
Опрос
|
реклама
Быстрый переход
По итогам нового раунда финансирования капитализация OpenAI выросла до $852 млрд
01.04.2026 [04:41],
Алексей Разин
Похоже, идеологическая задача достичь капитализации свыше $1 трлн по итогам IPO для OpenAI становится всё более доступной, поскольку ещё на этапе частного финансирования стартап смог выйти на оценку в $852 млрд и превысить собственные ожидания. Недавно компания привлекла $122 млрд вместо запланированных $110 млрд. 
Источник изображения: Unsplash, Levart_Photographer Свежий раунд финансирования был анонсирован в феврале, ориентиром служила сумма $110 млрд, но к концу марта OpenAI смогла привлечь от инвесторов $122 млрд, как поясняет CNBC. Это позволяет оценить текущую капитализацию стартапа в $852 млрд. Основную часть нового транша обеспечили институциональные инвесторы во главе с SoftBank. В своём пресс-релизе по поводу завершения нового раунда финансирования OpenAI заявила: «ИИ влечёт рост производительности, ускоряет научные открытия и расширяет возможности людей и организаций. Эти средства обеспечивают нас ресурсами, позволяющими сохранить лидерство в том масштабе, которого требует момент». В последнее время OpenAI пришлось отказаться от некоторых направлений развития ради концентрации на главных и потенциально наиболее выгодных. В частности, от поддержки генератора видео Sora компания отказалась весьма неожиданно, но именно финансовые соображения легли в основу этого непростого решения. Кроме того, OpenAI стала более вдумчиво подходить к расширению вычислительной инфраструктуры ИИ, в Техасе один из ЦОД в рамках проекта Stargate теперь будет достраивать Microsoft, а не OpenAI и Oracle. В прошлом году выручка OpenAI составила $13,1 млрд, а сейчас компания получает до $2 млрд в месяц, но говорить о выходе на прибыльность преждевременно. В новейшем раунде финансирования трио стратегических инвесторов должно было обеспечить привлечение $110 млрд, из них Amazon предоставила $50 млрд, ещё $30 млрд обеспечила SoftBank, а Nvidia ограничилась $30 млрд, которые она наверняка вернёт себе в виде оплаты за поставки ускорителей вычислений. Оставшиеся $12 млрд были предоставлены более широким кругом инвесторов, причём OpenAI впервые привлекла $3 млрд от индивидуальных инвесторов через банковские каналы. Степень участия Microsoft в этом раунде финансирования не раскрывается, но оно подтверждено самой OpenAI. Представители стартапа выразили уверенность, что «вложенные инвесторами средства со временем потекут обратно в экономику, к компаниям, сообществам и всё более активно — к частным лицам». Стала известна причина закрытия ИИ-генератора видео OpenAI Sora и она весьма прозаична
30.03.2026 [11:15],
Алексей Разин
На прошлой неделе OpenAI внезапно отказалась от поддержания ИИ-генератора видео Sora в строю, тем самым подведя студию Disney, которая успела ранее заключить договор, затрагивающий условия использования этого сервиса. Издание The Wall Street Journal со ссылкой на собственные источники сообщило, что основной причиной принятия столь серьёзного решения стала банальная нехватка ресурсов. 
Источник изображения: OpenAI Характерно, что речь идёт не только о финансовых ресурсах, хотя энергоёмкий сервис действительно требовал от OpenAI довольно высоких затрат на генерацию видео. Из этих соображений на раннем этапе популярности Sora компания даже ограничила продолжительность создаваемых одним пользователем видео десятью секундами, чтобы инфраструктура могла справляться с вычислительной нагрузкой. Монетизировать Sora в сжатые сроки не представлялось возможным, а расходов на своё развитие и эксплуатацию генератор видео по текстовому запросу требовал серьёзных. По некоторым данным, эксплуатация Sora обходилась OpenAI примерно в $1 млн в день. Популярность Sora хоть и взлетела до 1 млн пользователей на начальном этапе, в последнее время откатилась до уровня в 500 000 пользователей. При этом каждый из них отнимал у OpenAI востребованные в других проектах вычислительные ресурсы в приличном объёме. Источник подчёркивает, что внутренняя система мониторинга позволяет OpenAI отслеживать, чем заняты используемые в инфраструктуре стартапа ускорители вычислений. Команда разработчиков Sora, которая исторически обладала в стартапе определённой самостоятельностью, получила весьма солидную часть вычислительных ресурсов, что в условиях их нехватки на других направлениях вызвало вопросы у руководства OpenAI. Прилично заработать на Sora компания вряд ли могла бы, а вот тратить приходилось много. Кроме того, из-за дефицита ресурсов страдали другие направления развития, которые были признаны приоритетными. От идеи предлагать платный доступ к Sora через ChatGPT стартап в конечном итоге отказался. Внезапность решения OpenAI о закрытии проекта Sora подтверждают и представители Disney, с которой у стартапа был заключён договор на $1 млрд. Он предусматривал, что Disney вложит соответствующую сумму в капитал OpenAI и позволит пользователям Sora использовать лицензированных персонажей из множества принадлежащих студии франшиз в своём творчестве по созданию роликов с помощью ИИ. Руководство Disney об отказе OpenAI от поддержки Sora в работоспособном состоянии узнало примерно на час быстрее общественности, что нельзя считать заблаговременным предупреждением. В принципе, после смены руководства Disney сейчас ведёт переговоры более чем с 10 возможными партнёрами, которые смогут предоставить студии различные ИИ-услуги. На официальном уровне Disney выражает признательность OpenAI за полученный опыт сотрудничества и с уважением относится к принятому решению отказаться от развития Sora. Microsoft приберёт к рукам ЦОД почти на 1 ГВт в Техасе, который не осилили построить Oracle и OpenAI
28.03.2026 [07:27],
Алексей Разин
В первые дни своего второго президентского срока Дональд Трамп (Donald Trump) принял участие в торжественной церемонии запуска проекта Stargate, который был призван за четыре года направить на строительство инфраструктуры ИИ в США до $500 млрд. Недавно стало известно, что от возведения части объектов в Техасе компании OpenAI и Oracle были вынуждены отказаться, но их место заняла Microsoft. 
