|
Опрос
|
реклама
Быстрый переход
OpenAI для обучения GPT-4 расшифровала миллионы видео с YouTube — текстов в интернете не хватило. Google тоже так делает
09.04.2024 [00:00],
Владимир Чижевский
Несколько дней назад сообщалось, что разработчики ИИ столкнулись с нехваткой данных для обучения передовых моделей, в том числе о планах Open AI обучать GPT-5 на видео с YouTube. Согласно материалу The New York Times, в погоне за новыми данными корпорации забывают об этике и морали. 
Источник изображения: freepik.com К концу 2021 года OpenAI столкнулась с нехваткой авторитетных англоязычных текстов в интернете для обучения новейшей модели искусственного интеллекта — ей требовалось гораздо больше данных. Тогда разработчики OpenAI создали расшифровывающую аудиозаписи из видеороликов на YouTube систему распознавания речи Whisper, которая выдаёт текст для обучения ИИ. По словам нескольких сотрудников, в компании понимали, что такой шаг может противоречить правилам использования YouTube, запрещающим использовать видеоролики «независимо» от платформы. Это не остановило OpenAI, расшифровавшую более миллиона часов видеороликов с YouTube. Полученный текст использовался для обучения GPT-4 — одной из мощнейших систем искусственного интеллекта в основе последней версии ChatGPT. В исследовании The New York Times говорится, что в гонку за данными включились все передовые разработчики ИИ, включая OpenAI, Google и Meta✴, причём компании зачастую игнорируют корпоративные политики, а иногда и закон. 
Джаред Каплан. Источник: physics-astronomy.jhu.edu В январе 2020 года физик-теоретик из Университета Джонса Хопкинса Джаред Каплан (Jared Kaplan) опубликовал работу об ИИ, которая разожгла аппетиты их разработчиков. Он высказался однозначно: чем больше данных используется для обучения языковой модели, тем лучше она работает, подобно тому, как студенты получают всё больше знаний из прочитанных книг. Языковые модели могут устанавливать закономерности и взаимосвязи, что позволяет точнее обрабатывать новую информацию. 
Сэм Альтман. Источник изображения: wikipedia.org Позднее Сэм Альтман (Sam Altman) из OpenAI заявил, что данные рано или поздно кончатся — он знает, о чём говорит, ведь компания годами собирала данные, обрабатывала и обучали на них ИИ. Среди использованных данных был программный код с GitHub, базы данных шахматных ходов, школьные тесты и домашние задания старшеклассников. К концу 2021 года они закончились. Помимо расшифровки аудио- и видеоматериалов, рассматривалась покупка компаний, имеющих доступ к огромным объёмам цифровых данных. 
Марк Цукерберг. Источник изображения: профиль в Facebook✴ Глава Meta✴ Марк Цукерберг (Mark Zuckerberg) годами развивал ИИ-направление, но выход ChatGPT в конце 2022 года оставил его компанию далеко позади. Трое бывших и нынешних сотрудников Meta✴ рассказали, что стремясь догнать OpenAI, он день и ночь донимал менеджеров и ведущих инженеров, чтобы те как можно скорее выпустили конкурирующий продукт. Но как и все остальные, Meta✴ упёрлась лбом в стену нехватки данных. 
Ахмад Аль-Дахле. Источник изображения: профиль на LinkedIn На одном из записанных совещаний руководства Meta✴ говорилось, что компания наняла субподрядчиков из Африки для сбора защищённых авторским правом материалов. «Мы не можем не собирать их», — сказали на одном из таких совещаний. Кроме того, подчёркивалось, что OpenAI тоже не стесняется использовать защищённые авторским правом материалы без разрешения их владельцев, и получать эти разрешения «слишком долго». Meta✴ ходатайствовала об отклонении антимонопольного иска FTC
06.04.2024 [11:17],
Павел Котов
Meta✴ попросила федеральный суд отказать в антимонопольном иске Федеральной торговой комиссии (FTC) США против компании — она утверждает, что ведомству не удалось собрать доказательства в поддержку своих обвинений. 
