|
Опрос
|
реклама
Быстрый переход
Nothing наделит все свои наушники поддержкой ИИ-бота ChatGPT
18.04.2024 [16:40],
Николай Хижняк
Компания Nothing сообщила о планах более глубокой интеграции ИИ-бота ChatGPT со своими смартфонами и наушниками. Благодаря этому владельцы этих устройств получат быстрый доступ к данному сервису. 
Источник изображения: Nothing «Благодаря новой интеграции пользователи с новейшей платформой Nothing OS и приложением ChatGPT, установленными на их смартфонах Nothing, смогут общаться с самым популярным в мире потребительским инструментом искусственного интеллекта прямо через наушники Nothing», — сообщила компания в своём официальном блоге. Новые наушники Nothing Ear (a) и Nothing Ear, представленные сегодня, также получат поддержку ChatGPT. Представитель компании в разговоре с порталом The Verge отметил, что «интеграция ChatGPT в продукты будет проходить постепенно. С 18 апреля поддержку ИИ-бота получит смартфон Phone (2). Через несколько недель такой же поддержкой обзаведутся смартфоны Phone (1) и Phone (2a)». После обновления пользователи смогут делать голосовые запросы к ChatGPT через наушники Nothing. В блоге компании также сообщается, в новую версию Nothing OS будут добавлены виджеты для запуска ChatGPT, а в меню управления скриншотами и всплывающем окне буфера обмена появилась функция, позволяющая напрямую вставить изображения в запрос для ChatGPT. Nothing представила беспроводные наушники Ear и Ear (a) с автономностью более 40 часов, шумоподавлением и ChatGPT
18.04.2024 [15:50],
Николай Хижняк
Компания Nothing представила две пары беспроводных наушников — Nothing Ear (a) стоимостью €99 или $99 и Nothing Ear стоимостью €149 или $149. Nothing Ear являются флагманским решением производителя и прямым наследником прошлогодней модели Ear (2). В свою очередь, модель Ear (a) призвана заполнить пробел в качестве более доступного варианта. Компания также объявила, что новые наушники и другие её аудиопродукты получат интеграцию чат-бота ChatGPT. 
Источник изображений: Nothing Наушники Nothing Ear получили 11-мм динамические драйверы с керамической диафрагмой для более насыщенных и чётких высоких частот, а также имеют по два вентиляционных отверстия для улучшения воздушного потока и более чёткого звучания. Для новинки заявляется поддержка кодеков LHDC 5.0 и LDAC для потоковой передачи звука высокой чёткости, а также использование улучшенного алгоритма Smart ANC, который автоматически подстраивает эффективность работы активной системы шумоподавления. Последняя отсекает лишние шумы громкостью до 45 дБА. 
Nothing Ear Nothing также обновила мобильное приложение Nothing X для управления настройками наушников, добавив улучшенный эквалайзер с кастомными настройками, а также возможность поделиться ими с друзьями. 
Nothing Ear К источнику сигнала Nothing Ear подключаются по протоколу Bluetooth 5.3, а также поддерживают двойное подключение через Google Fast Pair и Microsoft Swift Pair. Каждый наушник получил по три микрофона для повышения качества передачи голоса при разговоре и более эффективной работы системы активного шумоподавления. 
Nothing Ear Компания заявляет, что Nothing Ear проработают от батареи 8,5 часа (5,2 часа с ANC), а с чехлом-зарядкой — до 40,5 часа (без ANC). Наушники поддерживают проводную зарядку через USB-C, а также беспроводную зарядку мощностью до 2,5 Вт через зарядные устройства стандарта Qi. Для наушников заявляется защита от воды и пыли IP54. Для чехла указана защита IP55. Nothing Ear будут доступны в чёрном и белом вариантах исполнения. Предзаказы на новинку уже принимаются. В продажу наушники поступят 22 апреля. 
Nothing Ear (a) Модель беспроводных наушников Nothing Ear (a) сохранила большинство ключевых особенностей более дорогих Nothing Ear. Они тоже получили 11-мм динамические излучатели, поддержку ANC (45 дБА), а также кодека LDAC. А вот поддержки LHDC нет. Для Nothing Ear (a) не заявляется поддержка кастомных настроек эквалайзера и керамической диафрагмы. 
Nothing Ear (a) В то же время Nothing Ear (a) на час дольше проработают в автономном режиме без ANC. С включённой ANC время работы составит 5,5 часа. Подзарядка от чехла обеспечит новинке до 42,5 часа работы. Поддержки беспроводной зарядки у Nothing Ear (a) нет. Заряжаются они только от USB-C. Также для Nothing Ear (a) заявлена защита от воды и пыли IP54, а для чехла-зарядки указывается защита IPX2. 