Источник изображения: Oracle Ещё в начале марта стало известно, что флагманский ЦОД проекта в техасском Абилине будет построен в меньших масштабах, чем планировалось изначально, поскольку OpenAI и Oracle стали более трезво оценивать свои силы. Фактически, бурное развитие американской инфраструктуры вычислительных центров для ИИ в последние пару лет осуществляется на голословной уверенности руководства OpenAI в востребованности данных мощностей, но платить за это приходится партнёрам компании, среди которых в первых рядах стоят Oracle и SoftBank. Финансовые возможности последних не безграничны, они уже начали залезать в многомиллиардные долги, и вполне естественно, что от части проектов в сфере ИИ они вынуждены отказываться. Изначально считалось, что часть мощностей на техасской площадке за Oracle достроит Meta✴✴ Platforms, но теперь Bloomberg сообщает, что реализацией этой части проекта займётся корпорация Microsoft, которая является крупнейшим инвестором и давним партнёром OpenAI, которая как раз и способствует продвижению инициативы Stargate. К середине следующего года на указанной площадке в Техасе уже будет возведено и подключено к электросетям первое здание, а в перспективе здесь могут расположиться вычислительные системы совокупной мощностью до 900 МВт. Microsoft согласилась взять в аренду данный центр обработки данных. SoftBank одолжила $40 млрд на год, чтобы инвестировать их в OpenAI
27.03.2026 [22:43],
Анжелла Марина
Японская транснациональная холдинговая компания SoftBank Group — один из крупнейших в мире инвесторов в технологическом секторе — в пятницу объявила о привлечении промежуточного кредита на $40 млрд. Кредит предназначен для усиления инвестиций в компанию OpenAI, а также для общих корпоративных целей. 
Источник изображения: xAI Кредит, срок погашения которого наступает в марте 2027 года, является необеспеченным и был организован при участии в том числе JPMorgan Chase, Goldman Sachs, Mizuho Bank, Sumitomo Mitsui Banking Corp и MUFG Bank, сообщает Reuters. Ранее SoftBank уже договорился о вложении $30 млрд в разработчика ChatGPT через свой фонд Vision Fund 2. Данные шаги происходят на фоне растущего спроса на технологии генеративного искусственного интеллекта, где ключевую роль играет поддерживаемая Microsoft компания OpenAI. Одновременно кредитная сделка подчёркивает всё более агрессивную ставку на ИИ основателя SoftBank Масаёси Сона (Masayoshi Son), который в последние годы пережил периоды как рекордной прибыли, так и значительных убытков Vision Fund. Напомним, SoftBank и OpenAI совместно участвовали в прошлогоднем проекте Stargate, в рамках которого планируется инвестировать до $500 млрд в течение четырёх лет в создание инфраструктуры искусственного интеллекта на территории Соединённых Штатов. В декабре 2024 года Масаёси Сон и избранный на тот момент президент США Дональд Трамп (Donald Trump) анонсировали планы SoftBank по инвестированию $100 млрд в американские проекты в сфере ИИ и связанную с этой технологией инфраструктуру в США также в течение четырёх лет. OpenAI опробовала рекламу в ChatGPT — она уже может приносить более $100 млн в год
27.03.2026 [07:03],
Алексей Разин
Исчерпав возможности привлечения капитала в прежних объёмах, OpenAI начинает формировать более благопристойное впечатление о себе в глазах инвесторов. В поисках путей монетизации своих услуг, стартап пару месяцев назад запустил в США пилотный проект по демонстрации рекламы пользователям. Представители OpenAI говорят, что в годовом выражении выручка компании от рекламы уже может превышать $100 млн. 
Источник изображения: OpenAI Ещё в январе OpenAI начала демонстрировать рекламу подписчикам тарифа ChatGPT Go и пользователям бесплатного варианта этого чат-бота. По словам представителей OpenAI, на которые ссылается CNBC, компания работает с более чем 600 рекламодателями, не наблюдая каких-либо проблем, касающихся конфиденциальности передаваемых им данных о привычках и предпочтениях пользователей. Сейчас OpenAI рассматривает идею начала демонстрации рекламы пользователям ChatGPT в Австралии, Канаде и Новой Зеландии. Демонстрацию рекламы даже в подходящих для этого тарифах подписки OpenAI ограничивает определёнными правилами. Пользователям младше 18 лет она не демонстрируется, прочие видят её под ответом чат-бота с явной маркировкой. При обсуждении ряда тем типа политики и здоровья, включая ментальное, реклама также не демонстрируется в ChatGPT. На содержание ответа чат-бота реклама тоже не влияет, по словам представителей OpenAI. В США около 85 % пользователей бесплатного тарифа ChatGPT и версии Go являются аудиторией, которой демонстрируется реклама, но на ежедневной основе не более 20 % пользователей её просматривают. Медленное развёртывание рекламного бизнеса OpenAI в компании объясняют необходимостью тщательной проработки всех деталей. Как отмечают в OpenAI, «ранние сигналы от пользователей и участвующих брендов воодушевляют нас, мы продолжаем видеть сильную заинтересованность со стороны рекламодателей». OpenAI передумала развращать ChatGPT — проект ИИ-бота для взрослых отправили «в долгий ящик»
26.03.2026 [16:51],
Алексей Разин
Усилия руководства OpenAI по оптимизации бизнес-стратегии начинают определять те приоритетные направления развития стартапа, которые достойны запланированных многомиллиардных инвестиций. Вслед за неожиданным отказом от поддержки ИИ-генератора видео Sora, как отмечает Financial Times, компания решила отложить в «долгий ящик» и проект эротического чат-бота. 
Источник изображения: Unsplash, Brian Lawson Прошлая публикация на эту тему позволяет понять, что темой запуска эротических ИИ-сервисов OpenAI интересуется уже на протяжении нескольких лет, и после длительных колебаний воплотить эти планы в жизнь сперва было решено до конца первого квартала текущего года, но недавно стало известно, что в этой сфере возникает задержка как минимум на месяц. Теперь Financial Times со ссылкой на осведомлённые источники заявляет, что проект эротической направленности отложен в «долгий ящик» на неопределённое время, поскольку инвесторы и сами сотрудники OpenAI выражают глубокую озабоченность его вероятными социальными и экономическими последствиями. Внутри стартапа даже высказываются мнения о необходимости полностью отказаться от идеи запуска эротического чат-бота. Растёт беспокойство связанных с OpenAI лиц по поводу усиления нездоровой атмосферы вокруг чат-бота, а также последствий получения доступа к взрослому контенту со стороны несовершеннолетних пользователей. Представители OpenAI в комментариях Financial Times подтвердили, что эротическая ИИ-модель отложена по срокам реализации на неопределённое время. Прежде чем принять какие-то решения о жизнеспособности проекта, OpenAI хочет провести глубокое исследование по поводу его возможного влияния на общество. Каких-либо эмпирических данных на этот счёт до сих пор не существует, поэтому к изучению проблемы важно подойти досконально. Кроме того, распылять ресурсы на второстепенные инициативы OpenAI сейчас не желает, предпочитая сосредоточиться на разработке ИИ-инструментов для повышения производительности умственного труда и их монетизации. По некоторым данным, самые востребованные свои инструменты создатели ChatGPT намерены объединить в мощном настольном приложении. Выпуск платформы с эротическим уклоном мог бы вызвать неоднозначную реакцию аудитории в ближайшее время, поскольку на фоне скандала с «раздевающим» людей чат-ботом Grok компании xAI внимание регуляторов к этой теме резко возросло. Выход апеллирующего к теме эротики ИИ-решения OpenAI мог бы насторожить инвесторов с учётом планируемого IPO компании. Тем более, что перспективы серьёзной монетизации такого продукта многим из них тоже кажутся сомнительными. Наконец, создание такого продукта могло бы натолкнуться на чисто технические трудности. Годами ChatGPT развивался с учётом определённых этических ограничений, а для реализации «эротического проекта» их пришлось бы выборочно снимать, причём с сохранением категорической блокировки некоторых табуируемых в обществе тем. Сохранить оптимальный баланс между жизнеспособностью такой модели и её безопасностью было бы крайне сложно. Недавно модернизированная система верификации возраста пользователей по-прежнему даёт сбой в более чем 10 % случаев. Это означает, что миллионы несовершеннолетних могли бы получить доступ к контенту для взрослых, и подобные факты повлекли бы серьёзные юридические риски для OpenAI. Закрытие OpenAI ИИ-генератора видео Sora обрушило миллиардную сделку с Walt Disney
26.03.2026 [09:49],
Владимир Мироненко
В связи с закрытием OpenAI приложения для создания видео на основе искусственного интеллекта Sora компания Walt Disney, по данным The Hollywood Reporter, отказалась от сделки с OpenAI стоимостью около $1 млрд. 
Источник изображения: Héctor Vásquez/unsplash.com «Поскольку зарождающаяся область искусственного интеллекта быстро развивается, мы уважаем решение OpenAI выйти из бизнеса по созданию видеороликов и переориентировать свои приоритеты на другие направления, — говорится в заявлении Disney, предоставленном СМИ. — Мы ценим конструктивное сотрудничество между нашими командами и то, чему мы научились благодаря ему, и мы продолжим взаимодействовать с платформами ИИ, чтобы находить новые способы взаимодействия с фанатами там, где они находятся, ответственно внедряя новые технологии, которые уважают интеллектуальную собственность и права создателей». В декабре Disney и OpenAI объявили о заключении трёхлетнего лицензионного соглашения, согласно которому более 200 персонажей, принадлежащих Disney, были бы доступны для использования в видеороликах, созданных с помощью приложения Sora. В рамках соглашения Disney обязалась инвестировать в ИИ-стартап $1 млрд. Хотя это соглашение представлялось практически свершившимся фактом, OpenAI указала тогда в заявлении, что оно «зависит от переговоров по окончательным соглашениям, необходимых корпоративных и советов директоров одобрений, а также стандартных условий закрытия сделки». Как сообщает Axios со ссылкой на источник, знакомый с ситуацией, деньги в рамках объявленной сделки так и не были перечислены. Ресурс Financial Times отметил, что сделка так и не состоялась, поскольку OpenAI изменила свою стратегическую направленность. Вместе с тем агентство Reuters утверждает, что Disney и OpenAI всё ещё обсуждают, есть ли другой способ сотрудничества или инвестирования между компаниями. Всё на нужды ИИ: OpenAI привлечёт ещё $10 млрд от мелких инвесторов
25.03.2026 [13:40],
Алексей Разин
Основную часть средств, необходимых OpenAI на развитие вычислительной инфраструктуры и обучение новых языковых моделей в краткосрочной перспективе, стартап недавно привлёк благодаря участию Amazon, Nvidia и SoftBank. Оставшиеся $10 млрд из $120 млрд, которые планируется привлечь в рамках текущего раунда, OpenAI получит от ряда более мелких институциональных инвесторов. 
Источник изображения: OpenAI Уточнение на этот счёт решило сделать агентство Bloomberg со ссылкой на CNBC. В своём интервью телеканалу финансовый директор OpenAI Сара Фрайар (Sarah Friar) пояснила, что стартап собирается привлечь к этой части раунда финансирования группу институциональных инвесторов во главе с Andreessen Horowitz, MGX из Абу-Даби, D.E. Shaw Ventures, TPG и T. Rowe Price. Сбор средств в размере $10 млрд планируется завершить на следующей неделе. Если учесть, что стратегические инвесторы в лице Amazon, Nvidia и SoftBank предоставили около $110 млрд, то общая сумма привлечения превысит $120 млрд. Это поднимает капитализацию OpenAI до $850 млрд, не говоря уже о рекордном масштабе привлечения финансовых ресурсов. Одновременно вложить в капитал OpenAI свои средства готовы Coatue Management, Thrive Capital и Altimeter Capital, как сообщает Bloomberg. К ним присоединится и Microsoft — самый опытный инвестор OpenAI, поддержку которого руководство стартапа по-прежнему высоко ценит. Для сравнения, капитализация конкурирующей Anthropic оценивается в $380 млрд после того, как в прошлом месяце стартапу удалось привлечь $30 млрд. OpenAI внезапно закрыла Sora — завоевавший вирусную популярность генератор ИИ-слопа
25.03.2026 [01:28],
Анжелла Марина
Компания OpenAI неожиданно приняла решение закрыть своё приложение для создания видео на основе искусственного интеллекта Sora. Нейросеть позволяла создавать видео различной тематики практически без ограничений, что делало процесс генерации из текстовых подсказок чрезвычайно простым. Продукт был выпущен в сентябре 2025 года и стал вторым приложением OpenAI для iPhone. 
Источник изображения: xAI Как выяснило издание 9to5Mac, в отличие от чат-бота ChatGPT, Sora не удалось завоевать такую же популярность. В результате, разработчики объявили о прекращении поддержки сервиса. Изначально запуск Sora сопровождался большим ажиотажем, включало в себя инструменты для генерации видеороликов, а также ленту социальных сетей для просмотра созданного контента. Функциональность сервиса позволяла создавать с лёгкостью любые видео, однако вскоре OpenAI ввела строгие ограничения, касающиеся использования интеллектуальной собственности без разрешения правообладателей. Этот шаг фактически и уничтожил на корню интерес пользователей к приложению. OpenAI объявила о прекращении поддержки Sora в сообщении на X: «Мы прощаемся с Sora. Всем, кто создавал что-то с помощью Sora, делился этим и создавал вокруг этого сообщество — спасибо. То, что вы делали с Sora, имело значение, и мы понимаем, что эта новость вас разочаровала. Вскоре мы поделимся дополнительной информацией, включая сроки разработки приложения и API, а также подробности о сохранении ваших работ», – Команда Sora Кроме того, издание The Wall Street Journal сообщает, что OpenAI сворачивает любые усилия, связанные с разработкой ИИ-моделей для генерации видео, какого бы это направления не касалось. Этот шаг объясняется ещё и тем, что компания намерена сосредоточить своё внимание на создании суперприложения. Новый продукт должен объединить в себе возможности ChatGPT, инструменты разработки Codex и веб-браузер Atlas, который на текущий момент испытывает серьёзные трудности, касающиеся безопасности и приватности. Эксперты отмечают, что Sora всегда воспринималась скорее как демонстрационная забава, а не профессиональный инструмент. Несмотря на это, проект успел заинтересовать выдающегося американского бизнесмена Боба Айгера (Bob Iger) в контексте потенциального сотрудничества с Disney. Однако проверить жизнеспособность идеи не удалось, сделка так и не состоялась. Ставка на ИИ загоняет SoftBank всё глубже в многомиллиардную долговую яму
24.03.2026 [12:44],
Алексей Разин
Чтобы закрыть предыдущий раунд финансирования OpenAI, японская корпорация SoftBank в конце прошлого года спешно распродала часть прочих активов. Теперь она готовится заимствовать ещё $30 млрд на аналогичные цели, для чего внутренние стандарты работы с заёмными средствами будут пересмотрены. 
Источник изображения: SoftBank Как отмечает Financial Times, исторически SoftBank старалась поддерживать соотношение заёмного капитала к стоимости активов на уровне ниже 25 %, но в этом году данный порог должен быть превышен. Финансовый директор Ёсимицу Гото (Yoshimitsu Goto) заявил изданию, что в будущем этот уровень может быть на какое-то время превышен. При этом нельзя утверждать, что собственные инвесторы SoftBank спокойно смотрят на растущие долговые обязательства корпорации. По оценкам экспертов MST Financial, в течение 2026 года OpenAI и её инвесторы должны вложить в этот стартап около $50 млрд, при этом соотношение долговой нагрузки к капиталу превысит порог в 25 %, и не всем участникам рынка это может понравиться. В прошлом квартале данное соотношение в случае SoftBank уже выросло с 16,5 до 20,6 %. Курс акций компании с октября прошлого года снизился более чем на 45 % как раз из-за опасений инвесторов по поводу сроков окупаемости вложений в инфраструктуру ИИ. Сама SoftBank стремительно теряет позиции в кредитном рейтинге, что делает новые заимствования всё более сложными. Финансовый директор SoftBank подчеркнул, что корпорация при первой возможности снизит соотношение долга и стоимости активов до уровня ниже 25 %, продав активы, разместив акции на бирже или заложив их. На данный момент SoftBank уже вложила в капитал OpenAI около $34 млрд, получив 11-% долю в нём. Располагая более чем $189 млрд чистых активов, SoftBank может гибко регулировать использование заёмных средств. Даже без компенсирующих мер соотношение долга к стоимости активов достигнет лишь 26–27 %, по мнению финансового директора, а при противодействии этой тенденции показатель можно опустить ниже 25 %. Привлекать капитал на фондовом рынке становится сложно в условиях геополитической напряжённости. Сама OpenAI может вскоре выйти на IPO, и это поможет SoftBank снизить собственную долговую нагрузку. Агентство S&P ухудшило кредитный рейтинг SoftBank именно по причине увеличения доли непубличных активов в портфеле корпорации с 42 до более чем 50 %. Размещение акций OpenAI могло бы частично решить эту проблему. Впрочем, некоторые эксперты утверждают, что снижение курса акций SoftBank отражает скепсис инвесторов в отношении бизнеса OpenAI, поэтому рассчитывать на хорошие итоги IPO становится всё сложнее. На покрытие ближайших потребностей SoftBank позаимствовала у своих основных кредиторов около $40 млрд. Инвестиции в OpenAI компания осуществит в три этапа: в апреле, июле и октябре. По мнению руководства SoftBank, кредитующие компанию банки понимают и одобряют её инвестиционную стратегию, а потому продолжают выделять заёмные средства. OpenAI представила ChatGPT Library — облачное хранилище, которое доступно не всем
24.03.2026 [11:22],
Павел Котов
OpenAI представила новую функцию Library для ChatGPT — возможность держать личные файлы и изображения в облачном хранилище платформы. Воспользоваться ChatGPT Library могут подписчики версий Plus, Pro и Business; новая функция доступна пользователям по всему миру за исключением Швейцарии, Великобритании и стран Европейской экономической зоны. 
Источник изображения: Dima Solomin / unsplash.com Раздел Library уже начал появляться в боковой панели веб-версии ChatGPT — в хранилище уже помещены некоторые файлы, которые пользователи загружали ранее в чат. По умолчанию данные из переписки попадают в безопасное хранилище и могут использоваться в качестве справочных материалов в будущих чатах. Генерируемые чат-ботом изображения по-прежнему отображаются в соответствующей вкладке на боковой панели. Уже присутствующие в ChatGPT Library файлы можно быстро добавлять в чат для анализа ИИ или в качестве контекста. Есть также возможность удалять их из хранилища — для этого напротив каждого файла появляется значок с изображением корзины. Удалённые из хранилища файлы сохраняются на серверах OpenAI ещё в течение 30 дней. В компании не объяснили, почему система работает подобным образом — возможно, тому есть юридические причины. OpenAI назвала свою зависимость от Microsoft риском для инвесторов
24.03.2026 [08:10],
Алексей Разин
Прежде чем OpenAI начала активно привлекать средства стратегических инвесторов, она в этой сфере длительное время полагалась на финансовую поддержку Microsoft, которая к тому же предоставляла ей доступ к вычислительной инфраструктуре через облачный сервис Azure. В рамках сбора средств среди инвесторов свою зависимость от Microsoft компания OpenAI предпочла отнести к рискам. 
Источник изображения: Microsoft Формально OpenAI пока не начала готовиться к IPO, поэтому опубликованный ею недавно документ нельзя считать проспектом для инвесторов в привычном понимании этого термина, но ресурс CNBC сосредоточился на упоминании стартапом своей зависимости от Microsoft в качестве серьёзного риска для сторонних инвесторов. OpenAI продолжает привлекать средства на своё развитие, и она распространяет среди них документы, перечисляющие связанные со своим бизнесом факторы риска. В прошлом месяце, как поясняет CNBC, компании OpenAI удалось привлечь рекордные $110 млрд, но на этом она останавливаться не собирается, рассчитывая собрать с более широкого круга инвесторов ещё $10 млрд. Стартап признаётся, что Microsoft продолжает обеспечивать существенную долю финансирования и вычислительных мощностей OpenAI, а потому такая зависимость может считаться риском для сторонних инвесторов. Первая часть суммы в $110 млрд была собрана с трёх крупных стратегических инвесторов, коими стали Amazon, Nvidia и SoftBank. Дополнительные $10 млрд будут привлечены с использованием более обширного круга инвесторов до конца этого месяца. Помимо зависимости от Microsoft, стартап отнёс к факторам риска крупные капитальные затраты, зависимость от доступности вычислительных ресурсов, судебное разбирательство с xAI Илона Маска (Elon Musk), а также собственную нетипичную организационную структуру «корпорации общественного блага». Microsoft поддерживает OpenAI с 2019 года, хотя сам стартап был основан в 2015 году. Корпорация вложила в OpenAI не менее $13 млрд, в ходе октябрьской реструктуризации стартапа ей достались 27 % акций на сумму $135 млрд. По мнению представителей OpenAI, операционные результаты деятельности стартапа будут во многом зависеть от его способности существенно расширить взаимоотношения с прочими компаниями, помимо Microsoft. Представители OpenAI пояснили CNBC, что это стандартные формулировки, которые присутствовали на протяжении нескольких лет без изменений, и Microsoft продолжит оставаться важнейшим долгосрочным партнёром компании. Microsoft при этом в своей отчётности добавила OpenAI к числу собственных конкурентов в 2024 году. С прошлого года OpenAI начала активнее сотрудничать с прочими облачными провайдерами, помимо Microsoft. OpenAI отметила и свою зависимость от поставщиков аппаратных решений, включая TSMC, AMD, Nvidia и Broadcom. В декабре прошлого года OpenAI сообщила, что до 2030 года собирается потратить около $665 млрд на развитие вычислительной инфраструктуры для ИИ. Риск для OpenAI представляют и возможные судебные претензии со стороны правообладателей, на данных которых стартап обучает свои большие языковые модели. Кроме того, компанию в суде преследуют родственники пользователей, которые подозревают ChatGPT в причастности к негативному влиянию на их ментальное здоровье и доведение до суицида. OpenAI поставила на рекламу: направлением займётся бывший топ-менеджер Meta✴
23.03.2026 [19:14],
Сергей Сурабекянц
OpenAI наняла Дэйва Дугана (Dave Dugan), бывшего вице-президента по глобальным клиентам и агентствам Meta✴✴, для укрепления связей с крупными рекламодателями и развития своего зарождающегося рекламного бизнеса. Дуган назначен вице-президентом по глобальным рекламным решениям в OpenAI. Он будет подчиняться операционному директору OpenAI Брэду Лайткэпу (Brad Lightcap). 
Источник изображения: unsplash.com Это громкое назначение подчёркивает стремление OpenAI к получению новых источников дохода для поддержки огромных финансовых потребностей в рамках масштабных проектов в области искусственного интеллекта. Ранее в этом году компания начала тестировать рекламу в своём популярном чат-боте ChatGPT, пока только для бесплатного и самого дешёвого тарифных планов. Хотя современный рекламный бизнес в значительной степени полагается на алгоритмы и автоматизированные системы для покупки и продажи рекламы, личные отношения остаются важным фактором, влияющим на то, куда бренды в конечном итоге тратят свои рекламные бюджеты. В лице Дугана OpenAI привлекает ветерана, известного своими тесными связями с ведущими мировыми рекламными компаниями. До Meta✴✴ Дуган работал в нескольких агентствах, принадлежащих таким рекламным гигантам, как Publicis Groupe. Отметим, что Фиджи Симо (Fidji Simo), который сейчас возглавляет продуктовые и бизнес-команды OpenAI в качестве генерального директора по приложениям, также ранее около десяти лет проработал в Meta✴✴. Выход на рынок цифровой рекламы знаменует собой значительный стратегический сдвиг для OpenAI. Глава компании Сэм Альтман (Sam Altman) ранее сомневался по поводу интеграции рекламы в ChatGPT, опасаясь потерять доверие пользователей. «Сочетание рекламы и ИИ вызывает у меня особое беспокойство, — заявил он на неформальной встрече в Гарвардском университете два года назад. — Я рассматриваю рекламу как крайнюю меру для нашей бизнес-модели». Похоже, что теперь подобные смутные сомнения его больше не мучают. Желая успокоить инвесторов перед IPO, OpenAI решила менее активно строить ЦОД
23.03.2026 [07:17],
Алексей Разин
Масштабы сделок по развитию вычислительной инфраструктуры для ИИ, которые начала в прошлом году заключать OpenAI, беспокоили инвесторов не самой надёжной схемой финансирования. Учитывая стремление компании выйти на IPO в текущем году, генеральному директору Сэму Альтману (Sam Altman) пришлось умерить свои амбиции в этой сфере. 
Источник изображения: OpenAI По словам представителей Futurum Group, на которых ссылается CNBC, руководство OpenAI пришло к осознанию факта, что фондовый рынок не может в полной мере одобрять прежний подход стартапа к безудержному расширению вычислительной инфраструктуры и гигантским расходам на её финансирование. В этом месяце Сэм Альтман на одной из конференций BlackRock признался в сложности массивного строительства центров обработки данных: «В таких масштабах очень много вещей идёт не по плану». Помимо природных катаклизмов, при строительстве ЦОД приходится сталкиваться с дефицитом компонентов и необходимостью строго выдерживать сроки. Аналитики считают, что на фоне подготовки к выходу на фондовый рынок OpenAI придётся сменить роль активного строителя ЦОД для собственных нужд на их арендатора. Кроме того, от ряда крупных проектов и амбиций придётся отказаться, поскольку не всех инвесторов устраивает нынешняя политика руководства стартапа, которая со стороны кажется бездумным расходованием средств. Темпы роста выручки должны оправдывать увеличение капитальных затрат, без этого добиться расположения инвесторов не удастся никакими увещеваниями. Ещё в ноябре Альтман признался, что OpenAI приходится отказываться от обучения новых ИИ-моделей и анонса новых функций из-за ограниченности в вычислительных ресурсах. Тогда он пояснил, что в ближайшие восемь лет OpenAI при поддержке партнёров рассчитывает ввести в строй вычислительные мощности на общую сумму $1,4 трлн. На тот момент выручка стартапа не превышала $13,1 млрд в год, поэтому столь серьёзное расхождение между расходами и доходами предсказуемо насторожило инвесторов. Даже Nvidia, которая в сентябре согласилась было направить на нужды OpenAI до $100 млрд, в этом году пересмотрела условия сделки, заметно сократив как горизонты инвестиций, так и сумму. В феврале OpenAI заявила инвесторам, что к 2030 году рассчитывает потратить только $600 млрд. Альтману пришлось уверять участников фондового рынка, что к 2030 году выручка компании будет измеряться сотнями миллиардов долларов США. При непосредственном участии нанятой в прошлом году директора по приложениям Фиджи Симо (Fidji Simo) стартап принялся сосредотачивать свои усилия на приоритетных направлениях развития, чтобы не распылять напрасно ресурсы. В этом месяце новая политика компании была доведена до сотрудников OpenAI на общем собрании. Как отмечает CNBC со ссылкой на осведомлённые источники, сейчас OpenAI не владеет центрами обработки данных, и они могут не появиться у неё в обозримом будущем. Вычислительные мощности вводятся в строй при участии крупных партнёров типа Oracle, AWS (Amazon) и Microsoft. В январе 2025 года при участии Дональда Трампа (Donald Trump) было объявлено о запуске масштабного проекта Stargate, который подразумевал инвестиции в сумме $500 млрд за последующие четыре года в строительство ЦОД для ИИ в США. В церемонии анонса этой инициативы приняли участие главы Oracle, SoftBank и OpenAI. Последняя должна была отвечать за эксплуатацию этих центров обработки данных, Oracle и Nvidia выступать в роли технологических партнёров, а японская SoftBank обеспечивать проект финансовыми ресурсами. В любом случае, сотрудничество с OpenAI уже вынудило SoftBank не только распродавать другие активы, но и привлекать заёмные средства, как и в случае с Oracle. 
Источник изображения: Nvidia От идеи строительства ЦОД своими силами OpenAI довольно быстро отказалась, столкнувшись с множественными трудностями, и свой крупнейший объект такого типа в Техасе она арендует у Oracle. Сотрудничество с Nvidia подразумевало, что во второй половине текущего года OpenAI введёт в строй первый гигаватт вычислительных мощностей на чипах первой компании. Эксперты подчёркивают, что на возведение ЦОД подобного масштаба потребуется от трёх до десяти лет. Процесс строительства и согласования таит множество неожиданностей. Иметь дело с ними OpenAI оказалась морально не готова, а потому предпочла положиться на партнёров в развитии профильной инфраструктуры. Так или иначе, Amazon договорилась с OpenAI о сотрудничестве на сумму $110 млрд. В рамках договорённости первая из компаний предоставит второй около 2 ГВт вычислительных мощностей на базе чипов Trainium собственной разработки. Nvidia вместо изначальных $100 млрд решила вложить в OpenAI только $30 млрд, причём основная часть этих средств вернётся к первой из компаний в счёт оплаты поставок ускорителей. OpenAI достанутся около 3 ГВт вычислительных мощностей для инференса и 2 ГВт мощностей для обучения ИИ-моделей, причём построены они будут на новейшей платформе Nvidia Vera Rubin. Генеральный директор Дженсен Хуанг (Jensen Huang) дал понять, что текущая сделка с OpenAI станет последней перед IPO. Эксперты Futurum Group поясняют, что высокие затраты OpenAI вынуждают инвесторов предъявлять к компании повышенные требования относительно планов и сроков по выходу на прибыльность, а потому каждый шаг стартапа даже до IPO тщательно ими отслеживается. OpenAI планирует удвоить штат ради укрепления корпоративных продаж ChatGPT
22.03.2026 [07:35],
Дмитрий Федоров
К концу 2026 года OpenAI готовит почти двукратное расширение штата. Параллельно стартап с оценкой капитализации в $730 млрд усиливает продажи корпоративным клиентам, расширяет офисные площади в Сан-Франциско и меняет продуктовые приоритеты, пытаясь сократить отставание от Anthropic и укрепить позиции в корпоративном сегменте, где Anthropic в последние месяцы наращивает преимущество, а также сдержать давление со стороны Google. 
Источник изображения: openai.com По данным источников, компания намерена увеличить численность сотрудников примерно с 4 500 до 8 000 человек к концу 2026 года. Новые сотрудники, как ожидается, будут наняты прежде всего в продуктовые, инженерные, исследовательские и коммерческие подразделения. Отдельный акцент компания делает на специалистах по техническому сопровождению внедрения. Их задача — помогать заказчикам быстрее интегрировать инструменты OpenAI в рабочие процессы и повышать прикладную отдачу от использования ИИ. Компания заключила новый договор аренды в Сан-Франциско, увеличив общий объём занимаемых площадей в городе до 92 903 м2. По словам источников, в 2026 году компания рассчитывает расти примерно на 12 сотрудников в день. Такой темп указывает на системное масштабирование, а не на донабор отдельных команд. Перестройка связана с ухудшением позиций OpenAI в корпоративных продажах. По данным финтех-компании Ramp с более чем 50 000 клиентов, компании, впервые закупающие решения на базе ИИ, выбирают Anthropic в 3 раза чаще, чем OpenAI. Год назад ситуация была обратной. В OpenAI с такой оценкой не согласны. Представитель компании заявил, что делать выводы о доле корпоративного рынка на основе данных платежей по банковским картам некорректно, поскольку крупные клиенты не оплачивают многомиллионные контракты картами и, вероятно, вообще не используют Ramp для таких платежей. В конце 2025 года генеральный директор OpenAI Сэм Альтман (Sam Altman), как сообщалось, объявил внутри компании о всеобщей мобилизации ресурсов и потребовал вернуть фокус на ключевой продукт — ChatGPT. В марте 2026 года руководитель прикладного бизнеса OpenAI Фиджи Симо (Fidji Simo) призвала сотрудников отказаться от второстепенных задач и сосредоточиться на трёх направлениях: развитии Codex, расширении корпоративной клиентской базы и превращении ChatGPT в полноценный инструмент продуктивной работы. 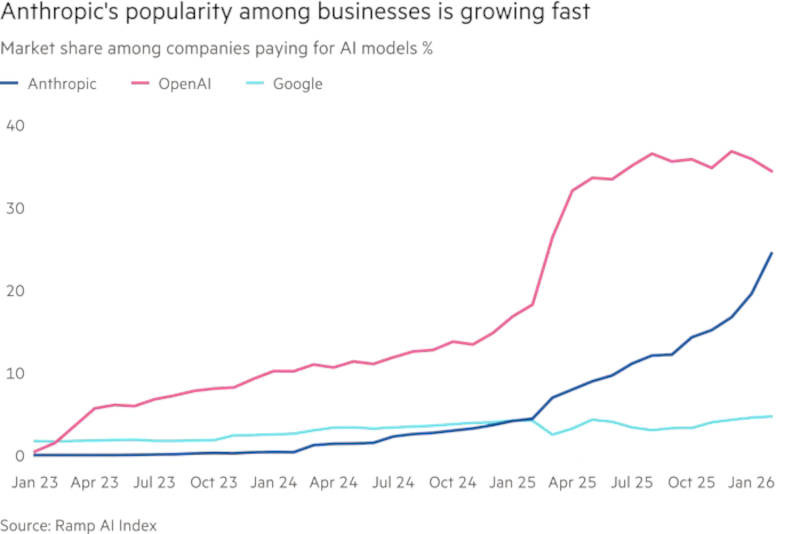
Anthropic быстро наращивает долю в корпоративном ИИ. Источник изображения: ramp.com Симо также курирует объединение Codex и ChatGPT в единое настольное приложение, которое планируется продавать как частным пользователям, так и компаниям. Параллельно OpenAI обсуждает с инвестиционными фондами создание совместного предприятия для внедрения своих продуктов в портфельных компаниях этих фондов. Для компании это способ быстрее расширить присутствие в корпоративной среде. ChatGPT остаётся самым успешным массовым приложением в сфере генеративного ИИ с момента запуска в 2023 году. При этом более 90 % из не менее чем 900 млн пользователей, регулярно взаимодействующих с сервисом, не платят OpenAI. Компания располагает огромной аудиторией, но значительная её часть не формирует выручку. Поэтому OpenAI одновременно ищет способы монетизации массовой базы, включая рекламу, и усиливает корпоративные продажи, где контракты крупнее и выручка устойчивее. Anthropic с самого начала выбрала более узкую стратегию. Основанная в 2021 году бывшими исследователями OpenAI, компания сделала ставку прежде всего на корпоративных заказчиков. После запуска Claude Code эта стратегия, по данным источников, начала приносить особенно быстрый результат: в 2026 году Anthropic еженедельно увеличивала годовой темп выручки на $1 млрд. Это один из факторов, заставивших OpenAI ускорить пересмотр приоритетов. При этом ни OpenAI, ни Anthropic пока не вышли на прибыльность. Обе компании тратят на обучение ИИ-моделей на миллиарды долларов больше, чем зарабатывают. На этом фоне для них критически важно одновременно удерживать технологический темп, сокращать издержки, наращивать выручку и приближаться к прибыли, особенно с учётом возможной подготовки к публичному размещению акций (IPO) уже в 2026 году. 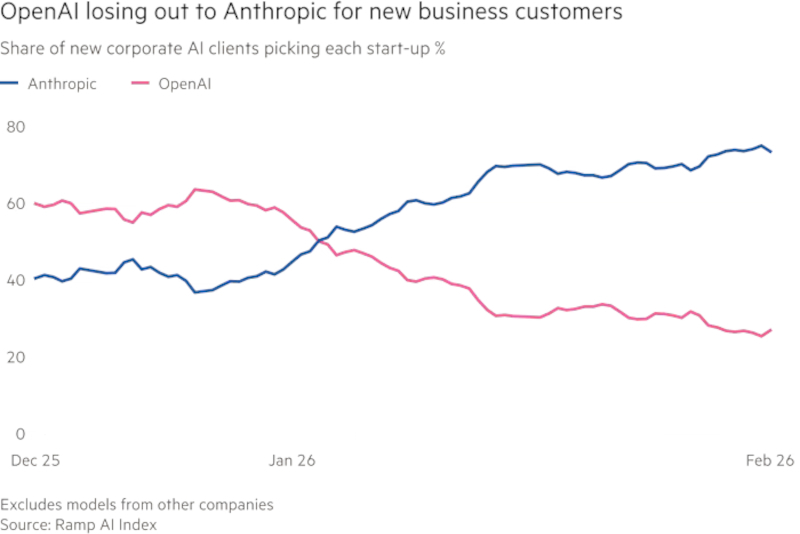
Anthropic опережает OpenAI у новых корпоративных клиентов. Источник изображения: ramp.com Следствием этого стало и быстрое распространение практики найма инженеров, работающих непосредственно у заказчика. Такие специалисты помогают адаптировать ИИ-модели, настраивать интеграции и ускорять внедрение. Подход, который раньше активно использовала Palantir, становится одним из стандартов рынка генеративного ИИ. OpenAI рассчитывает, что к концу 2026 года около 50 % её выручки будет приходиться на корпоративных клиентов против примерно 40 % сейчас. Это означает, что корпоративный сегмент становится опорной частью её финансовой модели. Внутри OpenAI новый акцент связывают прежде всего с успехом инструментов для программирования, таких как Claude Code и Codex. По словам одного из руководителей компании, именно эти продукты открыли для бизнеса новые направления роста и заставили OpenAI изменить представление о том, как строить продуктовую линейку и работать с рынком. Риск этой стратегии в том, что OpenAI приходится одновременно догонять Anthropic в корпоративном сегменте и удерживать позиции в массовом рынке, где с высокой интенсивностью конкурирует Google. Именно поэтому нынешнее расширение штата, рост офисных площадей и смещение продуктового фокуса следует рассматривать не как обычный этап развития, а как попытку заново определить место компании на быстро меняющемся рынке. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