Источник изображения: succo / pixabay.com В поданном накануне ходатайстве о вынесении решения в порядке упрощённого производства Meta✴ утверждает, что иск следует отклонить: по версии компании, FTC не сможет доказать, что релевантный в представлении ведомства рынок действительно является таковым, или что поглощения Instagram✴ и WhatsApp нанесли ущерб потребителям. У FTC будет время подать отзыв на это заявление — стороны обменяются рядом документов, прежде чем судья решит, как действовать дальше. Решение в пользу Meta✴ будет означать окончание судебного процесса, но если суд постановит, что ещё остались неразрешенные фактические вопросы, может быть назначена дата разбирательства. В 2021 году судья округа Колумбия Джеймс Боусберг (James Boasberg) удовлетворил прошение Meta✴ (тогда Facebook✴) об отклонении иска, но дал FTC возможность подать исправленное исковое заявление, которому был дан ход. Он отметил, что в новой редакции документ «более убедителен и подробен, чем раньше», но предупредил, что ведомство «в будущем вполне может столкнуться с непростой задачей в попытках доказать свои обвинения». В своём ходатайстве Meta✴ критикует данное FTC определение рынка, характеризуя его как неоправданно узкое. Комиссия определила релевантный рынок как рынок служб персональных социальных сетей (Personal Social Networking Services — PSNS). Это сайты, на которых есть социальный граф, и пользователи могут общаться с членами семьи и друзьями на преимущественно личные темы. По версии ведомства, в него входят Facebook✴, Instagram✴, Snapchat и MeWe. «Первоначальное [исковое] заявление FTC было отклонено за отсутствием убедительного обвинения. Исправленное заявление частично повторяется, основываясь на стремлении FTC предоставить доказательства, которые подтвердят существование релевантного рынка PSNS, монопольное положение Meta✴ на этом рынке, а также вред, нанесённый конкуренции и потребителям в результате покупки Meta✴ [платформ] Instagram✴ и WhatsApp. <..> Обмен информацией между истцом и ответчиком показал, что FTC не сможет представить доказательств ни по одному из пунктов своего иска по второму разделу», — говорится в заявлении Meta✴. 
Источник изображения: Gerd Altmann / pixabay.com FTC не включила в своё определение релевантного рынка TikTok и YouTube, утверждая, что эти сервисы служат другой цели. TikTok не «движим желанием пользователей взаимодействовать с сетью из друзей и членов семьи»; а YouTube используется «в первую очередь для пассивного потребления определённого медиаконтента (например, видеороликов и музыки) от и для широкой аудитории обычно неизвестных пользователей». Сторона Meta✴ считает, что это неправильно, и обращает внимание суда на механизмы распространения контента в Instagram✴, TikTok и YouTube. «FTC утверждает, что 100 % времени, потраченного на Reels, приходятся на PSNS, включая просмотр роликов, опубликованных знаменитостями, блогерами и публичными страницами без связи со зрителем. Далее FTC утверждает, что 100 % времени, потраченного на просмотр идентичных коротких видеороликов на TikTok и восьми роликов на YouTube Shorts — вне зависимости от того, опубликованы они людьми, которых пользователь действительно знает, или нет — к PSNS не относятся», — рассуждает Meta✴. По версии компании, ведомство «должно доказать, что её рынок — кандидат включает в себя все разумные альтернативы». Не имеет значения, существуют ли различия между сервисами, пока «потребители считают их приемлемыми альтернативами, несмотря на такие различия». Релевантный рынок, уверены в Meta✴, должен включать YouTube и TikTok, а значит, FTC не имеет оснований обвинять компанию в его монополизации — обычно для этого нужна доля как минимум в 60 % рынка. FTC, считают в компании, также не сможет доказать, что поглощения Instagram✴ и WhatsApp нанесли вред потребителям. Комиссия сама разрешила покупку около десяти лет назад, хотя технически антимонопольные органы могут оспаривать слияния в любой момент по своему усмотрению. Иск FTC по этому делу знаменует «первую попытку пересмотреть поглощения, изученные и одобренные FTC более десяти лет назад» — такой шаг, говорят в Meta✴, «сам по себе угрожает полезной конкуренции и не имеет оснований». Более того, выдача «разрешения FTC на эти поглощения должна создавать презумпцию того, что они не были антиконкурентными, и у FTC нет доказательств для его отзыва». «За десять или более лет с момента приобретения Instagram✴ и WhatsApp принесли чрезвычайное благо потребителям — большим ростом бесплатных сервисов, их существенным улучшением и постоянным инновациям в функциональности», — напомнили в Meta✴. Компания считает, что невозможно оценить, какими бы сейчас стали эти сервисы, если бы поглощений не было, но она вложила в развитие приложений миллиарды и даже отменила плату для пользователей WhatsApp. Meta✴ предупреждает, что оспаривание поглощения может быть опасным для инновационного развития сервисов. «Решение вернуться к заключённым сделкам равносильно утверждению, что ни одна продажа никогда не будет окончательной», — заключили в Meta✴. Отзыв на ходатайство компании FTC может подать до 24 мая. Instagram✴ зарабатывает на рекламе больше YouTube — тенденция сохраняется уже несколько лет
06.04.2024 [10:05],
Владимир Фетисов
На этой неделе компания Meta✴ Platforms обратилась в федеральный суд с ходатайством с просьбой отклонить антимонопольный иск Федеральной торговой комиссии (FTC) США. В переданных суду документах содержится подробная информация о рекламных доходах Instagram✴ за последние годы. Оказалось, что по этому показателю социальная сеть обгоняет YouTube. 
Источник изображения: StartupStockPhotos / Pixabay В 2021 году реклама принесла Instagram✴ $32,4 млрд, тогда как доход YouTube за аналогичный период составил $28,8 млрд. По данным источника, такая тенденция обусловлена тем, что YouTube отдаёт 55 % с каждого рекламного доллара владельцам контента, загружающим ролики на платформу. В это же время Instagram✴ платит авторам контента значительно меньше. Аналогичным образом выглядит ситуация за более ранний период. В 2020 и 2019 года Meta✴ оценивала рекламный доход Instagram✴ в $22 млрд и $17,9 млрд соответственно, тогда как доход YouTube за те же годы составил $19,7 млрд и $15,1 млрд. По данным издания Bloomberg, доля доходов Meta✴ от Instagram✴ подскочила с 26 % в 2020 году до почти 30 % за первые шесть месяцев 2022 года. Документы, которые Meta✴ направила в суд, дают больше информации о доходах компании, чем регулярно публикуемая финансовая отчётность. В частности, они дают понять, насколько важным сегментом бизнеса компании является Instagram✴. Meta✴ начнёт маркировать сгенерированный ИИ контент
05.04.2024 [20:47],
Владимир Чижевский
С мая 2024 года компания Meta✴ введёт специальную метку для контента, сгенерированного искусственным интеллектом. Эта политика распространится на Instagram✴, Facebook✴ и Threads. 
Источник изображения: khunkorn / vecteezy.com По словам Meta✴, пометку «сделано с помощью ИИ» будут ставить как пользователи, так и сама компания, обнаружив «характерные для отрасли признаки ИИ-изображений». До этого правила Meta✴ относились лишь к видеороликам, в которых при помощи ИИ отображались люди, делающие то, чего на самом деле не было — и явно их запрещали. С момента их введения прошло четыре года, и с тех пор появилось множество других видов контента, помимо дипфейков. Опасаясь обвинений в ограничении свободы слова, Meta✴ решила не прибегать к запретительным мерам, а ограничиться маркировкой соответствующего контента. Компания уже автоматически проставляет уведомление «Imagined with AI» на созданных Meta✴ AI фотореалистичных изображениях. В будущем будет помечаться также аудио- и видеоконтент. ИИ Meta✴ оказался неспособен рисовать азиатов вместе с представителями других рас
04.04.2024 [18:28],
Павел Котов
Разработанный Meta✴ генератор изображений на основе искусственного интеллекта вслед за Google Gemini продемонстрировал неожиданное отношение к расовому вопросу. Созданная гигантом соцсетей система оказалась почти неспособной изображать азиатов совместно с представителями других рас, обратила внимание журналистка The Verge Миа Сато (Mia Sato), которая сама является азиаткой. 
Источник изображений: Meta✴ Она несколько десятков раз обращалась к созданному Meta✴ ИИ-генератору изображений, используя такие запросы как «мужчина-азиат и друг-европеец», «муж-азиат и жена с европейскими чертами лица», «азиатская женщина и муж-европеец». И лишь однажды система смогла точно изобразить предложенных ей представителей рас. Вариации запросов ситуацию не спасли. Команда «азиатский мужчина и белая женщина, улыбающиеся с собакой» привела к появлению трёх подряд изображений двух людей азиатской расы. Замена слова «белая» на «европейка» дала тот же результат. По запросу «мужчина-азиат и женщина-европейка в день свадьбы» ИИ предложил изображение мужчины-азиата в костюме и женщины-азиатки в традиционной одежде — причём это было нечто среднее между китайским платьем ципао и японским кимоно. 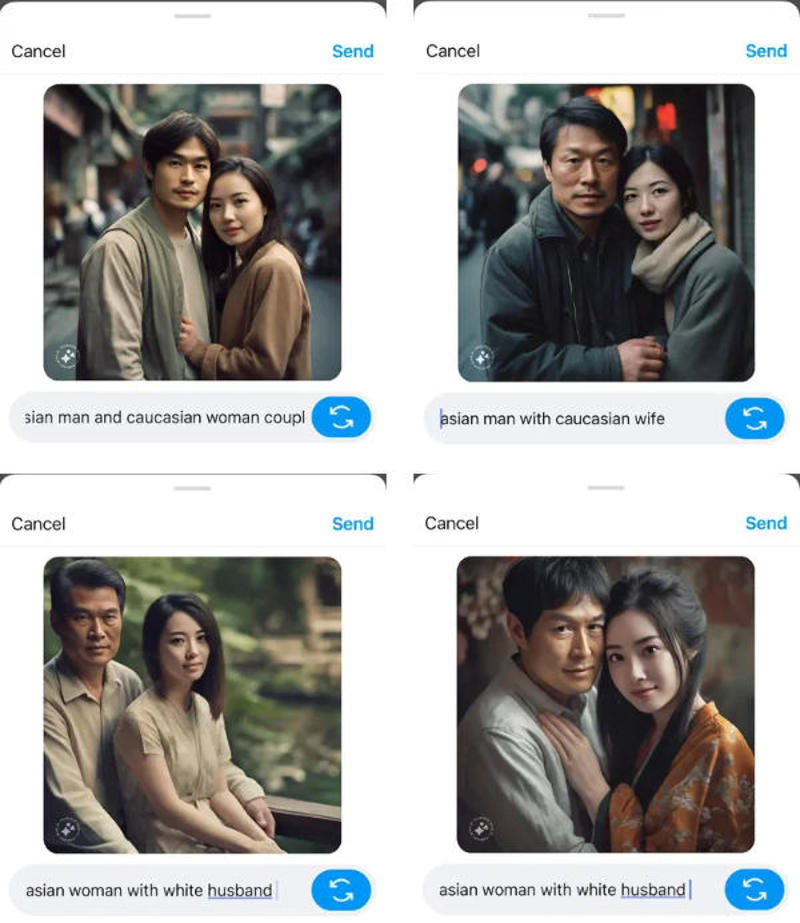 Перемены не наступили и с переходом в плоскость платонических отношений. По запросам «азиатский мужчина с европейским другом» и «азиатская женщина и белая подруга» генератор изображений Meta✴ снова предложил одних азиатов. Двух азиатских женщин система предложила и по запросу «азиатская женщина с темнокожей подругой». Адекватный ответ появился лишь по запросу «женщина-азиатка с подругой-афроамериканкой». Не очень помогла и смена региона. По запросу «мужчина из Южной Азии с женой-европейкой» ИИ сначала представил корректное изображение, но за ним по тому же запросу последовала картинка с двумя представителями Южной Азии. Причём система обращался к стереотипам, украшая южноазиатских женщин бинди (красными точками на лбу) и сари (традиционной в Индии женской одеждой). 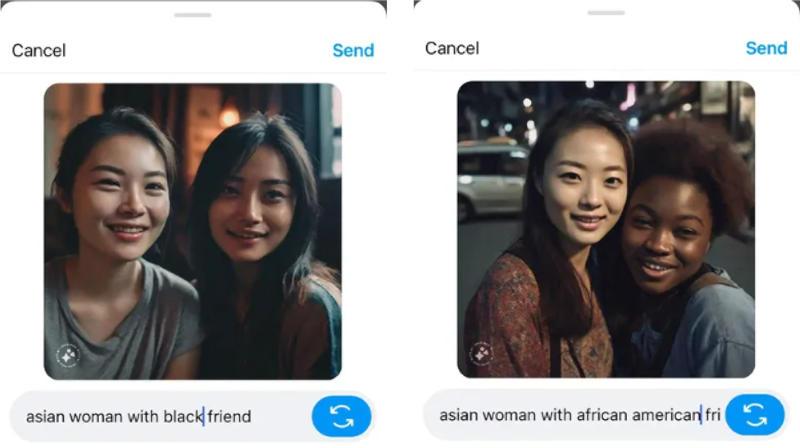
Только одна попытка изобразить азиатку с подругой-афроамериканкой увенчалась успехом Стоит отметить, что под «азиатскими женщинами» ИИ Meta✴ понимает образы светлокожих женщин из Восточной Азии, хотя самой густонаселённой страной в Азии является Индия. Причём азиатские мужчины, принадлежащие, по мнению генератора изображений, к той же этнической группе, иногда оказываются пожилыми, зато женщины всегда изображаются молодыми. Meta✴ комментариев по данному вопросу пока не предоставила. К слову, жена главы компании Марка Цукерберга (Mark Zuckerberg), представителя европейской расы, — Присцила Чан (Priscilla Chan), по происхождению является китаянкой. У мобильной версии Facebook✴ появится новый видеопроигрыватель в стиле TikTok
04.04.2024 [06:34],
Владимир Фетисов
Разработчики из Meta✴ Platforms анонсировали появление обновлённого видеопроигрывателя в мобильных приложениях Facebook✴. С его помощью пользователям социальной сети будет комфортнее просматривать вертикальные видео, подобные тем, что публикуются в TikTok или Reels. 
Источник изображения: Meta✴ Новый проигрыватель по умолчанию будет воспроизводить контент из Reels, Facebook✴ Live, а также длинные видео в полноэкранном портретном режиме. На начальном этапе распространения этого нововведения плеер станет доступен пользователям iOS-версии приложения Facebook✴ в США и Канаде. Более широкого распространения функции следует ожидать в течение следующих нескольких месяцев. Ранее в Facebook✴ использовались разные форматы при воспроизведении видео. Например, пользователи могли просматривать длинные ролики в портретной ориентации, тогда как некоторые видео воспроизводились непосредственно в ленте Facebook✴. Обновлённый плеер будет автоматически ориентироваться на вертикальные видео, но также позволит воспроизводить в портретной ориентации большинство горизонтальных роликов. Достаточно просто повернуть телефон, чтобы плеер переключился на воспроизведение контента в режиме портретной ориентации. Отметим также, что новый проигрыватель Facebook✴ претерпел некоторые визуальные изменения. В нижней части плеера появился ползунок, с помощью которого можно быстро переходить к просмотру разных частей видео. Новые элементы управления также позволят ставить воспроизведение на паузу и возвращаться к уже просмотренным фрагментам. В работе WhatsApp произошёл масштабный сбой — некоторые пользователи не могут даже войти в приложение
03.04.2024 [22:18],
Владимир Чижевский
Насчитывающий два миллиарда пользователей по всему миру сервис мгновенного обмена сообщениями WhatsApp столкнулся с глобальным сбоем. Проблемы с отправкой и получением сообщений начались около 9 часов вечера по Москве. Многие пользователи не могут даже подключиться к сервису. 
Источник изображения: Alexander Shatov / unsplash.com У WhatsApp нет специальной страницы, где можно проверить работоспособность мессенджера. Приложение позволяет отправлять сообщения, но они не будут доставлены адресатам, пока сервис не восстановит работу. О проблемах сообщают пользователи из разных уголков мире, включая США, Европу и Россию. На этом фоне Роскомнадзор оперативно сообщил РБК, что не блокирует работу WhatsApp на территории России. 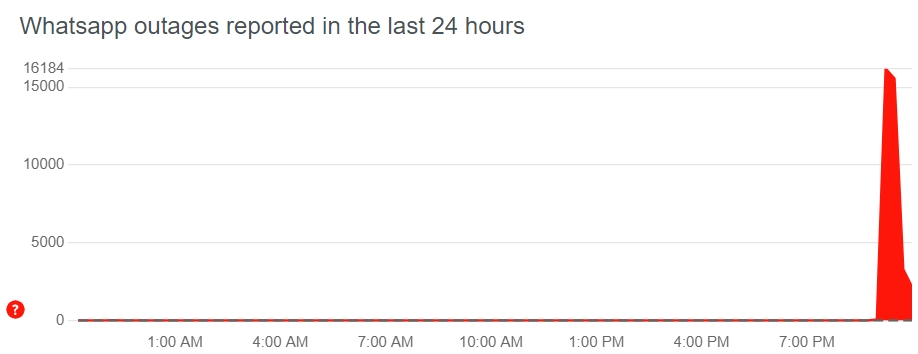 Судя по страницам поддержки других сервисов Meta✴, среди которых Facebook✴, Instagram✴ и Threads, они работают в штатном режиме. Однако многие пользователи этих служб из разных стран также сообщают о трудностях при попытках просмотра недавних сообщений и создания постов. Всего несколько недель назад случился масштабный двухчасовой сбой в работе сервисов Meta✴, который затронул Facebook✴, Instagram✴, Messenger и Threads, но WhatsApp продолжал работать как ни в чём не бывало. Теперь, похоже, настала очередь мессенджера. Facebook✴ открывала Netflix доступ к личным перепискам пользователей
02.04.2024 [19:08],
Владимир Чижевский
Facebook✴ вновь оказалась в центре скандала, связанного с нарушениями приватности пользователей — согласно обнародованным 23 марта материалам искового заявления, компания с 2011 года, предположительно, предоставляла Netflix доступ к личным сообщениям пользователей, дабы платформа могла лучше подобрать контент.  В поданном ещё в апреле прошлого года коллективном иске от имени двух граждан США, Максимилиана Кляйна (Maximilian Klein) и Сары Граберт (Sarah Grabert), утверждается, что Netflix и Facebook✴ «заключили особое соглашение», по которому социальная сеть предоставляла платформе потокового вещания доступ к данным пользователей посредством Inbox API. В свою очередь, Netflix обязывалась каждые две недели предоставлять Facebook✴ отчёты о показанных рекомендациях и взаимодействиях пользователей с интерфейсом, что должно было помочь социальной сети в таргетировании рекламы. Утверждается, что не последнюю роль в этом сотрудничестве сыграли личные отношения соучредителя Netflix Рида Хастингса (Reed Hastings) и основателя Facebook✴ Марка Цукерберга (Mark Zuckerberg). Кроме того, Netflix тратила много средств на рекламу на платформах Meta✴. Например, к 2019 году на рекламу на Facebook✴ компания Netflix потратила 200 миллионов долларов. Владеющая Facebook✴ компания Meta✴ не в первый раз обвиняется в утечках данных пользователей. Один из крупнейших скандалов связан с британской компанией Cambridge Analytica, в распоряжении которой оказались данные 87 млн пользователей социальной сети — тогда Meta✴ согласилась выплатить истцам $725 млн. Facebook✴ ждёт пересмотр политики конфиденциальности, и отложить его не получится
30.03.2024 [12:20],
Павел Котов
Компании Meta✴ не удалось убедить федеральный апелляционный суд отложить повторный пересмотр Федеральной торговой комиссией США (FTC) условий соглашения в отношении политики конфиденциальности пользователей соцсети Facebook✴. 
Источник изображения: succo / pixabay.com Апелляционный суд округа Колумбия накануне постановил, что Meta✴ «не выполнила жёстких требований» в рамках апелляции по любому из пяти конституционных возражений. «Ни одно из них не имеет шанса на успех», — цитирует Bloomberg решение суда. Компания попыталась оспорить право FTC возобновить действие соглашения от 2020 года и частично пересмотреть его условия. Соглашение было заключено после выплаты штрафа в $5 млрд за нарушение конфиденциальности пользователей — по версии ведомства, в 2023 году Meta✴ нарушила его условия. По версии FTC, Meta✴ ввела родителей своих малолетних пользователей в заблуждение в отношении мер, предпринимаемых для защиты конфиденциальности детей. Комиссия предлагает внести поправки в соглашение с Meta✴, в том числе запретить компании использовать данные несовершеннолетних и ограничить применение технологии распознавания лиц. Meta✴ ходатайствовала о вынесении судебного запрета на эти действия ведомства, но 14 марта окружной судья Рэндольф Мосс отклонил это прошение: по его мнению, если FTC права, что компания ставит под угрозу конфиденциальность пользователей, то дальнейшие действия ведомства будут предприниматься в интересах общества. В апелляции на это решение теперь отказано. В апреле Meta✴ добавит искусственный интеллект в умные очки Ray-Ban Meta✴
28.03.2024 [19:01],
Сергей Сурабекянц
Согласно сообщению The New York Times, уже в следующем месяце Meta✴ официально внедрит искусственный интеллект в свои умные очки Ray-Ban Meta✴. Мультимодальные функции искусственного интеллекта, такие как синхронный перевод, идентификация объектов, животных и памятников, находятся в раннем доступе с декабря прошлого года. 
Источник изображений: Meta✴ Пользователи смогут активировать ИИ-помощника в умных очках при помощи фразы «Привет, Мета✴», а затем задать свой вопрос. Ответ будет получен через динамики, встроенные в оправу. Журналисты The New York Times протестировали работу искусственного интеллекта умных очков на улице, в продуктовом магазине, во время вождения автомобиля, в музеях и даже в зоопарке. По их словам, ИИ смог в основном правильно идентифицировать домашних животных и произведения искусства, хотя порой делал довольно забавные ошибки. Так, очки с трудом могли идентифицировать животных зоопарка, которые находились далеко за ограждениями. Они также не смогли идентифицировать экзотический фрукт под названием черимойя даже после нескольких попыток. По словам исследователей, очки неплохо справлялись с синхронным переводом, поддерживая английский, испанский, итальянский, французский и немецкий языки. 
Источник изображения: The New York Times Выявленные недостатки лишь подчёркивают ограничения и компромиссы при разработке подобных продуктов. Очки, вероятно, могли бы лучше идентифицировать объекты, если бы камера имела более высокое разрешение, но установка качественного объектива увеличила бы вес и размер очков. Журналисты отметили, что разговаривать с виртуальным помощником на публике  Meta✴, вероятно, продолжит совершенствовать свои умные очки с течением времени. На данный момент функции искусственного интеллекта в умных очках Ray-Ban Meta✴ доступны только через список ожидания раннего доступа для пользователей в США. Facebook✴ тайно перехватывала трафик пользователей Snapchat с помощью VPN
27.03.2024 [15:04],
Владимир Мироненко
Благодаря судебному процессу, посвящённому рассмотрению коллективного иска пользователей к Meta✴, стало известно, что Facebook✴, являющаяся её «дочкой», тайно отслеживала трафик конкурентов для его анализа и получения преимущества. Об этом сообщил ресурс TechCrunch со ссылкой на судебные документы, опубликованные федеральным судом Калифорнии. 
Источник изображения: StartupStockPhotos/Pixabay Документы демонстрируют, как Meta✴ действовала в борьбе с конкурентами, включая Snapchat, а затем Amazon и YouTube, анализируя сетевой трафик и то, как её пользователи взаимодействуют с ними. Для того, чтобы обойти шифрование, используемое приложениями, Facebook✴ разработала специальную технологию. В одном из судебных документов подробно рассказано о проекте Facebook✴ «Охотники за привидениями» (Project Ghostbusters), являющемся частью программы In-App Action Panel (IAPP), в которой использовалась техника перехвата и расшифровки зашифрованного трафика приложений от пользователей Snapchat, а затем от пользователей YouTube и Amazon. После того, как исполнительный директор Meta✴ Марк Цукерберг (Mark Zuckerberg) в электронном письме от 9 июня 2016 года потребовал от подчинённых найти новый способ получения надёжной аналитики о конкурентах в связи с их быстрым ростом, команда сервиса Onavo, приобретённого Facebook✴ в 2013 году, предложила использовать модули, которые можно устанавливать на устройства на iOS и Android, чтобы перехватывать трафик для определённых поддоменов. Это позволит «нам читать то, что в противном случае было бы зашифрованным трафиком, поэтому мы можем проконтролировать использование приложения», говорится в электронном письме от июля 2016 года. Этот подход, получивший название Man in the middle (MITM, человек посредине), также используют хакеры, перехватывая интернет-трафик, передаваемый с одного устройства на другое по Сети для того, чтобы получить доступ к данным пользователей. Однако, с учётом того, что Snapchat шифровала трафик между приложением и его серверами, этот метод оказался неэффективным. Поэтому было предложено использовать сервис Onavo, который при активации позволял перехватывать весь сетевой трафик устройства, прежде чем он будет зашифрован и отправлен через интернет. «Теперь у нас есть возможность измерять подробную активность в приложении путём анализа данных Snapchat, собранных от мотивированных участников исследовательской программы Onavo», — сообщается в ещё одном письме. Согласно судебным документам, впоследствии Facebook✴ расширила действие программы на Amazon и YouTube. В 2020 году Сара Граберт (Sarah Grabert) и Максимилиан Кляйн (Maximilian Klein) подали коллективный иск к Facebook✴ с обвинением её во лжи по поводу своей деятельности по сбору данных пользователей обманным путём для выявления конкурентов и борьбы с ними. ЕС заподозрил Apple, Google и Meta✴ в нарушении «Закона о цифровых рынках» — им грозят миллиардные штрафы
25.03.2024 [20:01],
Сергей Сурабекянц
Еврокомиссия инициировала пять расследований о соблюдении требований «Закона о цифровых рынках» (DMA) в отношении Apple, Google и Meta✴. «Мы подозреваем, что предложенные тремя компаниями решения не полностью соответствуют DMA, — заявила глава антимонопольного ведомства ЕС Маргрет Вестагер (Margrethe Vestager). — Сейчас мы будем расследовать соблюдение компаниями требований DMA, чтобы обеспечить открытые и конкурентоспособные цифровые рынки в Европе».  В соответствии с DMA, компании Apple, Meta✴ и Google входят в список семи «привратников». «Привратники» в контексте DMA — это крупные онлайн-платформы, которые являются важными посредниками между бизнес-пользователями и потребителями. Эти компании обладают рыночной капитализацией свыше €75 млрд и не менее чем 45 млн ежемесячных пользователей или 10 000 активных бизнес-пользователей. Они обладают значительной рыночной властью, что позволяет им выступать в роли частных регуляторов. DMA направлен на обеспечение конкуренции и справедливости на цифровых рынках. Еврокомиссия планирует расследовать ограничительные правила в магазинах приложений Google и Apple и предпочтение собственных сервисов в поисковой системе Google. Также будет исследован текущий экран выбора браузера Apple для iOS и «модель оплаты или согласия» Meta✴ для таргетинга рекламы. Расследования будут завершены в течение следующих 12 месяцев. Регулятор ЕС также изучает представленную Apple структуру комиссий за распространение приложений за пределами App Store и монопольную практику Amazon в виде продвижения собственных продуктов в своём магазине. Комиссия предоставила Meta✴ дополнительные шесть месяцев, чтобы обеспечить совместимость Messenger с другими службами обмена сообщениями. «Мы не убеждены, что решения Alphabet, Apple и Meta✴ соответствуют их обязательствам по созданию более справедливого и открытого цифрового пространства для европейских граждан и бизнеса, — заявил еврокомиссар Тьерри Бретон (Thierry Breton). — Если наше расследование придёт к выводу, что существует недостаточное соблюдение DMA, привратникам могут грозить крупные штрафы». Штрафы могут составить до 10 % от общего глобального оборота компании и до 20 % в случае повторных нарушений. Особо опасным рецидивистам грозят «поведенческие или структурные санкции». 
Источник изображения: Pixabay Apple подверглась резкой критике за попытки обхода DMA. Хотя компания разрешила альтернативные магазины приложений для iOS, новая структура сборов препятствует разработчикам в распространении приложений за пределами App Store. Spotify считает выбранный Apple способ соблюдения требований DMA «полным и тотальным фарсом», а генеральный директор Epic Тим Суини (Tim Sweeney) назвал поведение Apple «новым примером злонамеренного соответствия». «Мы уверены, что наш план соответствует требованиям DMA, и мы продолжим конструктивно взаимодействовать с Европейской комиссией при проведении расследований», — заявил представитель Apple. «Модель оплаты или согласия» Meta✴ также стала предметом жалоб со стороны различных наблюдателей ЕС. В прошлом году компания запустила тарифный план с отключённой рекламой для Facebook✴ и Instagram✴ в ЕС стоимостью €9,99. Тариф разработан, чтобы вынудить пользователей, не желающих платить, дать согласие на обработку их персональных данных. По мнению Meta✴, «подписка как альтернатива рекламе — это хорошо зарекомендовавшая себя бизнес-модель во многих отраслях». Еврокомиссия обеспокоена подобным «бинарным выбором». Сейчас Meta✴ предлагает снизить ежемесячную плату за подписку без рекламы до €5,99 в месяц, но далеко не факт, что это предложение устроит Еврокомиссию. «Чтобы соответствовать “Закону о цифровых рынках”, мы внесли существенные изменения в то, как наши услуги работают в Европе, — заявил представитель Google. — Компания взаимодействовала с Европейской комиссией, заинтересованными сторонами и третьими сторонами в десятках событий за последний год, чтобы получать отзывы и отвечать на них». Amazon сообщила, что политика компании полностью соответствует требованиям DMA. Компания планирует «усердно работать каждый день, чтобы соответствовать всем высоким стандартам наших клиентов в меняющейся нормативно-правовой среде Европы». В серии заявлений Apple, Meta✴, Google и Amazon сообщили о намерении твёрдо отстаивать свои подходы к соблюдению DMA и продолжить консультации с Еврокомиссией. Meta✴ скоро добавит в Threads возможность публиковать контент сразу на нескольких платформах
20.03.2024 [13:51],
Дмитрий Федоров
На мероприятии FediForum компания Meta✴ продемонстрировала возможность интеграции платформы микроблогов Threads с семейством децентрализованных соцсетей Fediverse через протокол ActivityPub. Этот шаг позволит пользователям Threads публиковать контент одновременно на нескольких платформах, не ограничиваясь одним сервисом. 
Источник изображения: Threads В рамках FediForum Питер Коттл (Peter Cottle), разработчик из компании Meta✴, продемонстрировал процесс интеграции аккаунтов Threads с Fediverse. В ходе демонстрации была показана функция Fediverse sharing, доступная в настройках аккаунта Threads. После её активации пользователю предоставляется пять минут для редактирования или отмены публикации, что даёт возможность проверки контента перед его размещением в Fediverse. Однако Meta✴ предупреждает о потенциальных ограничениях: невозможности гарантировать удаление публикации на всех связанных платформах. Этот аспект подчёркивает важность осознанного отношения пользователей к распространению своего контента в децентрализованной сети, где управление данными осуществляется по иным правилам. В ответ на скептицизм сообщества по поводу интеграции Threads с Fediverse Коттл выразил уверенность в благих намерениях Meta✴. Он подчеркнул желание корпорации стать ценным участником Fediverse, вносящим свой вклад в развитие децентрализованной экосистемы: «Я хочу сказать, что, как мне кажется, у всех членов команды очень хорошие намерения. Мы действительно хотим быть хорошим членом сообщества и дать людям возможность узнать, что такое Fediverse». FediForum, будучи открытой площадкой для обмена опытом и идеями между разработчиками, играет ключевую роль в развитии сообщества Fediverse. Организаторы мероприятия подчёркивают значение открытости в процессе создания и развития технологий, способствующих укреплению децентрализованных сетей. Умные очки Ray-Ban Meta✴ научились распознавать и описывать достопримечательности
12.03.2024 [10:54],
Павел Котов
В конце прошлого года умные очки Ray-Ban Meta✴ получили функцию визуального поиска на основе искусственного интеллекта, а теперь разработчик добавил ещё одну ИИ-функцию, пока в формате бета-версии. Устройство научили распознавать достопримечательности и рассказывать о них, выступая своего рода гидом для туристов. 
Источник изображения: Andrew Bosworth Технический директор Meta✴ Эндрю Босворт (Andrew Bosworth) показал, как работает новая функция. Система рассказала о таких достопримечательностях Сан-Франциско как мост «Золотые ворота», архитектурный ансамбль «Разукрашенные леди» и башня Койт — всё в формате подписей к изображениям. Глава компании Марк Цукерберг (Mark Zuckerberg) продемонстрировал ту же функцию с голосовыми пояснениями системы о достопримечательностях в штате Монтана, а также о том, как образуется снег. Функция визуального поиска в умных очках Ray-Ban Meta✴ работает аналогично технологии Google Lens: пользователи «показывают», что они видят, и задают вопросы об этом ИИ. Система производит поиск в реальном времени при помощи Bing Search. Пока новинка работает у ограниченного числа пользователей — участников программы раннего доступа. Владельцы устройства в США могут записаться в лист ожидания на сайте продукта, указав серийный номер своих умных очков. Компания «работает над тем, чтобы сделать её доступной для большего числа людей», — заверил Эндрю Босворт. Signal и Threema отказались добавлять совместимость с WhatsApp
11.03.2024 [18:05],
Владимир Чижевский
В соответствии с «Законом о цифровых рынках» (Digital Markets Act, DMA), компания Meta✴ должна обеспечить своим сервисам WhatsApp и Facebook✴ Messenger возможность обмениваться сообщениями со сторонними мессенджерами. Однако представители ориентированных на приватность платформ обмена сообщениями Signal и Threema заявили, что не заинтересованы в этом.  Хотя совместимость с WhatsApp позволила бы Signal и Threema заметно расширить аудиторию, обе компании отказываются развивать это направление. «Мы не собираемся снижать наши высочайшие стандарты конфиденциальности — напротив, мы заинтересованы в их улучшении. Работа с Facebook✴ Messenger, iMessage, WhatsApp или даже Matrix привела бы к ухудшению защиты данных», — сказала президент Signal Мередит Уиттакер (Meredith Whittaker). Согласен с ней и представитель Threema: «Основная проблема в том, что у нас другие стандарты конфиденциальности и безопасности данных. Мы не можем и не станем отступать от них — это основа идеологии Threema». Несмотря на то, что WhatsApp поддерживает сквозное шифрование по применяемому в Signal и Threema протоколу Signal, у него нет продвинутой защиты метаданных, указывающих, кто, когда и кому отправлял сообщения. Обе компании подчёркивают, что закрытость кода WhatsApp не позволяет установить, как именно обрабатываются данные пользователей. Помимо этого, заинтересованным в сотрудничестве с WhatsApp компаниям придётся подписать соглашение, по которому они обязуются применять те же стандарты сквозного шифрования, что дополнительно снижает привлекательность подобного сотрудничества. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться