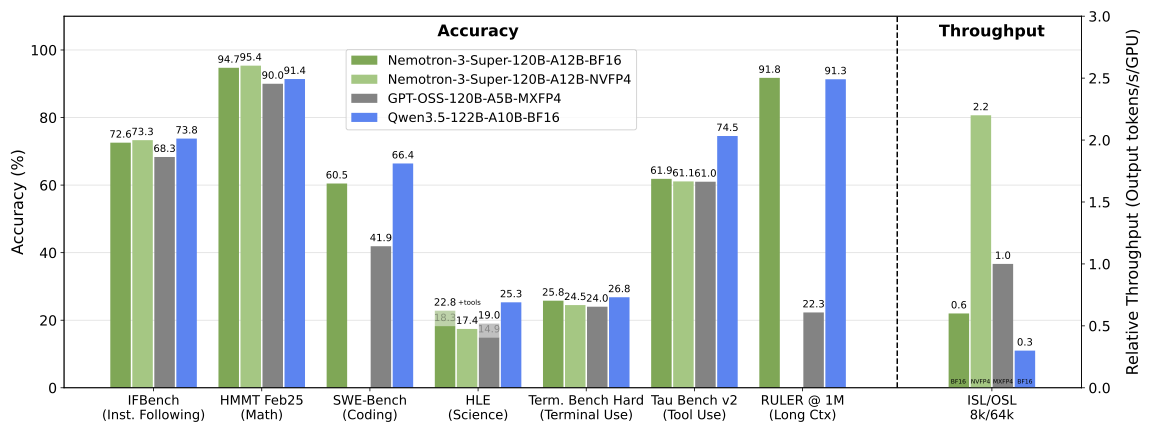 Nemotron 3 Super подходит для решения сложных задач внутри многоагентной системы. Например, для генерации и отладки кода без сегментации документов, для финансового анализа, где можно загружать в память тысячи страниц отчётов. 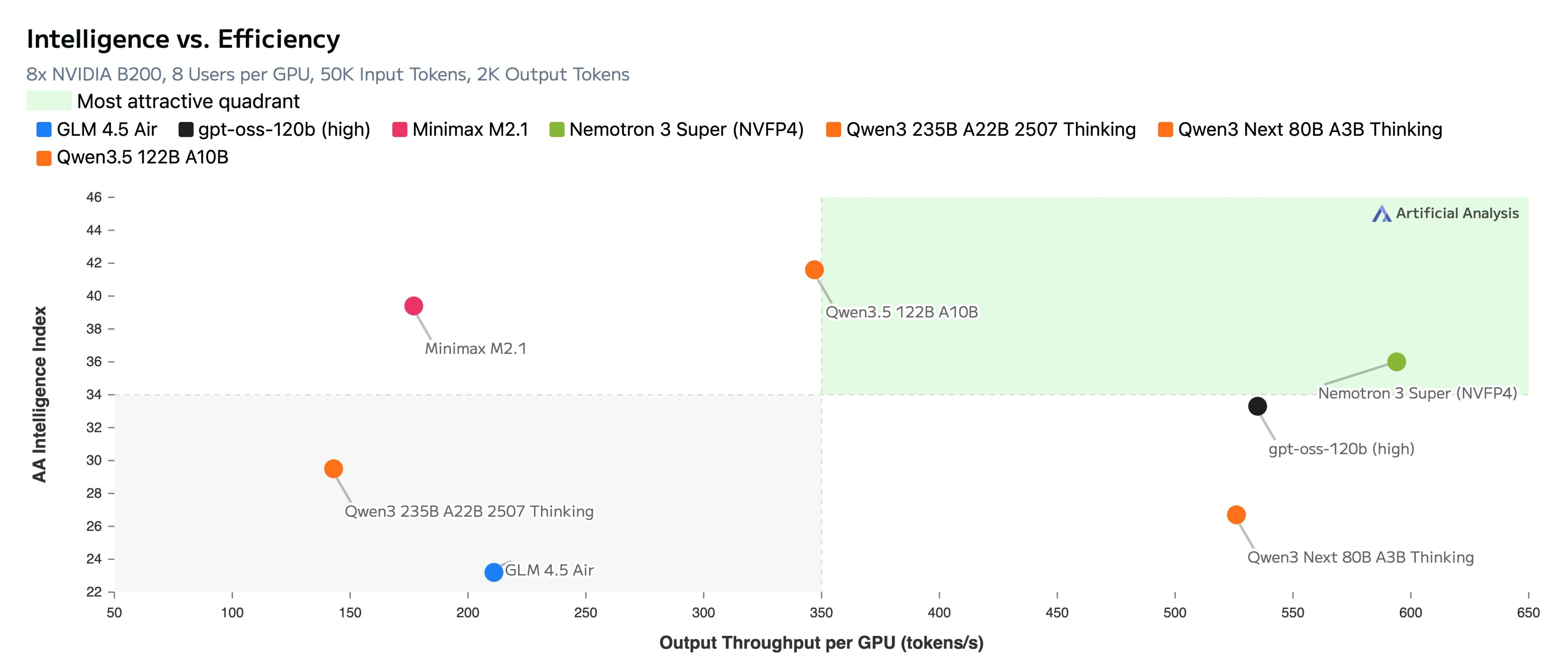 Модель была обучена на синтетических данных, сгенерированных с использованием моделей логического мышления. Nvidia публикует полную методологию, включая более 10 триллионов токенов наборов данных до и после обучения, 15 сред обучения для обучения с подкреплением и рецепты оценки. Исследователи могут дополнительно использовать платформу Nvidia NeMo для тонкой настройки модели или создания собственной. Nemotron 3 Super поддерживает работу на платформе Nvidia Blackwell в формате NVFP4. Это снижает требования к памяти и ускоряет вывод в четыре раза по сравнению с FP8 на Nvidia Hopper без потери точности. Модель уже доступна для использования. Доступ к Nemotron 3 Super можно получить через build.nvidia.com, Hugging Face, OpenRouter и Perplexity, а среди партнёров по облачным сервисам и инференсу указаны Google Cloud Vertex AI, Oracle Cloud Infrastructure, CoreWeave, Together AI, Baseten, Cloudflare, DeepInfra, Fireworks AI и Modal. Модель также представлена в виде микросервиса Nvidia NIM для развёртывания в локальной среде и облаке. Google представила Gemini 3.1 Flash-Lite — «самую быструю и экономически эффективную модель семейства»
04.03.2026 [00:01],
Владимир Фетисов
Компания Google объявила о запуске Gemini 3.1 Flash-Lite — быстрой и наиболее доступной с экономической точки зрения ИИ-модели семейства Gemini. Алгоритм оптимизирован для эффективной обработки больших объёмов данных, а стоимость его использования составляет $0,25 за 1 млн входных и $1,50 за 1 млн выходных токенов. Предварительная версия ИИ-модели уже доступна разработчикам через Gemini API в Google AI Studio, а для корпоративных клиентов — в Vertex AI. 
Источник изображений: Google Gemini 3.1 Flash-Lite превосходит модель Gemini 2.5 Flash по времени до генерации первого токена в 2,5 раза и на 45 % быстрее выводит данные ответов. При этом сохраняется аналогичный или более высокий уровень качества ответов. Такая низкая задержка необходима для повышения эффективности рабочих процессов, что делает новую модель привлекательной для разработчиков, создающих отзывчивые решения и приложения, работающие в режиме реального времени. 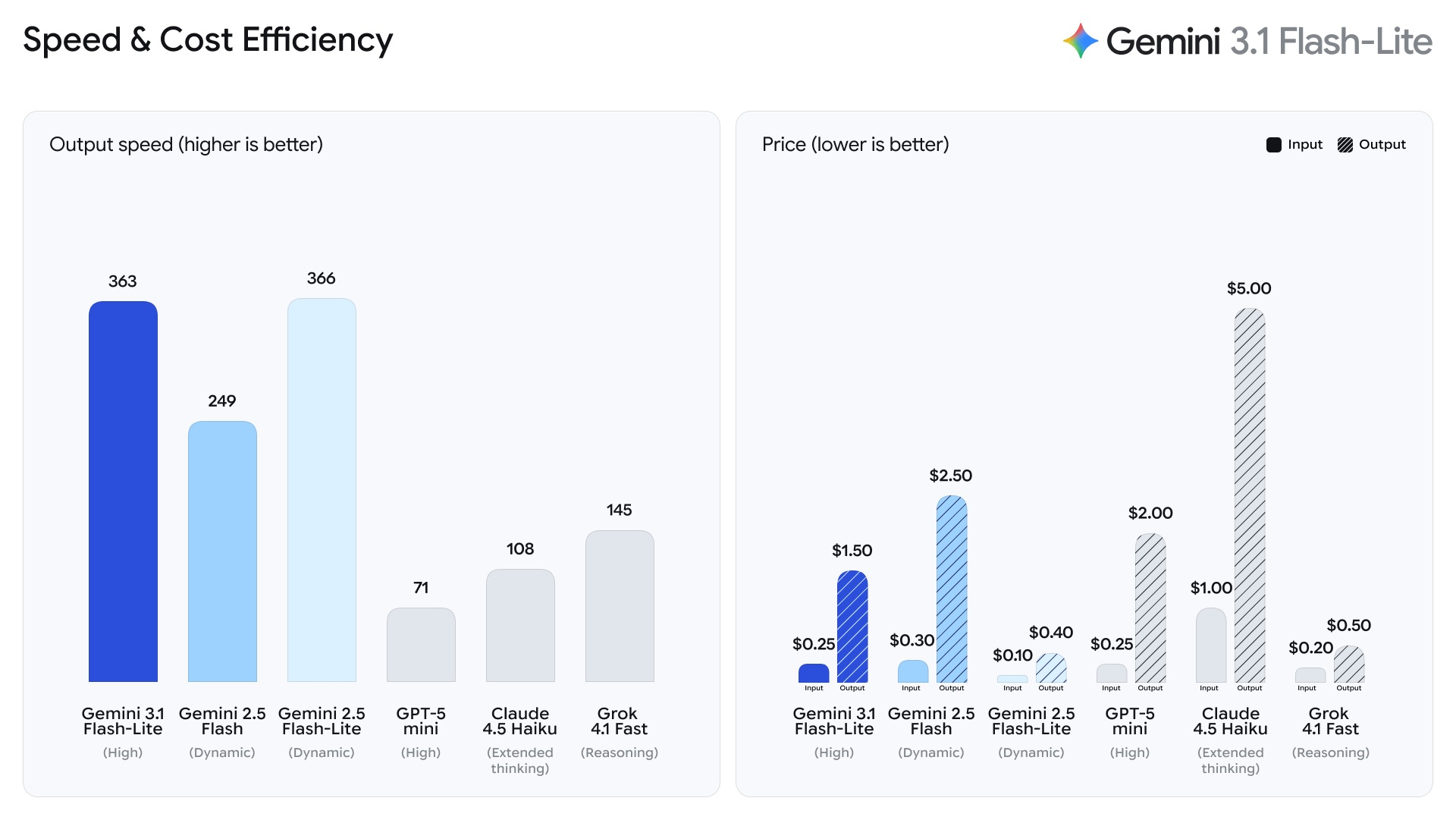 ИИ-модель достигла впечатляющего результата в рейтинге ELO в 1432 балла на Arena.ai и превзошла другие ИИ-модели аналогичного уровня по показателям рассуждения и мультимодальной обработки. В тестах GPQA Diamond и MMMU Pro алгоритм набрал 86,9 % и 76,8 % соответственно, превзойдя результаты некоторых более крупных ИИ-моделей Gemini предыдущих поколений, таких как Gemini 2.5 Flash. 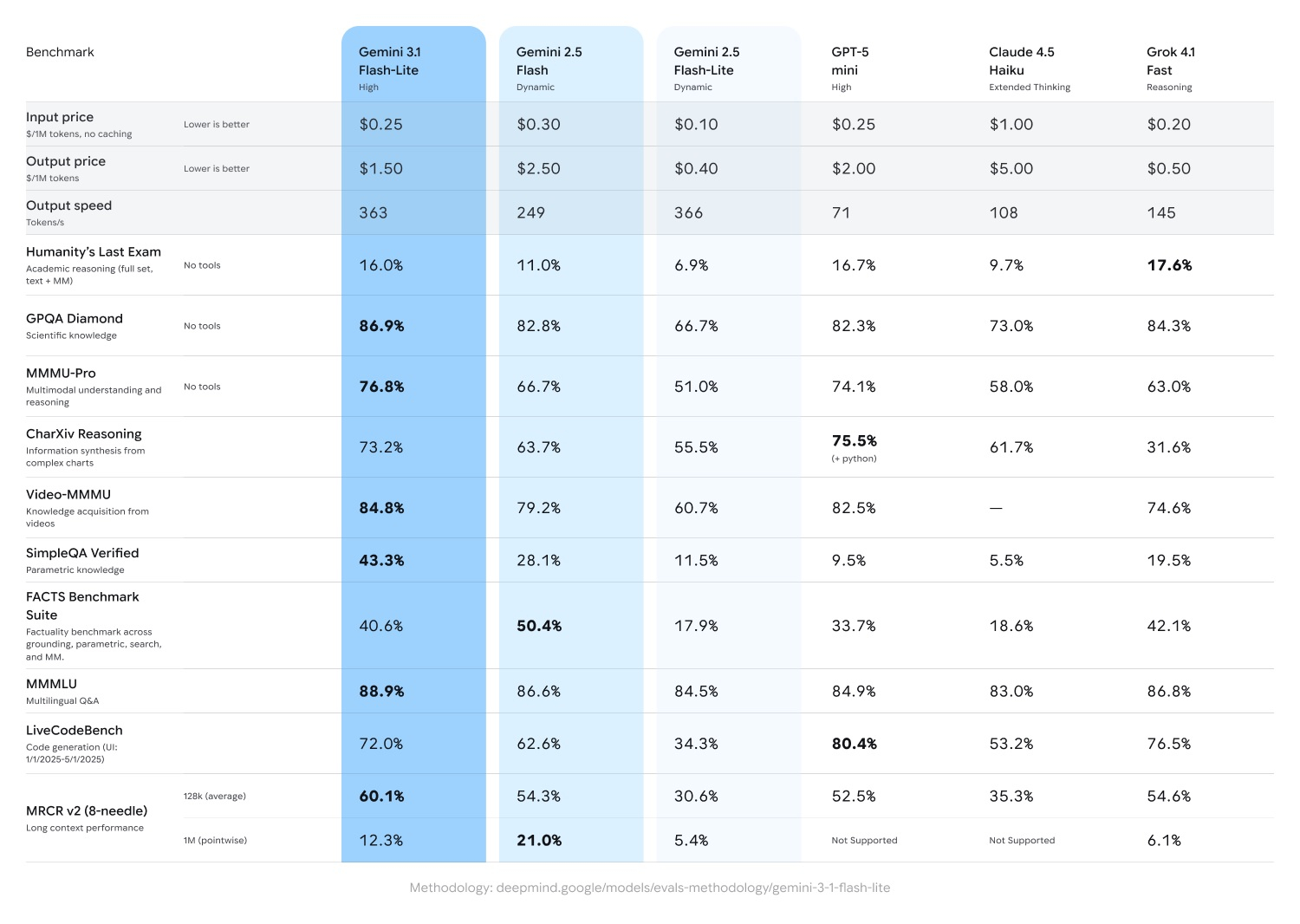 Разработчики имеют возможность регулирования глубины рассуждений Gemini 3.1 Flash-Lite в соответствии с собственными потребностями. Этот аспект является важным для управления высокочастотными рабочими нагрузками. Проведена оптимизация обработки масштабных задач, таких как перевод больших объёмов текста и модерация контента, где стоимость является одним из приоритетов. Алгоритм подходит для генерации пользовательских интерфейсов (UI), дашбодов, моделирования и проведения исследований на основе сложных запросов. Санкции не помеха: DeepSeek могла обучить ИИ на запрещённых Nvidia Blackwell
24.02.2026 [07:42],
Алексей Разин
Несмотря на некоторое смягчение политики экспортных ограничений США в отношении поставок в Китай ускорителей вычислений для систем ИИ, решения Nvidia семейства Blackwell остаются в этой стране под запретом. Это не помешало китайской DeepSeek, по данным некоторых источников, обучить свою новейшую ИИ-модель именно на этих ускорителях. 
Источник изображения: Nvidia На следующей неделе, как поясняет Reuters, китайская DeepSeek представит свою новейшую ИИ-модель, и у источника есть все основания полагать, что она была обучена с использованием санкционных ускорителей Nvidia Blackwell, которые эксплуатируются во Внутренней Монголии — регионе Китая, обладающем определённой автономией. Соответствующей информацией располагают американские чиновники, а это может стать поводом для определённых действий в отношении китайских разработчиков ИИ. Как последние получили доступ к ускорителям Blackwell в условиях санкций, источники не поясняют. В целом, американские политики разделились на два лагеря. Одни под воздействием основателя Nvidia Дженсена Хуанга (Jensen Huang) склонились к идее о необходимости сохранения зависимости Китая от поставок американских ускорителей вычислений, которые могут отставать от передовых на одно или два поколения. Другие считают, что предоставление Китаю доступа к таким инструментам сродни передаче ему ядерного оружия по доброй воле. Американские чиновники опасаются, что китайские ИИ-решения будут поставлены на службу оборонной отрасли КНР. Принято считать, что в августе прошлого года американский президент Дональд Трамп (Donald Trump) был близок к выдаче разрешения на поставку в Китай модифицированных ускорителей Blackwell, которые отставали бы от предлагаемых в США по уровню быстродействия. Вместо этого в декабре Трамп разрешил поставки в КНР ускорителей H200 с более старой архитектурой Hopper. Учитывая растущее количество жалоб американских разработчиков на хищение данных со стороны китайских конкурентов, американские власти могут ввести дополнительные ограничения в сфере ИИ на китайском направлении экспорта. Anthropic обвинила DeepSeek и ещё двух китайских конкурентов в 16 млн попыток дистилляции моделей Claude
24.02.2026 [07:04],
Алексей Разин
OpenAI в этом месяце уже предупреждала американских законодателей в применении китайской компанией DeepSeek метода дистилляции её ИИ-моделей для ускорения собственного прогресса. Теперь со схожими обвинениями выступила Anthropic, причём в адрес сразу трёх китайских конкурентов: DeepSeek, MiniMax Group и Moonshot. 
Источник изображения: Unsplash, Solen Feyissa По словам представителей Anthropic, на которые ссылается Bloomberg, три указанные китайские компании нарушили правила использования её моделей семейства Claude, осуществив не менее 16 млн сессий обмена данными с использованием тысяч поддельных учётных записей. Метод дистилляции в сфере обучения моделей позволяет разработчикам добиваться прогресса в сжатые сроки, совершенствуя свои системы на основе данных, получаемых от уже обученных сторонних моделей. Как отмечает Anthropic в своём блоге, действия китайских разработчиков в этой сфере становятся всё более активными и изощрёнными. При этом окно времени для решительных ответных действий становится всё более узким, а угроза распространяется за пределы одной компании и конкретного региона. Триумф китайской DeepSeek состоялся примерно год назад, когда она представила свою модель R1, которая при сопоставимой результативности обошлась в обучении в разы дешевле создаваемых западными конкурентами. С тех пор китайские разработчики буквально наводнили рынок более доступными ИИ-моделями, которые позволяют работать с текстом, видео и изображениями. Американским компаниям, которые опираются на закрытую экосистему, стало сложнее монетизировать свои разработки. По данным Anthropic, китайские конкуренты использовали подставные учётные записи и прокси-серверы для доступа к данным Claude с минимальным риском обнаружения. Если DeepSeek осуществила более 150 000 обменов данными с Claude, то MiniMax преодолела планку в 13 млн обменов, пытаясь воссоздать передовые функции по примеру Claude, как считают в Anthropic. Отследить подобную активность Anthropic помогли партнёры, и в достоверности своих выводов компания очень уверена. Она формирует новые методы защиты от дистилляции своих моделей и готова делиться ими с другими представителями отрасли: «Ни одна из компаний не сможет с этим справиться в одиночку. Дистилляционные атаки такого масштаба требуют скоординированного ответа всей ИИ-отрасли, включая провайдеров облачных услуг и регуляторов». Google Gemini научился генерировать 30-секундные музыкальные треки по описанию и картинкам
19.02.2026 [06:55],
Алексей Разин
Бета-доступ к модели Lyria 3 входящей в состав Google лаборатории DeepMind позволил пользователям чат-бота Gemini создавать короткие 30-секундные музыкальные композиции на основе текстовых описаний, изображений и видеороликов, при этом даже не нужно покидать интерфейс чат-бота. 
Источник изображения: Nvidia С этой недели доступ к данному инструменту генерирования музыки получили пользователи Google по всему миру, на первом этапе поддерживаются запросы и результаты на английском, немецком, испанском, французском, японском, корейском и португальском языках, а также хинди. Запросы в этом сервисе могут упоминать как конкретные музыкальные стили, так и эмоциональный настрой, либо какие-то типичные жизненные ситуации. Сервис позволяет генерировать как инструментальные композиции, так и произведения с вокалом на текст, предложенный пользователем. Для более точного результата с точки зрения формируемого настроения пользователь может прилагать к текстовому запросу фотографии или видеоролики. Google подчёркивает, что подобный инструмент не направлен на создание музыкальных шедевров, а в большей мере ориентирован на развлечение и самовыражение пользователей. Для более удобного распространения созданных 30-секундных музыкальных композиций Google будет снабжать их обложками, сгенерированными при помощи Nano Banana. Эти композиции также можно будет использовать совместно с инструментом Dream Track, который позволяет сопровождать публикуемые в YouTube короткие видеоролики музыкой независимых авторов. Учитывая предыдущий опыт внедрения средств генерирования музыки при помощи ИИ, компания Google в модели Lyria 3 предусмотрела механизмы защиты от слепого копирования произведений конкретных авторов и голосов определённых исполнителей. Lyria существует с 2023 года, но доступ к ней был ограничен облачной платформой Google Vertex. Интеграция подобных возможностей в Google Gemini делает инструмент для генерирования музыки более доступным, но в этой сфере компания отстаёт по графику от многих конкурентов типа TikTok и Microsoft. Alibaba, ByteDance и Kuaishou представили ряд новых ИИ-моделей — от роботов до киношного видео
16.02.2026 [09:10],
Владимир Фетисов
В то время как ИИ-рынок США на прошедшей неделе был занят изучением влияния инструментов Anthropic и Altruist на сферы программирования и оказания финансовых услуг, китайские IT-гиганты запустили ИИ-модели, показавшие прирост производительности в робототехнике и генерации видео. Alibaba, ByteDance (владелец TikTok) и платформа коротких видео Kuaishou представили новые алгоритмы, подтверждающие, что китайские разработчики не отстают от американских коллег. 
Источник изображения: Gemini Анонс новых алгоритмов китайских IT-гигантов произошёл на фоне недавнего заявления главы ИИ-подразделения Google DeepMind Демиса Хассабиса (Demis Hassabis) касательно того, что китайские ИИ-модели отстают от западных конкурентов всего на несколько месяцев. Однако представленные на прошедшей неделе инструменты вполне могут рассматриваться в качестве прямых конкурентов ИИ-моделям для генерации видео, таким как Sora от OpenAI, а также моделям для сферы робототехники от Nvidia и Google. Исследовательское подразделение Alibaba DAMO анонсировало RynnBrain — ИИ-модель, предназначенную для того, чтобы помочь роботам понимать окружающий их физический мир и идентифицировать объекты. В демонстрационном ролике Alibaba показала робота с клешнями вместо рук, который собирал апельсины и складывал их в корзину. Там также показали, как робот достаёт молоко из холодильника. ИИ-модели требуют обширного обучения для достижения цели по идентификации повседневных объектов и взаимодействия с ними. Это означает, что такой простой для человека процесс, как сбор фруктов, для робототехники является гораздо более сложным. С запуском RynnBrain Alibaba начнёт конкурировать с такими компаниями, как Nvidia и Google, которые ведут разработку собственных ИИ-моделей для сферы робототехники. «Одним из её [ИИ-модели] ключевых новшеств является встроенное осознание времени и пространства. Вместо того, чтобы просто реагировать на непосредственные сигналы, робот может запоминать, когда и где происходили события, отслеживать прогресс выполнения задачи и продолжать действовать на протяжении нескольких этапов. Это делает его более надёжным и последовательным в сложных реальных условиях», — считает исследователь из Hugging Face Адина Якефу (Adina Yakefu). Она также добавила, что «более масштабная цель» Alibaba состоит в том, чтобы «создать базовый интеллектуальный уровень для воплощённых систем». Компания ByteDance на минувшей неделе представила Seedance 2.0 — модель искусственного интеллекта для генерации видео, которая может создавать реалистичные ролики на основе простого текстового описания. При этом алгоритм также может работать с другими видео и изображениями. Демонстрационные видео, созданные с помощью Seedance 2.0, выглядят вполне реалистично. 
Источник изображения: Sony Адина Якефу подтвердила, что ИИ-модель Seedance 2.0 показала значительный прогресс по сравнению с предыдущими версиями в плане «управляемости, скорости и эффективности работы». «На сегодняшний день Seedance 2.0 — одна из самых сбалансированных моделей для генерации видео, которые я тестировала. Она удивила меня, выдав удовлетворительные результаты с первой попытки, даже обрабатывая простой запрос. Визуализация, звуковое сопровождение и операторская работа объединяются таким образом, что результат работы кажется отточенным, а не экспериментальным», — добавила Якефу. Хоть пользователи и хвалят этот алгоритм, известно, что у Seedance 2.0 возникли проблемы. Китайские СМИ сообщили, что разработчики временно заблокировали функцию генерации голоса человека на основе загруженного фото. Это произошло после того, как один из местных блогеров обратил внимание на проблему генерации голоса по фото без согласия того, кто изображен на снимке. Представители ByteDance пока никак не комментируют данный вопрос. Ещё одной новинкой стала ИИ-модель Kling 3.0 от Kuaishou, которая предназначена для генерации видео и является конкурентом алгоритма ByteDance. В сообщении сказано, что Kling 3.0 «отличается существенными улучшениями в согласованности, фотореалистичности результата работы, увеличенным временем продолжительности видео до 15 секунд и встроенной генерацией аудио на нескольких языках, диалектах и с разными акцентами». В настоящее время алгоритм Kling 3.0 доступен только платным подписчикам, но вскоре Kuaishou обещает открыть его для более широкой аудитории пользователей. Успех компании с ИИ-моделями Kling способствовал росту стоимости акций Kuaishou более чем на 50 % за последний год. Стоит упомянуть некоторые другие важные релизы. Компания Zhipu AI, которая работает в Гонконге под названием Knowledge Atlas Technology, представила алгоритм GLM-5 — открытую языковую модель с расширенными возможностями в области программирования и создания ИИ-агентов. Компания заявила, что последняя версия её ИИ-модели приближается к Anthropic Claude Opus 4.5 по показателям в профильных бенчмарках, а также превосходит Google Gemini 3 Pro в некоторых тестах. Этот релиз способствовал значительному рост курса акций Zhipu AI. Стоимость ценных бумаг MiniMax также подскочила в конце недели после того, как компания запустила обновлённую версию открытой ИИ-модели M2.5 с улучшенными инструментами ИИ-агентов. Этот алгоритм может использоваться для эффективной автоматизации выполнения разных задач. OpenAI обвинила китайскую DeepSeek в краже данных для обучения ИИ-модели R1
13.02.2026 [12:11],
Алексей Разин
Агентство Bloomberg со ссылкой на служебную записку OpenAI сообщает, что создатели ChatGPT обвинили китайскую DeepSeek в использовании ухищрений, позволяющих добывать информацию американских ИИ-моделей для обучения китайского чат-бота R1 следующего поколения. Соответствующий доклад был направлен американским парламентариям, по данным источника. 
Источник изображения: Unsplash, Solen Feyissa По мнению представителей OpenAI, китайский конкурент использовал метод так называемой дистилляции, чтобы «бесплатно выехать на успехе технологий, разработанных OpenAI и других передовых американских компаний». Создателям ChatGPT якобы удалось выявить новые изощрённые методы получения доступа китайской DeepSeek к информации американских ИИ-моделей, которые призваны обходить существующие методы защиты. Беспокойство на эту тему OpenAI и Microsoft проявили ещё в прошлом году, когда начали соответствующее расследование в отношении деятельности DeepSeek. Метод дистилляции позволяет ускорить обучение сторонних ИИ-моделей с использованием данных уже обученных систем. Анализ активности на собственной платформе, как отмечает OpenAI, позволяет говорить об участившихся случаях применения дистилляции сторонними разработчиками ИИ-моделей — преимущественно расположенными в Китае, хотя в отчёте упоминается и Россия. Поскольку DeepSeek не предлагает своим клиентам платных подписок, как и многие другие китайские провайдеры подобных услуг, они получают большее распространение, чем проприетарные коммерческие решения западного происхождения, по мнению авторов доклада. Это угрожает мировому главенству ИИ-моделей американской разработки, как резюмируют они в своём обращении к специальному комитету американского парламента. Полученные методом дистилляции сторонние ИИ-модели, по словам представителей OpenAI, нередко лишены тех ограничений, которые устанавливаются создателями исходных систем, а потому могут использоваться во вред человечеству или отдельным странам. Попытки OpenAI оградить себя от дистилляции китайскими разработчиками успехом не увенчались, поскольку представители DeepSeek якобы получали доступ к американским ИИ-моделям разного рода окольными путями. По словам представителей OpenAI, существуют целые сети посредников, которые предоставляют доступ к услугам компании в обход существующих ограничений. Для американских чиновников существование подобных практик тоже не является откровением, отмечает Bloomberg. Американские политики обеспокоены и возможностью получения компанией DeepSeek доступа к более современным ускорителям вычислений Nvidia H200, поскольку их поставки в Китай в прошлом году успел разрешить американский президент Дональд Трамп (Donald Trump). В сочетании с существующими методами обучения своих моделей, DeepSeek могла бы в результате добиться существенного прогресса. Прежние расследования уже выявили, что DeepSeek использовала для обучения своих предыдущих ИИ-моделей оборудование Nvidia, хотя основная его часть была доставлена в Китай в рамках существовавших на тот момент правил экспортного контроля США. Политики теперь опасаются, что доступ DeepSeek к более современным чипам H200 сильнее навредит позициям США на мировой технологической арене. OpenAI выпустила GPT-5.3-Codex-Spark — свою первую ИИ-модель, работающую без чипов Nvidia
12.02.2026 [23:26],
Николай Хижняк
Компания OpenAI выпустила свою первую модель искусственного интеллекта, работающую на гигантских чипах-ускорителях Wafer Scale Engine 3 от стартапа Cerebras Systems. Данный шаг является частью усилий создателя ChatGPT по диверсификации поставщиков аппаратного обеспечения для обучения своих моделей. 
Источник изображения: OpenAI Модель GPT-5.3-Codex-Spark является менее мощной, но более быстрой версией продвинутой модели GPT-5.3-Codex, ориентированной на помощь в написании программного кода. Версия Spark позволит инженерам-программистам быстро выполнять такие задачи, как редактирование отдельных фрагментов кода и запуск тестов. Пользователи также могут легко прервать работу модели или дать ей указание выполнить что-то другое, связанное с вайб-кодингом, не дожидаясь завершения длительного вычислительного процесса. 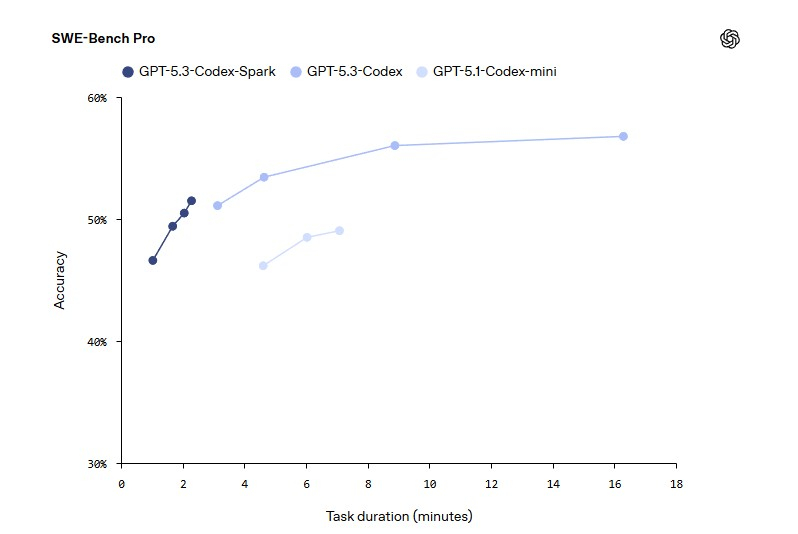
Источник изображения: OpenAI В прошлом месяце OpenAI заключила сделку на сумму более $10 млрд на использование оборудования Cerebras для ускорения обучения своих моделей ИИ. Для Cerebras это партнёрство представляет собой значительный шаг в её стремлении конкурировать на рынке аппаратных средств для ИИ, где долгое время доминирует компания Nvidia. Для OpenAI — это способ расширить сотрудничество с разными поставщиками оборудования для удовлетворения растущих вычислительных потребностей. 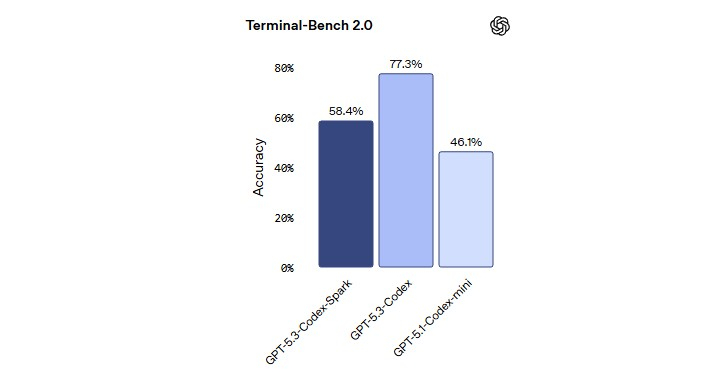
Источник изображения: OpenAI В октябре OpenAI заявила о заключении многолетнего соглашения о стратегическом партнёрстве, в рамках которого будет построена ИИ-инфраструктура на базе сотен тысяч ИИ-ускорителей AMD нескольких поколений общей мощностью 6 ГВт. Позже в том же месяце OpenAI согласилась приобрести специализированные чипы и сетевые компоненты у Broadcom. Как пишет Bloomberg, в последнее время отношения OpenAI с Nvidia оказались под пристальным вниманием на фоне сообщений о напряженности между двумя компаниями. Однако руководители обеих компаний публично заявили, что по-прежнему привержены сотрудничеству. В заявлении, опубликованном в четверг, представитель OpenAI заявил, что партнёрство компании с Nvidia является «основополагающим» и что самые мощные модели ИИ OpenAI являются результатом «многолетней совместной работы над аппаратным и программным обеспечением» двух компаний. «Именно поэтому мы делаем упор на Nvidia как на основу нашей системы обучения и вывода, целенаправленно расширяя экосистему вокруг неё за счёт партнёрств с Cerebras, AMD и Broadcom», — заявил представитель компании. Первоначально GPT-5.3-Codex-Spark будет доступна подписчикам ChatGPT Pro в качестве предварительной версии для исследований. OpenAI собирается предоставить доступ к новой ИИ-модели для более широкого числа пользователей в ближайшие недели. Компания также отмечает, что Codex имеет более 1 млн активных еженедельных пользователей. DeepSeek научилась тренировать языковые ИИ-модели без оглядки на ограничения по скорости памяти
14.01.2026 [11:55],
Алексей Разин
Как отмечалось недавно, пропускная способность памяти, используемой в инфраструктуре ИИ, становится одним из серьёзных ограничителей дальнейшего роста быстродействия языковых моделей. Представители DeepSeek утверждают, что разработали метод обучения ИИ-моделей, который позволяет обойти подобные ограничения со стороны памяти. 
Источник изображения: Unsplash, Solen Feyissa Группа исследователей Пекинского университета в сотрудничестве с одним из основателей DeepSeek Лян Вэньфэном (Liang Wenfeng) опубликовала научную работу, в которой рассматривается новый подход к обучению языковых моделей, позволяющий «агрессивно увеличивать количество параметров» в обход ограничений, накладываемых подсистемой памяти используемых в ускорителях GPU. От DeepSeek ожидают выхода новой версии большой языковой модели, но ритмичность их создания в случае с китайскими разработчиками сильно страдает от экспортных ограничений США и нехватки ресурсов в Китае. Текст нового исследования, соавтором которого является один из основателей DeepSeek, будет подробно изучаться специалистами в области искусственного интеллекта как в Китае, так и за его пределами. Описываемая в документе методика «условного» использования памяти получила обозначение Engram, как отмечает South China Morning Post. Существующие подходы к вычислениям при обучении больших языковых моделей, по мнению китайских исследователей, вынуждают напрасно тратить ресурсы на тривиальные операции, которые можно было бы высвободить для высокоуровневых операций, связанных с рассуждениями. Исследователи предложили в некотором смысле разделить вычисления и работу с памятью, обеспечивая поиск базовой информации более эффективными способами. Одновременно новая технология позволяет большим языковым моделям лучше обрабатывать длинные цепочки контекста, что приближает цель превращения ИИ-агентов в полноценных помощников человека. В рамках эксперимента новый подход при обучении модели с 27 млрд параметров позволил поднять общий уровень быстродействия на несколько процентов. Кроме того, система получила больше доступных ресурсов для осуществления сложных операций с рассуждениями. По мнению авторов исследования, данный подход будет незаменим при обучении языковых моделей нового поколения в условиях ограниченности ресурсов. По данным The Information, китайская компания DeepSeek намеревается представить новую модель V4 с развитыми способностями в области написания программного кода к середине февраля этого года. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