Nothing Ear (a) Nothing Ear (a) предлагает несколько иной дизайн конструкции и поставляются в прямоугольном чехле-зарядке. Они будут предлагаться в белом, чёрном и жёлтом вариантах исполнения, а в продаже появятся с 29 апреля. Для обеих пар наушников также заявляется поддержка чат-бота ChatGPT, которого можно будет настроить через мобильное приложение Nothing X. Вызывать чат-бота можно будет с помощью касания двумя пальцами одного из наушников. Поддержка ChatGPT также скоро станет доступна для наушников Ear (1), Ear (2) и Ear (stick), а к июню появится в продуктах CMF, суббренда Nothing. GPT-4 освоил Red Dead Redemption 2, но его подводит машинное зрение
15.04.2024 [20:46],
Сергей Сурабекянц
Группа исследователей из Китая и Сингапура научила ИИ на базе OpenAI GPT-4V играть в Red Dead Redemption 2 (RDR2). В своей статье они рассказали о концепции общего компьютерного контроля (General Computer Control, GCC) для ИИ, и о мультимодальном агенте CRADLE — интерфейсе между GPT-4V и RDR2. По их мнению, основные проблемы у игрового ИИ-агента возникли при использовании машинного зрения. 
Источник изображения: Rockstar Исследователи поставили своей целью заставить ИИ, работающий на базе OpenAI GPT-4V, взаимодействовать с компьютером, воспринимая визуальные и звуковые сигналы, как это делает среднестатистический человек-пользователь ПК. Проект даёт представление о том, насколько далеко продвинулись разработчики ИИ в движении в сторону создания общего (сильного) искусственного интеллекта (AGI). Исследователи выбрали RDR2, так как она имеет «сложную систему управления черным ящиком, которая воплощает в себе самые требовательные компьютерные задачи и позволяет нам оценить границы производительности нашей платформы в таких виртуальных средах». Кроме того, такие элементы пользовательского интерфейса, как диалоги, уникальные значки, внутриигровые подсказки и инструкции, гарантируют, что никакие базовые знания не воспринимаются как нечто само собой разумеющееся, что отлично подходит для обучения ИИ. Исследователи утверждают, что управление игрой с помощью мыши и клавиатуры обеспечивает лучшую тренировку для GCC. 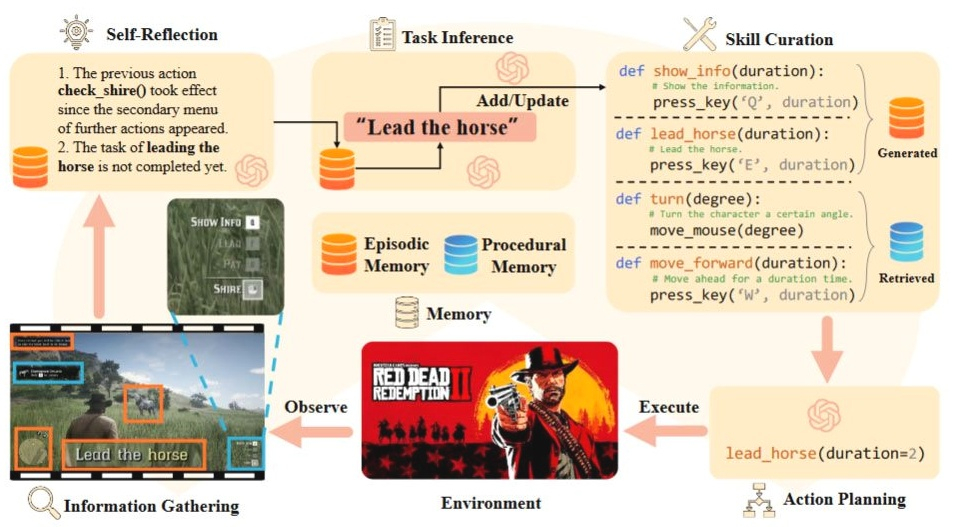
Как устроен CRADLE / Источник изображения: arxiv.org Исследователи стремились продемонстрировать способность ИИ изучать игру с нуля (без доступа к какому-либо внутреннему состоянию игры или API), то есть как это делает человек. ИИ-агент «проходил» игру, перемещаясь по миру и выполняя задания, следуя основной сюжетной линии RDR2. В целом, CRADLE добился заметного успеха в RDR2. Он смог «последовательно выполнять все задачи основной сюжетной линии», за исключением миссии с ураганной перестрелкой, заданий, которые требуют исследования сложного внутреннего мира, и многоэтапных миссий с открытым финалом. 
Как CRADLE выполняет игровые задания / Источник изображения: arxiv.org Исследователи считают, что причиной некоторых повторяющихся трудностей, с которыми сталкивался CRADLE, является GPT4-V. По их мнению, «возможности пространственно-визуального распознавания GPT-4V недостаточны для точного детального контроля». GPT4-V не справился с концепциями, специфичными для предметной области, такими как уникальные значки в игре, с пониманием мини-карт, а также с общими препятствиями в игровой среде. 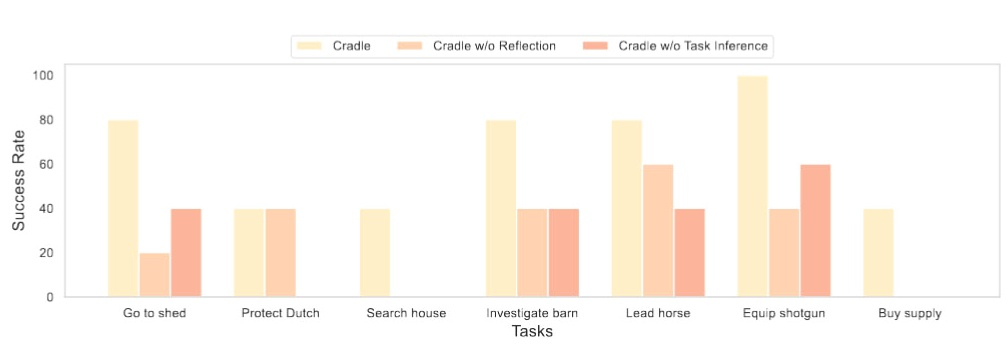
Производительность CRADLE в разных типах миссий / Источник изображения: arxiv.org Хотя опубликованная статья посвящена взаимодействию ИИ с RDR2, авторы утверждают, что предназначение системы CRADLE в рамках GCC гораздо шире: «для поддержки более широкого спектра игр, таких как игры-симуляторы и стратегии, а также различных программных приложений». Сэм Альтман занялся продвижением ChatGPT среди крупных корпоративных клиентов
12.04.2024 [19:49],
Владимир Фетисов
В этом месяце глава OpenAI Сэм Альтман (Sam Altman) провёл несколько встреч, в которых приняли участие сотни руководителей компаний из списка Fortune 500. Прошедшие в Сан-Франциско, Нью-Йорке и Лондоне мероприятия были посвящены презентации функций на основе искусственного интеллекта для корпоративного сегмента. Об этом пишет агентство Reuters со ссылкой на собственные осведомлённые источники. 
Источник изображения: OpenAI Эти мероприятия наглядно демонстрируют, как OpenAI, с потребительских приложений которой началось бурное развитие генеративных нейросетей, стремится к поиску новых источников дохода. Очевидно, что в видении компании такими источниками должны стать корпоративные клиенты по всему миру, причём некоторые из потенциальных клиентов могут являться партнёрами крупнейшего спонсора OpenAI, которым является Microsoft. О трёх прошедших недавно в США и Англии встречах не сообщалось публично. По словам осведомлённых источников, в рамках каждой из таких встреч Альтман напрямую обращался более чем к 100 руководителям разных компаний. На каждом мероприятии Альтман и главный операционный директор OpenAI Брэд Лайткэп (Brad Lightcap) демонстрировали собравшимся разные программные продукты, в том числе ChatGPT Enterprise — корпоративную версию популярного ИИ-бота, а также API для подключения клиентских приложений к своим ИИ-сервисам и новые генеративные модели, позволяющие создавать видео по текстовому описанию. OpenAI обещает клиентам, что их данные, которые станут доступны алгоритму ChatGPT Enterprise, не будут использоваться для обучения больших языковых моделей (LLM). Общаясь с потенциальными клиентами из финансовой, энергетической отраслей, сферы здравоохранения, руководители OpenAI рассказали о нескольких приложениях для разных сфер бизнеса, а также отметили, что потребительскую версию бота ChatGPT уже используют 92 % компаний из списка Fortune 500. Напомним, Microsoft является крупнейшим инвестором в OpenAI и предлагает доступ к ИИ-технологиям компании через свою облачную платформу Azure. Пользователи сервиса Microsoft 365 также имеют доступ к ИИ-помощнику Copilot, который представляет собой инструмент для повышения продуктивности, в основе которого лежат алгоритмы OpenAI. Во время встреч руководителей OpenAI с представителями бизнеса некоторые из участников задавали вопрос, почему они должны платить за ChatGPT Enterprise, если они уже являются клиентами Microsoft. Альтман и Лайткэп ответили, что оплата корпоративного ИИ-бота позволит компаниям напрямую взаимодействовать с OpenAI, иметь доступ к новейшим LLM, а также индивидуальным продуктам на основе ИИ. Официальные представители OpenAI и Microsoft отказались от комментариев по данному вопросу. OpenAI сделала ChatGPT «более чётким и менее многословным», но только для платных пользователей
12.04.2024 [11:24],
Павел Котов
Компания OpenAI объявила о крупном обновлении ChatGPT, которое затронет пользователей всех платных версий популярного чат-бота — теперь они могут работать со свежей улучшенной версией нейросети GPT-4 Turbo. Напомним, что OpenAI предлагает три платных тарифа: ChatGPT Plus, Team или Enterprise. 
Источник изображения: Growtika / unsplash.com Новая модель версии gpt-4-turbo-2024-04-09 улучшила способности в написании текстов и программного кода, решении математических задач и логических рассуждениях, кроме того, она получила более актуальную базу знаний. Нейросеть была обучена на общедоступных данных по состоянию на декабрь 2023 года — предыдущая версия GPT-4 Turbo, на которой работал ChatGPT, была ограничена апрелем 2023 года. 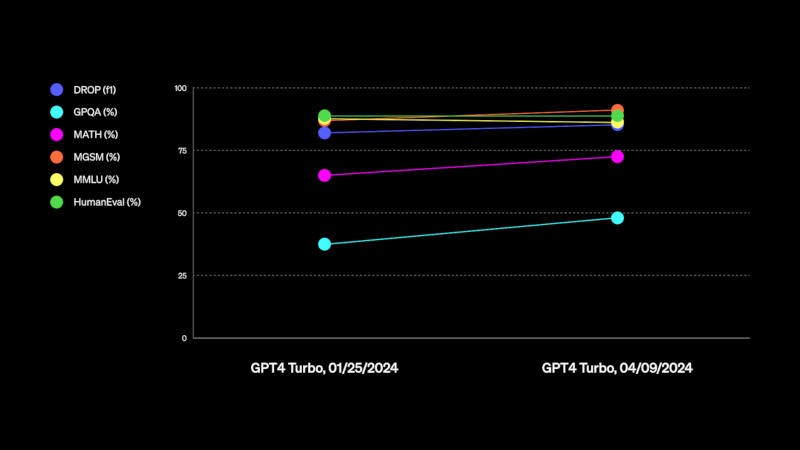
Источник изображения: twitter.com/OpenAI «При написании [текстов] с помощью ChatGPT [с новым GPT-4 Turbo] ответы будут более чёткими, менее многословными и с бо́льшим использованием разговорного языка», — рассказала OpenAI в соцсети X. В минувший вторник компания также сделала доступными через API ряд новых моделей, включая нейросеть GPT-4 Turbo with Vision, которая в качестве запросов принимает не только текст, но и изображения. 
Источник изображения: twitter.com/OpenAI В остальном неделя для OpenAI выдалась непростой. Microsoft представила генератор изображений на базе OpenAI DALL-E в качестве инструмента для работы специалистов Вооружённых сил США, выяснило издание The Intercept. Сама же OpenAI уволила двух исследователей, в том числе соратника главного научного сотрудника компании Ильи Суцкевера (Ilya Sutskever), который был одним из инициаторов непродолжительного увольнения гендиректора Сэма Альтмана (Sam Altman), передаёт The Information. OpenAI для обучения GPT-4 расшифровала миллионы видео с YouTube — текстов в интернете не хватило. Google тоже так делает
09.04.2024 [00:00],
Владимир Чижевский
Несколько дней назад сообщалось, что разработчики ИИ столкнулись с нехваткой данных для обучения передовых моделей, в том числе о планах Open AI обучать GPT-5 на видео с YouTube. Согласно материалу The New York Times, в погоне за новыми данными корпорации забывают об этике и морали. 
Источник изображения: freepik.com К концу 2021 года OpenAI столкнулась с нехваткой авторитетных англоязычных текстов в интернете для обучения новейшей модели искусственного интеллекта — ей требовалось гораздо больше данных. Тогда разработчики OpenAI создали расшифровывающую аудиозаписи из видеороликов на YouTube систему распознавания речи Whisper, которая выдаёт текст для обучения ИИ. По словам нескольких сотрудников, в компании понимали, что такой шаг может противоречить правилам использования YouTube, запрещающим использовать видеоролики «независимо» от платформы. Это не остановило OpenAI, расшифровавшую более миллиона часов видеороликов с YouTube. Полученный текст использовался для обучения GPT-4 — одной из мощнейших систем искусственного интеллекта в основе последней версии ChatGPT. В исследовании The New York Times говорится, что в гонку за данными включились все передовые разработчики ИИ, включая OpenAI, Google и Meta✴, причём компании зачастую игнорируют корпоративные политики, а иногда и закон. 
Джаред Каплан. Источник: physics-astronomy.jhu.edu В январе 2020 года физик-теоретик из Университета Джонса Хопкинса Джаред Каплан (Jared Kaplan) опубликовал работу об ИИ, которая разожгла аппетиты их разработчиков. Он высказался однозначно: чем больше данных используется для обучения языковой модели, тем лучше она работает, подобно тому, как студенты получают всё больше знаний из прочитанных книг. Языковые модели могут устанавливать закономерности и взаимосвязи, что позволяет точнее обрабатывать новую информацию. 
Сэм Альтман. Источник изображения: wikipedia.org Позднее Сэм Альтман (Sam Altman) из OpenAI заявил, что данные рано или поздно кончатся — он знает, о чём говорит, ведь компания годами собирала данные, обрабатывала и обучали на них ИИ. Среди использованных данных был программный код с GitHub, базы данных шахматных ходов, школьные тесты и домашние задания старшеклассников. К концу 2021 года они закончились. Помимо расшифровки аудио- и видеоматериалов, рассматривалась покупка компаний, имеющих доступ к огромным объёмам цифровых данных. 
Марк Цукерберг. Источник изображения: профиль в Facebook✴ Глава Meta✴ Марк Цукерберг (Mark Zuckerberg) годами развивал ИИ-направление, но выход ChatGPT в конце 2022 года оставил его компанию далеко позади. Трое бывших и нынешних сотрудников Meta✴ рассказали, что стремясь догнать OpenAI, он день и ночь донимал менеджеров и ведущих инженеров, чтобы те как можно скорее выпустили конкурирующий продукт. Но как и все остальные, Meta✴ упёрлась лбом в стену нехватки данных. 
Ахмад Аль-Дахле. Источник изображения: профиль на LinkedIn На одном из записанных совещаний руководства Meta✴ говорилось, что компания наняла субподрядчиков из Африки для сбора защищённых авторским правом материалов. «Мы не можем не собирать их», — сказали на одном из таких совещаний. Кроме того, подчёркивалось, что OpenAI тоже не стесняется использовать защищённые авторским правом материалы без разрешения их владельцев, и получать эти разрешения «слишком долго». В Google Books появились книги сомнительного качества, написанные ИИ
05.04.2024 [22:33],
Владимир Чижевский
Эмануэль Майберг (Emanuel Maiberg) из 404Media провёл нехитрое исследование и обнаружил, что Google Books индексирует сгенерированные ИИ книги, при том довольно плохого качества. Для их поиска он использовал характерную для сгенерированных ИИ ответов фразу «As of my last knowledge update» («По последним данным из моей базы знаний»), и результаты его удивили, хотя ранее он уже находил написанные с использованием ИИ книги на Amazon и Google Play. 
Источник изображения: freepik.com Большинство книг с этой фразой на первых восьми страницах выдачи оказались не связаны с темой ИИ, для которой она была бы уместной. В качестве примера Майберг приводит книгу «Медведи, быки и волки: биржевая торговля для 20-летних» (Bears, Bulls, and Wolves: Stock Trading for the Twenty-Year-Old), которую автор позиционирует как «всеобъемлющее руководство для новичков, стремящихся раскрыть тайны финансовых рынков». Своим содержанием она напомнила сгенерированный ChatGPT текст с поверхностным анализом сложных событий, на уровне «Википедии». В других рассмотренных Майбергом книгах содержались откровенно устаревшие, бесполезные читателю в 2024 году сведения, которые скорее всего были почерпнуты ChatGPT из своей «базы знаний». Он приводит в пример вышедшую в марте 2024 года книгу «Максимум от Twitter: Стратегии успешного продвижения для новичков» (Maximize Your Twitter Presence: 101 Strategies for Marketing Success) Шу Чен Хоу (Shu Chen Hou). Как и в случае со множеством подобных авторов, на его счету числится не один десяток книг. В конце многостраничного раздела о верификации учётной записи в Twitter (ныне X) Майберг обнаружил строки: «Насколько мне известно на сентябрь 2021 года Twitter находилась в процессе переоценки и обновления критериев и процесса верификации, поэтому необходимые шаги могли измениться». В 2022 году Twitter приобрёл Илон Маск и превратил верификацию в торговлю «галочками». «Не могу поверить, что в компании не знают, что ищут пользователи в Google Books. Они индексируют всё подряд, но мне хотелось бы верить, что они могут распознать сгенерированные ИИ материалы, и они оказали бы себе и пользователям огромную услугу, если их промаркировали», — прокомментировал открытия Майберга библиотекарь, консультант и редактор infoDOCKET. Отдельное беспокойство Майберга вызывает возможное влияние таких книг на Google Ngram — профессиональный инструмент, оценивающий частоту вхождения фраз и отдельных слов в проиндексированных книгах с 1500 по 2019 годы. Он интересен тем, что учёные и исследователи используют его для оценки культурных тенденций. Соответственно, распространение написанных ИИ книг может заметно исказить результаты анализа с использованием Google Ngram. Однако представитель Google отрицает влияние сгенерированных книг на Google Ngram: «Наши автоматизированные алгоритмы настроены на поиск релевантных высококачественных книг. Указанные вами книги найдены по необычному и очень специфичному запросу, и не влияют на результаты Ngram. Мы стремимся, чтобы Ngram оставался высококачественным инструментом и продолжим адаптировать его по мере развития индустрии книгоиздания». «Ngram уже сейчас даёт довольно неточные данные, чтобы на них могли опираться вычислительные социологи и лингвисты, а через несколько лет он, вероятно, и вовсе потеряет значимость, — прокомментировала Алекс Ханна (Alex Hanna), директор по исследованиям Distributed AI Research Institute (DAIR). — Это ещё один пример того, как искусственный интеллект начинает поглощать сам себя. Созданный им контент попадает в Google Books, а затем Google начинает тренировать на его основе собственные модели. Да, они скажут, что тщательно контролируют качество, но детали они, конечно, не раскроют». Без регистрации и SMS: для работы с ChatGPT больше не нужна учётная запись
01.04.2024 [23:49],
Владимир Чижевский
Теперь для доступа к бесплатной версии популярного чат-бота с искусственным интеллектом ChatGPT не потребуется заводить учётную запись. Впрочем, это не относится к платным продуктам OpenAI вроде DALL-E 3 или более продвинутой версии ChatGPT Plus. 
Источник изображения: unsplash.com Учётная запись по-прежнему нужна не только для генератора изображений DALL-E, но и для доступных ограниченному кругу пользователей и партнёров продуктов OpenAI, таких как платформа для генерации видеороликов Sora или недавно анонсированный ИИ VoiceEngine. Также для использования платной версии ChatGPT на базе нейросети GPT-4 потребуется завести аккаунт. Чат-бот доступен через chatgpt.com и пока работает только в США. OpenAI подчеркнула, что незарегистрированные пользователи также смогут отказаться от использования передаваемых ими чат-боту данных для обучения ИИ. Чтобы обезопасить себя и пользователей от возможных проблем, OpenAI ввела «дополнительные меры защиты », включающие блокировку запросов «на самые разные [запретные] темы », список которых не приводится. По словам OpenAI, еженедельно ChatGPT пользуются более 100 миллионов человек в 185 странах. Сервис по отслеживанию трафика SimilarWeb сообщает о 1,6 млрд посетителей лишь за февраль 2024 года, что делает ChatGPT популярнейшем чат-ботом в мире. Хотя на пятки ему наступает Gemini от Google, месячное количество уникальных посетителей которого в мае прошлого года предположительно достигало 1,8 млрд. Для обучения GPT-5 не хватит качественных данных из всего интернета
01.04.2024 [23:09],
Владимир Чижевский
Разработчики передовых моделей искусственного интеллекта столкнулись с неожиданной проблемой — нехваткой качественного материала для их обучения. Ситуация усугубляется тем, что некоторые ресурсы блокируют доступ ИИ к своим данным. По словам исследователей, попытки обучать ИИ на материалах других моделей и прочем «синтетическом контенте» могут обернуться «большими проблемами». 
Источник изображения: Steve Johnson / unsplash.com Учёные и руководители компаний-разработчиков ИИ обеспокоены, что в ближайшие два года качественных текстов может не хватить для дальнейшего обучения больших языковых моделей (LLM), что замедлит развитие отрасли. Разрабатывающая ChatGPT компания OpenAI уже рассматривает возможность обучения GPT-5 на транскрипциях публичных роликов на YouTube. Языковые модели ИИ собирают тексты из интернета — научные исследования, новости, статьи из «Википедии» — и разбивают их на отдельные слова или их части, используя их, чтобы научиться отвечать как человек. Чем больше входящих данных, тем лучше результат — именно на это уповала OpenAI, что помогло ей стать одним из лидеров отрасли. По словам изучающего искусственный интеллект в Исследовательском институте Epoch Пабло Вильялобоса (Pablo Villalobos), GPT-4 обучался на 12 триллионах токенов данных, а в соответствии с законами масштабирования Шиншиллы, ИИ вроде GPT-5 потребуется 60–100 триллионов токенов. Если собрать все высококачественные текстовые и графические данные в интернете, для обучения GPT-5 не хватит от 10 до 20 триллионов токенов, а может и больше — и пока непонятно, где их взять. Два года назад Вильялобос и другие исследователи уже предупреждали, что к середине 2024 года с вероятностью 50 % ИИ уже не будет хватать данных для обучения, к 2026 — с вероятностью 90 %. По словам учёных, большинство данных в интернете непригодно для обучения ИИ, поскольку содержит бессвязный текст или не добавляет новой информации к уже имеющейся. Для этой цели подходит лишь малая часть материала — примерно десятая доля собранного некоммерческой организацией Common Crawl, чей веб-архив широко используется разработчиками ИИ. Тем временем, крупные платформы вроде социальных сетей и новостных агентств закрывают доступ к своим данным, а общественность не горит желанием открывать личную переписку для обучения языковых моделей. Марк Цукерберг (Mark Zuckerberg) считает огромным преимуществом в разработке ИИ доступ Meta✴ к данным на своих платформах, среди которых текст, изображения и видео — правда, трудно сказать, какую долю этих материалов можно считать качественной. 
Ари Моркос. Источник изображения: arimorcos.com Стартап DatologyAI пытается бороться с нехваткой контента, используя методику «учебного плана», согласно которой данные «скармливаются» ИИ в определённом порядке, помогающем установить связь между ними. В опубликованной в 2022 году работе бывшего сотрудника Meta✴ Platform и Google DeepMind, а ныне основателя DatologyAI Ари Моркоса (Ari Morcos) подсчитано, что данный подход помогает добиваться сопоставимых успехов в обучении ИИ при сокращении входящих данных вдвое. Впрочем, другие исследования эти данные не подтвердили. Сэм Альтман (Sam Altman) также рассказал, что OpenAI разрабатывает новые методики обучения ИИ. По слухам, в стенах компании обсуждается возможность создания рынка данных, на котором бы определялась ценность конкретных материалов для каждой модели и справедливая цена, которую можно за них заплатить. Эта же идея обсуждается в Google, однако конкретных подвижек в этом направлении пока нет, поэтому компании-разработчики ИИ стараются дотянутся до всего, что только можно, в том числе видео- и аудиоматериалов — по словам источников в OpenAI, их собираются расшифровывать инструментом распознавания речи Whisper. 
Сэм Альтман. Источник изображения: wikipedia.org Исследователи из OpenAI и Anthropic экспериментируют с так называемыми «высококачественными синтетическими данными». В недавнем интервью главный научный сотрудник Anthropic Джаред Каплан (Jared Kaplan) сказал, что подобные «сгенерированные внутри компании данные» могут быть полезные и использовались в последних версиях Claude. Пресс-секретарь OpenAI также подтвердил подобные разработки. Многие исследователи проблемы нехватки данных не верят, что смогут с ней справиться, однако Вильялобос не теряет оптимизма, и верит, что впереди ещё много открытий. «Самая большая неопределённость в том, что мы не знаем, какие революционные открытия ещё предстоят», — сказал он. По словам Ари Моркоса, нехватка данных — одна из важнейших проблем отрасли. Однако её развитие тормозит не только это — необходимые для работы больших языковых моделей чипы также в дефиците, а лидеры отрасли обеспокоены нехваткой центров обработки данных и электроэнергии. Американским парламентариям запретили использовать Microsoft Copilot в служебных целях
31.03.2024 [11:27],
Алексей Разин
Существующие системы искусственного интеллекта в большинстве своём используют облачные информационные ресурсы, подгружая в них обрабатываемые пользовательские данные, и это может представлять определённую угрозу для безопасности. Конгресс США, как следует из опубликованных рекомендаций, запрещает своим членам использовать сервис Microsoft Copilot в служебных целях. 
Источник изображения: Unsplash, Louis Velazquez Поскольку указанный сервис призван упрощать работу с документами, у американских парламентариев, как предполагают авторы рекомендации, может возникать соблазн оптимизировать свою деятельность с помощью данного инструмента, но облачные ресурсы Microsoft, используемые сервисом Copilot, не одобрены данным органом власти как достаточно безопасные, а потому от подобных действий членам обеих палат парламента США рекомендовано воздержаться. Все служебные ПК с операционной системой Windows, которые используются американскими парламентариями, подвергнутся настройке, подразумевающей блокировку сервиса Microsoft Copilot или даже его удаление при наличии такой технической возможности. В свою очередь, корпорация Microsoft к лету этого года планирует разработать специальный защищённый сервис для правительственных учреждений, который предоставит им доступ к искусственному интеллекту с более высокой степенью безопасности. Представители профильного комитета Конгресса США дали понять, что после выхода подобной версии Copilot проведут отдельную экспертизу пригодности данного сервиса для работы с данными правительственных структур. Ещё в прошлом году американским законодателям было запрещено использовать бесплатную версию ChatGPT из тех же соображений, но более продвинутый сервис ChatGPT Plus остался им доступен, пусть и только для анализа уже хранящейся в облаке информации. Магазин чат-ботов ChatGPT провалился, но им пользуются ученики школ и университетов
28.03.2024 [15:48],
Павел Котов
Генеральный директор OpenAI Сэм Альтман (Sam Altman) рассчитывал, что площадка кастомных чат-ботов на основе ChatGPT поможет компании расширить бизнес, но на практике она привлекла довольно специфический контингент, а некоторые проекты, возможно, нарушают правила использования платформы. 
Источник изображения: Growtika / unsplash.com Среди наиболее популярных спецверсий ChatGPT значатся проекты, работающие в образовательных целях, есть и инструменты для поиска и пересказа научных работ, сообщает Financial Times со ссылкой на данные исследования LikeWeb. В этом году отметился рост популярности дизайнерских инструментов с генерацией изображений, переводчики и средства для кадровиков, помогающие обрабатывать резюме и сопроводительные письма. Некоторые из проектов, возможно, нарушают политику OpenAI, которая запрещает создавать чат-боты, предоставляющие финансовые, юридические и медицинские консультации без одобрения квалифицированными специалистами. Пять из наиболее просматриваемых приложений провозглашаются разработчиками как способные создавать контент, который проходит проверку применяемых в школах и университетах средств обнаружения материалов, созданных ИИ. Эти кастомные чат-боты в общей сложности набрали не менее 3 млн просмотров, хотя OpenAI напрямую запрещает приложения, позволяющие жульничать в академической среде или пропагандирующие такие действия. 
Источник изображения: ft.com Более 200 тыс. раз люди пользовались приложением Finance Wizard, которое якобы предсказывает будущую динамику акций. Оно составляет прогнозы на основе исторических данных, а его описание включает заявление об отказе от ответственности, предостерегающее от его использования как инструмента финансовых рекомендаций, подчеркнул разработчик. В прошлом году Сэм Альтман пообещал, что OpenAI позаботится о соответствии чат-ботов её политике — в этом компании должны помогать автоматизированные средства, анализ сотрудников компании и отзывы пользователей. Аудитория оригинальной версии ChatGPT составляет 100 млн пользователей в неделю, и цифровая платформа с кастомизированными версиями чат-бота призвана способствовать развитию бизнеса компании — иногда эта стратегия рассматривается как попытка повторить успех магазина приложений Apple App Store. В этом году ожидается запуск программы монетизации для разработчиков передовых проектов. На кастомные чат-боты в феврале пришлись лишь 1,5 % посещений сайта ChatGPT с десктопных компьютеров; еженедельный трафик расти перестал. В OpenAI сообщили, что платформу посетили миллионы пользователей — она будет улучшаться, а отзывы от разработчиков для неё очень важны. Собственные проекты здесь запустили и известные разработчики: туристическое приложение AllTrails, некоммерческая образовательная организация Khan Academy и поисковая система для путешествий Kayak. Одной из первых собственный чат-бот запустила австралийская технологическая компания Canva — он генерирует изображения для соцсетей, а число его просмотров превысило 4,4 млн. В середине года ИИ выйдет на новый уровень — OpenAI выпустит «существенно улучшенную» нейросеть GPT-5
20.03.2024 [13:48],
Павел Котов
В ближайшие месяцы OpenAI готовится выпустить новую версию своей модели генеративного искусственного интеллекта, лежащей в основе сервиса ChatGPT — этот сервис положил начало теперешнему буму ИИ. 
Источник изображения: Growtika / unsplash.com Компания OpenAI планирует выпустить модель GPT-5 где-то в середине 2024 года, вероятно, летом, сообщает Business Insider со ссылкой на собственные источники. Некоторые корпоративные клиенты уже получили демонстрационные версии модели нового поколения и связанных с ней функций ChatGPT. «Она действительно хороша, даже существенно лучше», — прокомментировал один из испробовавших GPT-5 глав компаний. OpenAI показала работу модели со сценариями её использования и уникальными для его компании данными. Разработчик также упомянул о других, ещё не реализованных функциях модели, в том числе о возможности вызывать ИИ-агентов для автономного выполнения задач. Дата выпуска GPT-5 ещё не намечена. Сейчас OpenAI продолжает обучать GPT-5. Когда обучение завершится, компания проверит модель на безопасность собственными силами, после чего она будет подвергнута стресс-тестированию: сотрудники OpenAI и сторонние специалисты будут различными способами её провоцировать, чтобы обнаружить возможные проблемы, прежде чем GPT-5 станет общедоступной. Конкретных сроков завершения тестирования пока тоже нет, поэтому её выпуск может откладываться. Модель OpenAI GPT-4, ставшая последним крупным обновлением ChatGPT, вышла уже год назад. Разработчик заявлял, что она предоставляет более точные и оперативные ответы, но со временем в GPT-4 обнаружились такие проблемы как деградация и «лень» — отказ ИИ отвечать на запросы. Попыткой решить последнюю проблему стал выпуск GPT-4 Turbo. Наиболее важные данные обучающего массива ИИ принадлежат правообладателям, и OpenAI выступает против попыток ограничить доступ к этой информации для больших языковых моделей. В плагинах ChatGPT нашли уязвимости, позволявшие взламывать учётные записи на сторонних платформах
15.03.2024 [17:40],
Павел Котов
Компания Salt Security обнаружила в некоторых плагинах ChatGPT критические уязвимости, через которые злоумышленники могли получать несанкционированный доступ к учётным записям пользователей на сторонних платформах. Речь идёт о плагинах, позволяющих ChatGPT выполнять такие операции, как, например, правка кода на GitHub или получение данных с «Google Диска». 
Источник изображения: ilgmyzin / unsplash.com Плагины ChatGPT — это альтернативные версии чат-бота на основе искусственного интеллекта, и публиковать их может любой разработчик. Эксперты Salt Security обнаружили три уязвимости. Первая касается процесса установки плагина — ChatGPT отправляет пользователю код подтверждения установки, но у злоумышленников есть возможность подменять его кодом для установки вредоносного плагина. Вторая уязвимость обнаружена на платформе PluginLab, которая используется для разработки плагинов ChatGPT, — здесь отсутствовала достаточная защита при аутентификации пользователей, в результате чего хакеры могли перехватывать доступ к их учётным записям. Одним из плагинов, которые затронула эта проблема, был AskTheCode, предусматривающий интеграцию ChatGPT и GitHub. Третья уязвимость обнаружилась в нескольких плагинах, и в её основу легли манипуляции с перенаправлениями при авторизации через протокол OAuth. Она тоже позволяла перехватывать доступ к учётным записям на сторонних платформах. Плагины не имели механизма проверки URL-адресов при перенаправлении, что позволяло злоумышленникам отправлять пользователям вредоносные ссылки для кражи их аккаунтов. Salt Security заверила, что следовала стандартной процедуре и уведомила о своих открытиях OpenAI и другие стороны. Ошибки были исправлены оперативно, и свидетельств о наличии эксплойтов обнаружить не удалось. Microsoft добавила мощнейшую нейросеть GPT-4 Turbo в бесплатную версию Copilot
14.03.2024 [19:46],
Сергей Сурабекянц
Microsoft существенно повысила производительность и расширила возможности своего чат-бота Copilot. Теперь все бесплатные пользователи Copilot могут получить доступ к большой языковой модели (LLM) GPT-4 Turbo от OpenAI. Раньше доступ к GPT-4 Turbo можно было получить только при покупке подписки Microsoft Copilot Pro стоимостью $20 в месяц. 
Источник изображения: Microsoft Сегодня руководитель отдела рекламы и веб-сервисов Microsoft Михаил Парахин объявил, что «после немалой работы» GPT-4 Turbo теперь доступен для бесплатных пользователей Copilot. Он отметил, что подписчики Copilot Pro, которые предпочитают более старую версию LLM GPT-4 в Copilot, могут переключиться на эту модель, выбрав соответствующую опцию в меню. Партнёр Microsoft по разработке генеративного ИИ, компания OpenAI, впервые анонсировала GPT-4 Turbo в ноябре 2023 года. «Турбо-версия» предлагает пользователям доступ к гораздо большему контекстному окну размером 128 тыс. символов, что доводит объём текстовой подсказки до 300 страниц. Поддержка ChatGPT-4 Turbo появилась в подписке Copilot Pro в декабре. 
Источник изображения: OpenAI Эта неделя была очень важной для команды Copilot. В понедельник Microsoft подтвердила, что все пользователи Copilot Pro теперь могут получить доступ к Copilot GPT Builder. Новый инструмент позволяет без навыков программирования создавать собственных чат-ботов, «заточенных» отвечать на конкретные вопросы по целевым темам. Подписчики Copilot Pro смогут предоставлять неограниченный доступ к своим чат-ботам кому угодно, независимо от устройства и наличия учётной записи Copilot Pro. 
Источник изображения: unsplash.com Недавняя утечка некоторых рекламных материалов от Samsung указывает на то, что в ближайшее время будет представлено ещё больше новых функций Copilot, включая улучшенную интеграцию с приложением Microsoft Phone Link на смартфонах Samsung Galaxy. Новая статья: ИИтоги февраля 2024 г.: дипфейки, ханжество и трансформеры
12.03.2024 [00:03],
3DNews Team
|
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться